 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkingVLA: Interleaved Vision and Language Reasoning for Robotic Manipulation
Jun 16, 2026Most Vision-Language-Action (VLA) models map observations directly to actions without explicit reasoning, limiting their capacity for reasoning-intensive long-horizon tasks. To address this, existing approaches adopt Chain-of-Thought (CoT) reasoning to enable subgoal decomposition and spatial anticipation. However, those methods lack a unified architecture for effective cross-modal reasoning and fail to explicitly include inverse reasoning ability based on the target state. We argue that manipulation planning naturally decomposes into prediction, anticipating the next visual state, and inverse dynamics, inferring the actions to reach it. Bridging both requires a unified autoregressive architecture that interleaves textual and visual reasoning in a single generation process. We propose \textbf{ThinkingVLA}, a generative model that realizes this decomposition within a unified Mixture-of-Transformers architecture. ThinkingVLA consists of a forward CoT that identifies the immediate subgoal and guides the visual forecasting; the predicted image then serves as the target state, grounding an inverse CoT that reasons about spatial relationships and action intent based on the predicted image; and the final action is generated conditioned on this full reasoning context. Extensive experiments on simulation and real-world benchmarks demonstrate that ThinkingVLA consistently outperforms state-of-the-art baselines, with particularly large gains on long-horizon manipulation tasks.
ActiveMimic: Egocentric Video Pretraining with Active Perception
Jun 04, 2026Egocentric human video offers a scalable alternative to robot data for pretraining, yet models pretrained on such video consistently underperform those pretrained on robot data. We attribute this gap to a missing signal, the active perception behavior in egocentric videos, where humans continuously reposition their viewpoint during manipulation, inducing camera motion that standard pipelines treat as noise. To address this, we present ActiveMimic, a pretraining framework that recovers synchronized camera and wrist trajectories from a single body-worn RGB camera, models camera motion as a viewpoint action, and jointly learns active perception and manipulation from in-the-wild egocentric human video before adapting to a target robot. Empirically, real-world experiments across tasks with diverse active perception demands show that ActiveMimic consistently surpasses baselines pretrained on human video and matches state-of-the-art models pretrained on robot data. Further analysis provides evidence that active perception capability originates from egocentric human video pretraining rather than robot-specific fine-tuning, confirming active perception as the key to unlocking egocentric human video for robot pretraining.
Dual-Path Hyperprior Informed Deep Unfolding Network for Image Compressive Sensing
May 10, 2026Recent Deep Unfolding Networks (DUNs) have significantly advanced Compressive Sensing (CS) by integrating iterative optimization with deep networks. However, existing DUNs still suffer from two challenges: 1) Reliance on a single measurement stream, which limits effective information interaction across distinct measurement subsets. 2) Uniform processing of all image regions, which overlooks varying reconstruction difficulties induced by diverse textures. To address these limitations, a novel Dual-Path Hyperprior Informed Deep Unfolding Network (DPH-DUN) is proposed, which partitions measurements into double subsets to enable hyperprior-guided reconstruction via a dual-path architecture. In the Deep Hyperprior Learning branch, a series of lightweight neural modules are designed to efficiently generate hyperprior knowledge of different domains, enabling collaborative guidance for the CS reconstruction. In the Hyperprior Informed Reconstruction branch, a deep unfolding framework with hyperprior guidance is constructed to iteratively refine reconstruction. Specifically, i) in the gradient descent step, a Hyperprior Informed Step Size Generation network is designed to dynamically generate spatially varying step maps, enabling adaptive fine-grained gradient updates. ii) In the proximal mapping step, two well-designed hyperprior informed attention mechanisms are introduced to dynamically focus on challenging regions via gradient-based hard and soft attentions, facilitating CS reconstruction accuracy. Extensive experiments demonstrate that the proposed DPH-DUN outperforms existing CS methods.
Ask-to-Clarify: Resolving Instruction Ambiguity through Multi-turn Dialogue
Sep 18, 2025The ultimate goal of embodied agents is to create collaborators that can interact with humans, not mere executors that passively follow instructions. This requires agents to communicate, coordinate, and adapt their actions based on human feedback. Recently, advances in VLAs have offered a path toward this goal. However, most current VLA-based embodied agents operate in a one-way mode: they receive an instruction and execute it without feedback. This approach fails in real-world scenarios where instructions are often ambiguous. In this paper, we address this problem with the Ask-to-Clarify framework. Our framework first resolves ambiguous instructions by asking questions in a multi-turn dialogue. Then it generates low-level actions end-to-end. Specifically, the Ask-to-Clarify framework consists of two components, one VLM for collaboration and one diffusion for action. We also introduce a connection module that generates conditions for the diffusion based on the output of the VLM. This module adjusts the observation by instructions to create reliable conditions. We train our framework with a two-stage knowledge-insulation strategy. First, we fine-tune the collaboration component using ambiguity-solving dialogue data to handle ambiguity. Then, we integrate the action component while freezing the collaboration one. This preserves the interaction abilities while fine-tuning the diffusion to generate actions. The training strategy guarantees our framework can first ask questions, then generate actions. During inference, a signal detector functions as a router that helps our framework switch between asking questions and taking actions. We evaluate the Ask-to-Clarify framework in 8 real-world tasks, where it outperforms existing state-of-the-art VLAs. The results suggest that our proposed framework, along with the training strategy, provides a path toward collaborative embodied agents.
