 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Self-Consistency:A Multi-Task Evaluation of LLMs on VirtualHome
Feb 03, 2026Embodied AI requires agents to understand goals, plan actions, and execute tasks in simulated environments. We present a comprehensive evaluation of Large Language Models (LLMs) on the VirtualHome benchmark using the Embodied Agent Interface (EAI) framework. We compare two representative 7B-parameter models OPENPANGU-7B and QWEN2.5-7B across four fundamental tasks: Goal Interpretation, Action Sequencing, Subgoal Decomposition, and Transition Modeling. We propose Structured Self-Consistency (SSC), an enhanced decoding strategy that leverages multiple sampling with domain-specific voting mechanisms to improve output quality for structured generation tasks. Experimental results demonstrate that SSC significantly enhances performance, with OPENPANGU-7B excelling at hierarchical planning while QWEN2.5-7B show advantages in action-level tasks. Our analysis reveals complementary strengths across model types, providing insights for future embodied AI system development.
Stepwise Think-Critique: A Unified Framework for Robust and Interpretable LLM Reasoning
Dec 17, 2025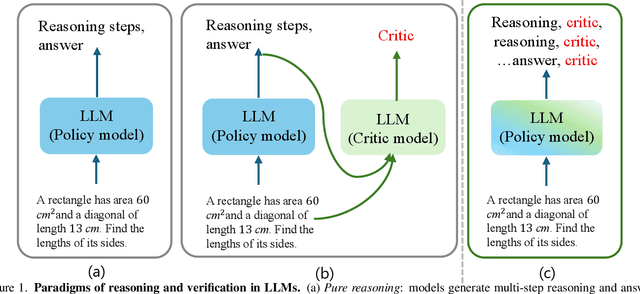


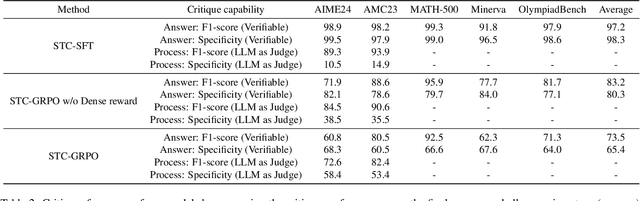
Human beings solve complex problems through critical thinking, where reasoning and evaluation are intertwined to converge toward correct solutions. However, most existing large language models (LLMs) decouple reasoning from verification: they either generate reasoning without explicit self-checking or rely on external verifiers to detect errors post hoc. The former lacks immediate feedback, while the latter increases system complexity and hinders synchronized learning. Motivated by human critical thinking, we propose Stepwise Think-Critique (STC), a unified framework that interleaves reasoning and self-critique at each step within a single model. STC is trained with a hybrid reinforcement learning objective combining reasoning rewards and critique-consistency rewards to jointly optimize reasoning quality and self-evaluation. Experiments on mathematical reasoning benchmarks show that STC demonstrates strong critic-thinking capabilities and produces more interpretable reasoning traces, representing a step toward LLMs with built-in critical thinking.
A Machine Learning-Based Multimodal Framework for Wearable Sensor-Based Archery Action Recognition and Stress Estimation
Nov 18, 2025In precision sports such as archery, athletes' performance depends on both biomechanical stability and psychological resilience. Traditional motion analysis systems are often expensive and intrusive, limiting their use in natural training environments. To address this limitation, we propose a machine learning-based multimodal framework that integrates wearable sensor data for simultaneous action recognition and stress estimation. Using a self-developed wrist-worn device equipped with an accelerometer and photoplethysmography (PPG) sensor, we collected synchronized motion and physiological data during real archery sessions. For motion recognition, we introduce a novel feature--Smoothed Differential Acceleration (SmoothDiff)--and employ a Long Short-Term Memory (LSTM) model to identify motion phases, achieving 96.8% accuracy and 95.9% F1-score. For stress estimation, we extract heart rate variability (HRV) features from PPG signals and apply a Multi-Layer Perceptron (MLP) classifier, achieving 80% accuracy in distinguishing high- and low-stress levels. The proposed framework demonstrates that integrating motion and physiological sensing can provide meaningful insights into athletes' technical and mental states. This approach offers a foundation for developing intelligent, real-time feedback systems for training optimization in archery and other precision sports.
