 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ_0$-WM: A Unified Video-Action World Model for Robotic Manipulation
May 31, 2026Robotic manipulation requires models that generate executable actions while anticipating and evaluating their future consequences before physical execution. We present $τ_0$-World Model ($τ_0$-WM), a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework. Built on a shared video diffusion backbone, $τ_0$-WM provides two complementary interfaces. First, a video action model jointly predicts future visual latents and continuous action chunks from multi-view observations, language instructions, and robot state. Second, an action-conditioned video simulator rolls out candidate action chunks into multi-view futures and predicts dense task-progress scores. The model is trained on approximately $27{,}300$ hours of real-robot teleoperation, UMI-style interaction, egocentric human videos, and rollout or failure trajectories using modality-specific supervision masks. At inference time, $τ_0$-WM uses test-time computation to sample action candidates, rank them with re-denoising consistency, and invoke simulator-based rectification for low-quality candidates. On challenging long-horizon and fine-grained robotic manipulation tasks, $τ_0$-WM shows superior performance over other relevant baselines.
EgoSound: Benchmarking Sound Understanding in Egocentric Videos
Feb 15, 2026Multimodal Large Language Models (MLLMs) have recently achieved remarkable progress in vision-language understanding. Yet, human perception is inherently multisensory, integrating sight, sound, and motion to reason about the world. Among these modalities, sound provides indispensable cues about spatial layout, off-screen events, and causal interactions, particularly in egocentric settings where auditory and visual signals are tightly coupled. To this end, we introduce EgoSound, the first benchmark designed to systematically evaluate egocentric sound understanding in MLLMs. EgoSound unifies data from Ego4D and EgoBlind, encompassing both sighted and sound-dependent experiences. It defines a seven-task taxonomy spanning intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning. Constructed through a multi-stage auto-generative pipeline, EgoSound contains 7315 validated QA pairs across 900 videos. Comprehensive experiments on nine state-of-the-art MLLMs reveal that current models exhibit emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding. EgoSound establishes a challenging foundation for advancing multisensory egocentric intelligence, bridging the gap between seeing and truly hearing the world.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025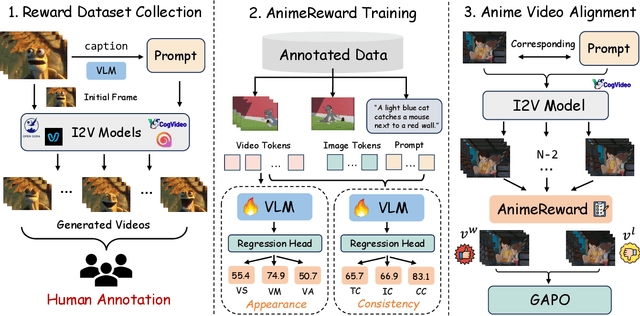

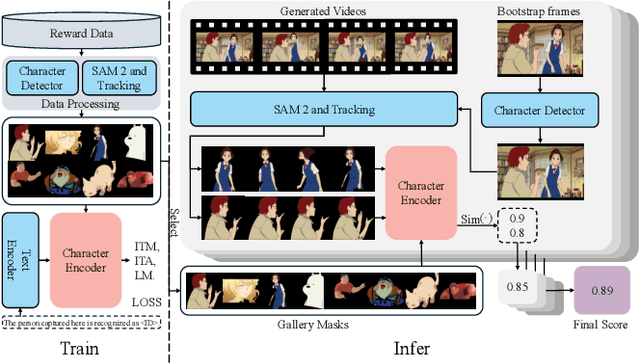
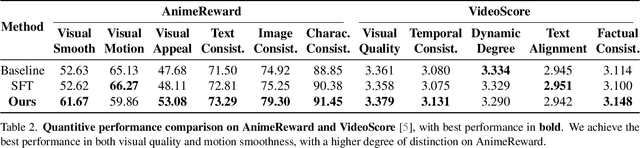
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
PoseAnimate: Zero-shot high fidelity pose controllable character animation
Apr 30, 2024
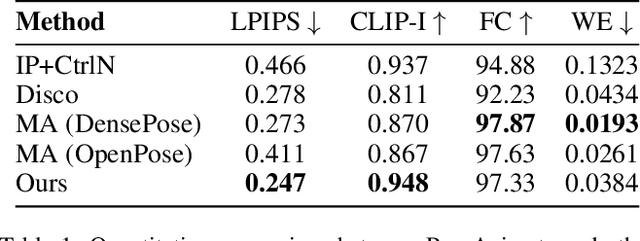
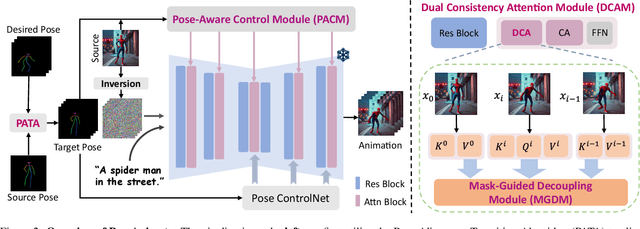
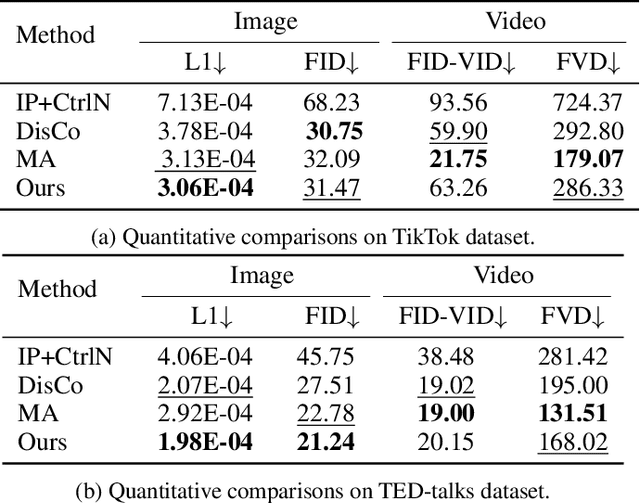
Image-to-video(I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity with the source image.However, existing approaches suffer from character appearance inconsistency and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding.To address these limitations,we propose PoseAnimate, a novel zero-shot I2V framework for character animation.PoseAnimate contains three key components: 1) Pose-Aware Control Module (PACM) incorporates diverse pose signals into conditional embeddings, to preserve character-independent content and maintain precise alignment of actions.2) Dual Consistency Attention Module (DCAM) enhances temporal consistency, and retains character identity and intricate background details.3) Mask-Guided Decoupling Module (MGDM) refines distinct feature perception, improving animation fidelity by decoupling the character and background.We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition.Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.