 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotCrop$^3$: Cropping Human-Centric Images into Cinematic Triple-Shot Compositions
Jun 04, 2026Prior work on aesthetic composition typically produces a single aesthetically pleasing crop, overlooking the narrative value of composing multiple shots from one scene. In practice, multi-shot composition is critical for downstream creative workflows: commercial posters often require multiple crops with different emphases (e.g., context, subject, and emotion/product details) to present key story beats. Therefore, we propose \textbf{Triple-Shot Compositions (TSC)}, a composition task that generates a three-shot set -- establishing, medium, and close-up -- from a single human-centric image, each paired with a brief shot description to support visual narration. To learn TSC with limited expert annotations, we introduce \textbf{ShotCrop} which undergoes a three-stage training process: it first applies Chain-of-Thought supervised fine-tuning to establish basic reasoning and aesthetic shot-cropping skills, then performs semi-supervised fine-tuning with high-confidence pseudo labels to further enhance aesthetic capability, and is finally optimized with Group Relative Policy Optimization for \textbf{ShotCrop} (GRPO-S) using a composite reward tailored for it. Specifically, our pseudo-labeling strategy combines MLLM-based scoring, aesthetic assessment, and CLIP similarity to retain high-confidence training signals. In addition, we present TSC-Bench, a benchmark of 1.2k expert-annotated test cases. Notably, ShotCrop achieves an average improvement of \textbf{2.82} times over GPT-5 in shot localization accuracy.
Fast Image Super-Resolution via Consistency Rectified Flow
May 12, 2026Diffusion models (DMs) have demonstrated remarkable success in real-world image super-resolution (SR), yet their reliance on time-consuming multi-step sampling largely hinders their practical applications. While recent efforts have introduced few- or single-step solutions, existing methods either inefficiently model the process from noisy input or fail to fully exploit iterative generative priors, compromising the fidelity and quality of the reconstructed images. To address this issue, we propose FlowSR, a novel approach that reformulates the SR problem as a rectified flow from low-resolution (LR) to high-resolution (HR) images. Our method leverages an improved consistency learning strategy to enable high-quality SR in a single step. Specifically, we refine the original consistency distillation process by incorporating HR regularization, ensuring that the learned SR flow not only enforces self-consistency but also converges precisely to the ground-truth HR target. Furthermore, we introduce a fast-slow scheduling strategy, where adjacent timesteps for consistency learning are sampled from two distinct schedulers: a fast scheduler with fewer timesteps to improve efficiency, and a slow scheduler with more timesteps to capture fine-grained texture details. Extensive experiments demonstrate that FlowSR achieves outstanding performance in both efficiency and image quality.
G$^2$TR: Generation-Guided Visual Token Reduction for Separate-Encoder Unified Multimodal Models
May 12, 2026The development of separate-encoder Unified multimodal models (UMMs) comes with a rapidly growing inference cost due to dense visual token processing. In this paper, we focus on understanding-side visual token reduction for improving the efficiency of separate-encoder UMMs. While this topic has been widely studied for MLLMs, existing methods typically rely on attention scores, text-image similarity and so on, implicitly assuming that the final objective is discriminative reasoning. This assumption does not hold for UMMs, where understanding-side visual tokens must also preserve the model's capabilities for editing images. We propose G$^2$TR, a generation-guided visual token reduction framework for separate-encoder UMMs. Our key insight is that the generation branch provides a task-agnostic signal for identifying understanding-side visual tokens that are not only semantically relevant but also important for latent-space image reconstruction and generation. G$^2$TR estimates token importance from consistency with VAE latent, performs balanced token selection, and merges redundant tokens into retained representatives to reduce information loss. The method is training-free, plug-and-play, and applied only after the understanding encoding stage, making it compatible with existing UMM inference pipelines. Experiments on image understanding and editing benchmarks show that G$^2$TR substantially reduces visual tokens and prefill computation by 1.94x while maintaining both reasoning accuracy and editing quality, outperforming baselines on almost all benchmarks.