PoseAnimate: Zero-shot high fidelity pose controllable character animation
Apr 30, 2024
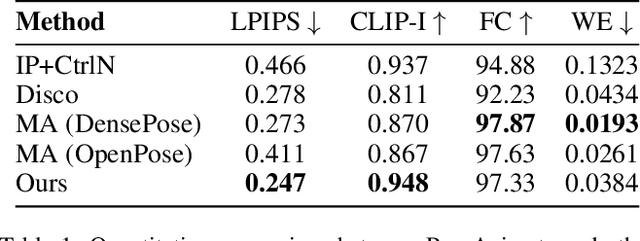
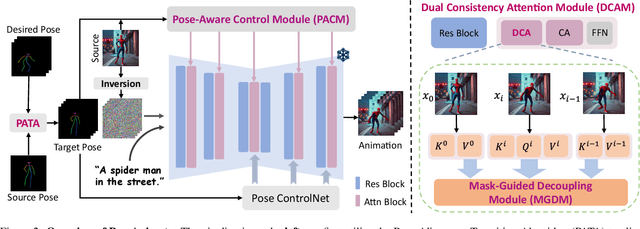
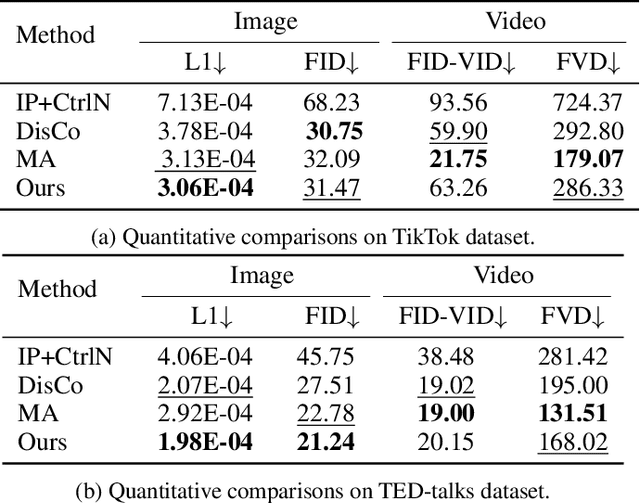
Image-to-video(I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity with the source image.However, existing approaches suffer from character appearance inconsistency and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding.To address these limitations,we propose PoseAnimate, a novel zero-shot I2V framework for character animation.PoseAnimate contains three key components: 1) Pose-Aware Control Module (PACM) incorporates diverse pose signals into conditional embeddings, to preserve character-independent content and maintain precise alignment of actions.2) Dual Consistency Attention Module (DCAM) enhances temporal consistency, and retains character identity and intricate background details.3) Mask-Guided Decoupling Module (MGDM) refines distinct feature perception, improving animation fidelity by decoupling the character and background.We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition.Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model
Dec 01, 2023Identity-consistent video generation seeks to synthesize videos that are guided by both textual prompts and reference images of entities. Current approaches typically utilize cross-attention layers to integrate the appearance of the entity, which predominantly captures semantic attributes, resulting in compromised fidelity of entities. Moreover, these methods necessitate iterative fine-tuning for each new entity encountered, thereby limiting their applicability. To address these challenges, we introduce VideoAssembler, a novel end-to-end framework for identity-consistent video generation that can conduct inference directly when encountering new entities. VideoAssembler is adept at producing videos that are not only flexible with respect to the input reference entities but also responsive to textual conditions. Additionally, by modulating the quantity of input images for the entity, VideoAssembler enables the execution of tasks ranging from image-to-video generation to sophisticated video editing. VideoAssembler comprises two principal components: the Reference Entity Pyramid (REP) encoder and the Entity-Prompt Attention Fusion (EPAF) module. The REP encoder is designed to infuse comprehensive appearance details into the denoising stages of the stable diffusion model. Concurrently, the EPAF module is utilized to integrate text-aligned features effectively. Furthermore, to mitigate the challenge of scarce data, we present a methodology for the preprocessing of training data. Our evaluation of the VideoAssembler framework on the UCF-101, MSR-VTT, and DAVIS datasets indicates that it achieves good performances in both quantitative and qualitative analyses (346.84 in FVD and 48.01 in IS on UCF-101). Our project page is at https://gulucaptain.github.io/videoassembler/.
Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models
Oct 25, 2023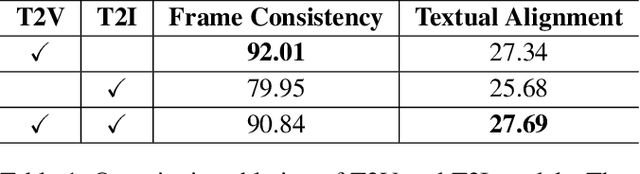
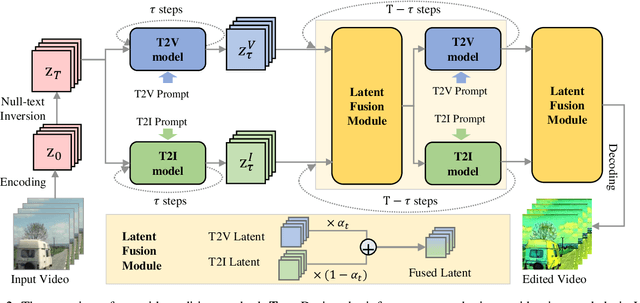


Latent Diffusion Models (LDMs) are renowned for their powerful capabilities in image and video synthesis. Yet, video editing methods suffer from insufficient pre-training data or video-by-video re-training cost. In addressing this gap, we propose FLDM (Fused Latent Diffusion Model), a training-free framework to achieve text-guided video editing by applying off-the-shelf image editing methods in video LDMs. Specifically, FLDM fuses latents from an image LDM and an video LDM during the denoising process. In this way, temporal consistency can be kept with video LDM while high-fidelity from the image LDM can also be exploited. Meanwhile, FLDM possesses high flexibility since both image LDM and video LDM can be replaced so advanced image editing methods such as InstructPix2Pix and ControlNet can be exploited. To the best of our knowledge, FLDM is the first method to adapt off-the-shelf image editing methods into video LDMs for video editing. Extensive quantitative and qualitative experiments demonstrate that FLDM can improve the textual alignment and temporal consistency of edited videos.
Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation
Sep 07, 2023



Inspired by the remarkable success of Latent Diffusion Models (LDMs) for image synthesis, we study LDM for text-to-video generation, which is a formidable challenge due to the computational and memory constraints during both model training and inference. A single LDM is usually only capable of generating a very limited number of video frames. Some existing works focus on separate prediction models for generating more video frames, which suffer from additional training cost and frame-level jittering, however. In this paper, we propose a framework called "Reuse and Diffuse" dubbed $\textit{VidRD}$ to produce more frames following the frames already generated by an LDM. Conditioned on an initial video clip with a small number of frames, additional frames are iteratively generated by reusing the original latent features and following the previous diffusion process. Besides, for the autoencoder used for translation between pixel space and latent space, we inject temporal layers into its decoder and fine-tune these layers for higher temporal consistency. We also propose a set of strategies for composing video-text data that involve diverse content from multiple existing datasets including video datasets for action recognition and image-text datasets. Extensive experiments show that our method achieves good results in both quantitative and qualitative evaluations. Our project page is available $\href{https://anonymous0x233.github.io/ReuseAndDiffuse/}{here}$.
aw_nas: A Modularized and Extensible NAS framework
Nov 25, 2020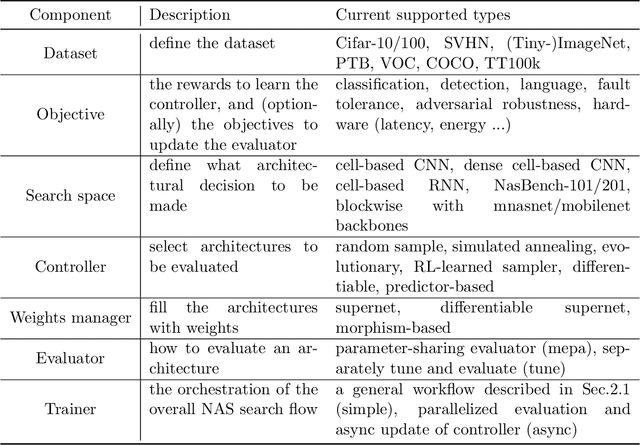
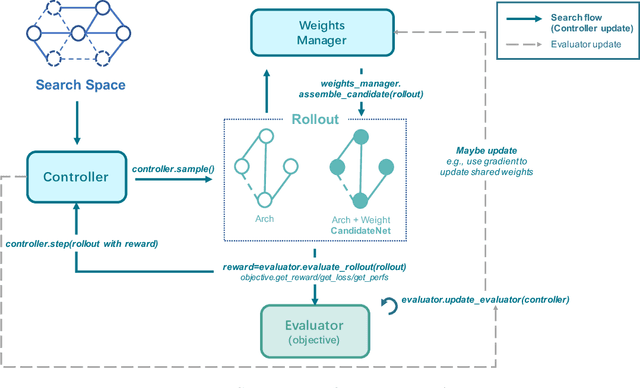

Neural Architecture Search (NAS) has received extensive attention due to its capability to discover neural network architectures in an automated manner. aw_nas is an open-source Python framework implementing various NAS algorithms in a modularized manner. Currently, aw_nas can be used to reproduce the results of mainstream NAS algorithms of various types. Also, due to the modularized design, one can simply experiment with different NAS algorithms for various applications with awnas (e.g., classification, detection, text modeling, fault tolerance, adversarial robustness, hardware efficiency, and etc.). Codes and documentation are available at https://github.com/walkerning/aw_nas.