PermuQuant: Lowering Per-Group Quantization Error by Reordering Channels for Diffusion Models
May 10, 2026Large-scale visual generative models have achieved remarkable performance. However, their high computational and memory costs make deployment challenging in resource-constrained scenarios, such as interactive applications and personal single-GPU usage. Post-training quantization (PTQ) offers a practical solution by compressing pretrained models without expensive retraining. However, existing PTQ methods still suffer from severe quality degradation under extremely low-bit settings. In this paper, we identify channel ordering as an important but underexplored factor in per-group quantization. In this setting, each contiguous group shares one quantization scale. When channels with very different statistics are placed in the same group, the scale can be dominated by outliers and cause large quantization errors. Based on this observation, we propose PermuQuant, a simple and effective PTQ framework for low-bit diffusion models. PermuQuant sorts channels by a joint second-moment criterion before per-group quantization, placing channels with similar activation and weight statistics into the same group. It further uses a calibration-based acceptance rule to apply reordering only when the selected permutation reduces quantization error on calibration data. The selected permutations are absorbed into adjacent modules or applied to weights offline, avoiding explicit runtime permutation operations. Extensive experiments on multiple large diffusion models show that PermuQuant consistently reduces quantization error and outperforms existing PTQ baselines. On FLUX.1-dev with an RTX 5090, PermuQuant achieves up to a 1.8$\times$ single step speedup and reduces the DiT memory footprint by 3.5$\times$ under W4A4 NVFP4 quantization. Code will be available at https://github.com/yscheng04/PermuQuant.
HP-Edit: A Human-Preference Post-Training Framework for Image Editing
Apr 21, 2026Common image editing tasks typically adopt powerful generative diffusion models as the leading paradigm for real-world content editing. Meanwhile, although reinforcement learning (RL) methods such as Diffusion-DPO and Flow-GRPO have further improved generation quality, efficiently applying Reinforcement Learning from Human Feedback (RLHF) to diffusion-based editing remains largely unexplored, due to a lack of scalable human-preference datasets and frameworks tailored to diverse editing needs. To fill this gap, we propose HP-Edit, a post-training framework for Human Preference-aligned Editing, and introduce RealPref-50K, a real-world dataset across eight common tasks and balancing common object editing. Specifically, HP-Edit leverages a small amount of human-preference scoring data and a pretrained visual large language model (VLM) to develop HP-Scorer--an automatic, human preference-aligned evaluator. We then use HP-Scorer both to efficiently build a scalable preference dataset and to serve as the reward function for post-training the editing model. We also introduce RealPref-Bench, a benchmark for evaluating real-world editing performance. Extensive experiments demonstrate that our approach significantly enhances models such as Qwen-Image-Edit-2509, aligning their outputs more closely with human preference.
GS-STVSR: Ultra-Efficient Continuous Spatio-Temporal Video Super-Resolution via 2D Gaussian Splatting
Apr 20, 2026Continuous Spatio-Temporal Video Super-Resolution (C-STVSR) aims to simultaneously enhance the spatial resolution and frame rate of videos by arbitrary scale factors, offering greater flexibility than fixed-scale methods that are constrained by predefined upsampling ratios. In recent years, methods based on Implicit Neural Representations (INR) have made significant progress in C-STVSR by learning continuous mappings from spatio-temporal coordinates to pixel values. However, these methods fundamentally rely on dense pixel-wise grid queries, causing computational cost to scale linearly with the number of interpolated frames and severely limiting inference efficiency. We propose GS-STVSR, an ultra-efficient C-STVSR framework based on 2D Gaussian Splatting (2D-GS) that drives the spatiotemporal evolution of Gaussian kernels through continuous motion modeling, bypassing dense grid queries entirely. We exploit the strong temporal stability of covariance parameters for lightweight intermediate fitting, design an optical flow-guided motion module to derive Gaussian position and color at arbitrary time steps, introduce a Covariance resampling alignment module to prevent covariance drift, and propose an adaptive offset window for large-scale motion. Extensive experiments on Vid4, GoPro, and Adobe240 show that GS-STVSR achieves state-of-the-art quality across all benchmarks. Moreover, its inference time remains nearly constant at conventional temporal scales (X2--X8) and delivers over X3 speedup at extreme scales X32, demonstrating strong practical applicability.
ColorFLUX: A Structure-Color Decoupling Framework for Old Photo Colorization
Mar 30, 2026Old photos preserve invaluable historical memories, making their restoration and colorization highly desirable. While existing restoration models can address some degradation issues like denoising and scratch removal, they often struggle with accurate colorization. This limitation arises from the unique degradation inherent in old photos, such as faded brightness and altered color hues, which are different from modern photo distributions, creating a substantial domain gap during colorization. In this paper, we propose a novel old photo colorization framework based on the generative diffusion model FLUX. Our approach introduces a structure-color decoupling strategy that separates structure preservation from color restoration, enabling accurate colorization of old photos while maintaining structural consistency. We further enhance the model with a progressive Direct Preference Optimization (Pro-DPO) strategy, which allows the model to learn subtle color preferences through coarse-to-fine transitions in color augmentation. Additionally, we address the limitations of text-based prompts by introducing visual semantic prompts, which extract fine-grained semantic information directly from old photos, helping to eliminate the color bias inherent in old photos. Experimental results on both synthetic and real datasets demonstrate that our approach outperforms existing state-of-the-art colorization methods, including closed-source commercial models, producing high-quality and vivid colorization.
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
Feb 06, 2026Unified multimodal models (UMMs) have shown impressive capabilities in generating natural images and supporting multimodal reasoning. However, their potential in supporting computer-use planning tasks, which are closely related to our lives, remain underexplored. Image generation and editing in computer-use tasks require capabilities like spatial reasoning and procedural understanding, and it is still unknown whether UMMs have these capabilities to finish these tasks or not. Therefore, we propose PlanViz, a new benchmark designed to evaluate image generation and editing for computer-use tasks. To achieve the goal of our evaluation, we focus on sub-tasks which frequently involve in daily life and require planning steps. Specifically, three new sub-tasks are designed: route planning, work diagramming, and web&UI displaying. We address challenges in data quality ensuring by curating human-annotated questions and reference images, and a quality control process. For challenges of comprehensive and exact evaluation, a task-adaptive score, PlanScore, is proposed. The score helps understanding the correctness, visual quality and efficiency of generated images. Through experiments, we highlight key limitations and opportunities for future research on this topic.
UmniBench: Unified Understand and Generation Model Oriented Omni-dimensional Benchmark
Dec 19, 2025Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. However, evaluations of unified multimodal models (UMMs) remain decoupled, assessing their understanding and generation abilities separately with corresponding datasets. To address this, we propose UmniBench, a benchmark tailored for UMMs with omni-dimensional evaluation. First, UmniBench can assess the understanding, generation, and editing ability within a single evaluation process. Based on human-examined prompts and QA pairs, UmniBench leverages UMM itself to evaluate its generation and editing ability with its understanding ability. This simple but effective paradigm allows comprehensive evaluation of UMMs. Second, UmniBench covers 13 major domains and more than 200 concepts, ensuring a thorough inspection of UMMs. Moreover, UmniBench can also decouple and separately evaluate understanding, generation, and editing abilities, providing a fine-grained assessment. Based on UmniBench, we benchmark 24 popular models, including both UMMs and single-ability large models. We hope this benchmark provides a more comprehensive and objective view of unified models and logistical support for improving the performance of the community model.
PMQ-VE: Progressive Multi-Frame Quantization for Video Enhancement
May 18, 2025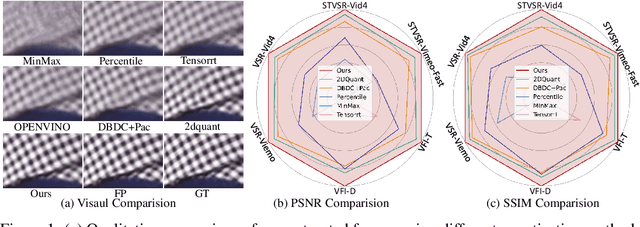
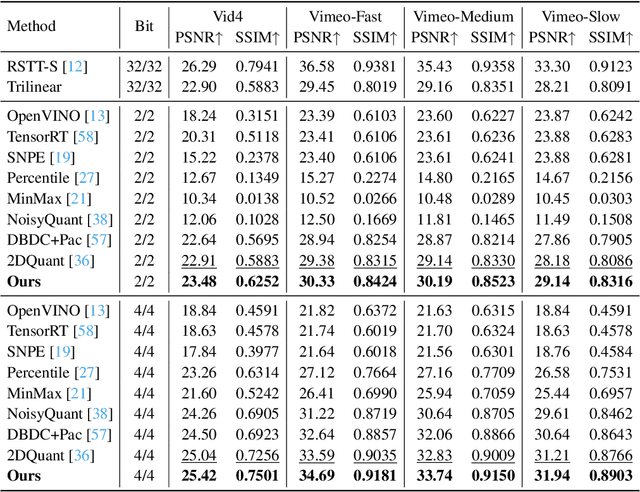
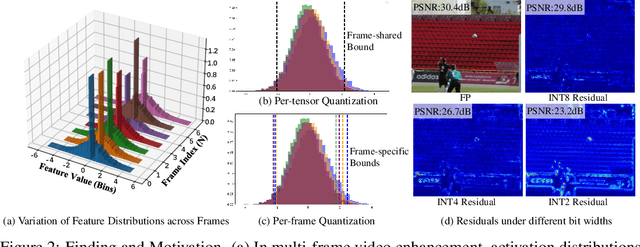
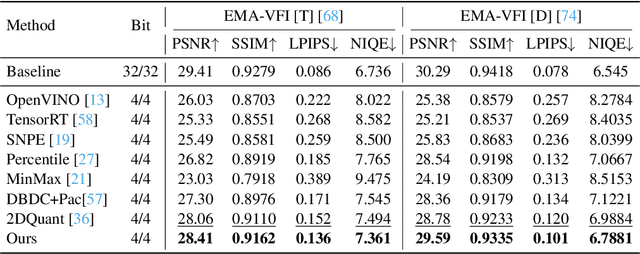
Multi-frame video enhancement tasks aim to improve the spatial and temporal resolution and quality of video sequences by leveraging temporal information from multiple frames, which are widely used in streaming video processing, surveillance, and generation. Although numerous Transformer-based enhancement methods have achieved impressive performance, their computational and memory demands hinder deployment on edge devices. Quantization offers a practical solution by reducing the bit-width of weights and activations to improve efficiency. However, directly applying existing quantization methods to video enhancement tasks often leads to significant performance degradation and loss of fine details. This stems from two limitations: (a) inability to allocate varying representational capacity across frames, which results in suboptimal dynamic range adaptation; (b) over-reliance on full-precision teachers, which limits the learning of low-bit student models. To tackle these challenges, we propose a novel quantization method for video enhancement: Progressive Multi-Frame Quantization for Video Enhancement (PMQ-VE). This framework features a coarse-to-fine two-stage process: Backtracking-based Multi-Frame Quantization (BMFQ) and Progressive Multi-Teacher Distillation (PMTD). BMFQ utilizes a percentile-based initialization and iterative search with pruning and backtracking for robust clipping bounds. PMTD employs a progressive distillation strategy with both full-precision and multiple high-bit (INT) teachers to enhance low-bit models' capacity and quality. Extensive experiments demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance across multiple tasks and benchmarks.The code will be made publicly available at: https://github.com/xiaoBIGfeng/PMQ-VE.