Real-World Adverse Weather Image Restoration via Dual-Level Reinforcement Learning with High-Quality Cold Start
Nov 07, 2025Adverse weather severely impairs real-world visual perception, while existing vision models trained on synthetic data with fixed parameters struggle to generalize to complex degradations. To address this, we first construct HFLS-Weather, a physics-driven, high-fidelity dataset that simulates diverse weather phenomena, and then design a dual-level reinforcement learning framework initialized with HFLS-Weather for cold-start training. Within this framework, at the local level, weather-specific restoration models are refined through perturbation-driven image quality optimization, enabling reward-based learning without paired supervision; at the global level, a meta-controller dynamically orchestrates model selection and execution order according to scene degradation. This framework enables continuous adaptation to real-world conditions and achieves state-of-the-art performance across a wide range of adverse weather scenarios. Code is available at https://github.com/xxclfy/AgentRL-Real-Weather
Automated Classification of Tutors' Dialogue Acts Using Generative AI: A Case Study Using the CIMA Corpus
Sep 11, 2025



This study explores the use of generative AI for automating the classification of tutors' Dialogue Acts (DAs), aiming to reduce the time and effort required by traditional manual coding. This case study uses the open-source CIMA corpus, in which tutors' responses are pre-annotated into four DA categories. Both GPT-3.5-turbo and GPT-4 models were tested using tailored prompts. Results show that GPT-4 achieved 80% accuracy, a weighted F1-score of 0.81, and a Cohen's Kappa of 0.74, surpassing baseline performance and indicating substantial agreement with human annotations. These findings suggest that generative AI has strong potential to provide an efficient and accessible approach to DA classification, with meaningful implications for educational dialogue analysis. The study also highlights the importance of task-specific label definitions and contextual information in enhancing the quality of automated annotation. Finally, it underscores the ethical considerations associated with the use of generative AI and the need for responsible and transparent research practices. The script of this research is publicly available at https://github.com/liqunhe27/Generative-AI-for-educational-dialogue-act-tagging.
Dual Prompting Image Restoration with Diffusion Transformers
Apr 24, 2025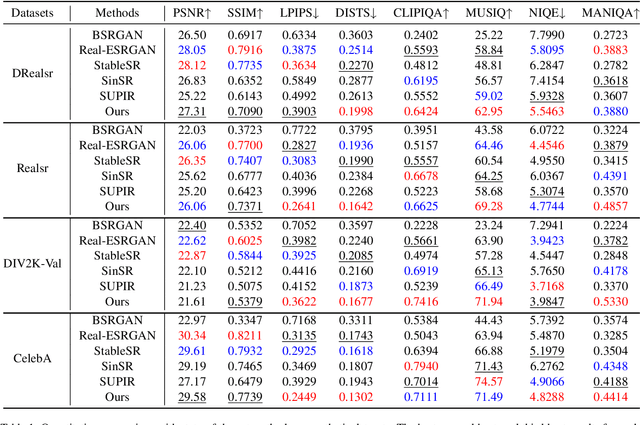
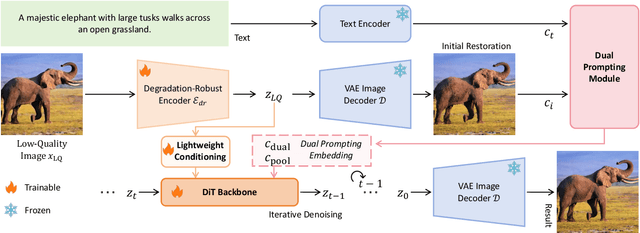
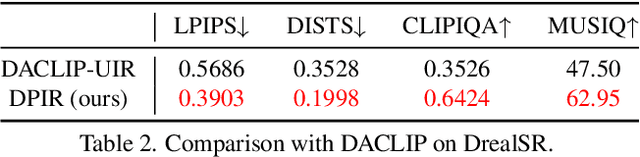
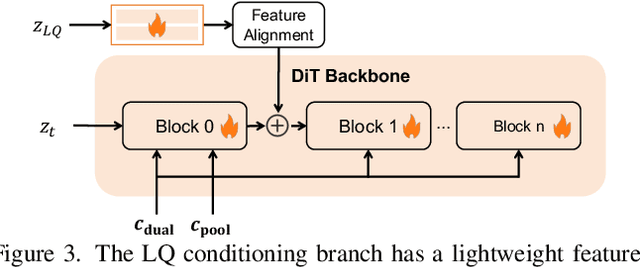
Recent state-of-the-art image restoration methods mostly adopt latent diffusion models with U-Net backbones, yet still facing challenges in achieving high-quality restoration due to their limited capabilities. Diffusion transformers (DiTs), like SD3, are emerging as a promising alternative because of their better quality with scalability. In this paper, we introduce DPIR (Dual Prompting Image Restoration), a novel image restoration method that effectivly extracts conditional information of low-quality images from multiple perspectives. Specifically, DPIR consits of two branches: a low-quality image conditioning branch and a dual prompting control branch. The first branch utilizes a lightweight module to incorporate image priors into the DiT with high efficiency. More importantly, we believe that in image restoration, textual description alone cannot fully capture its rich visual characteristics. Therefore, a dual prompting module is designed to provide DiT with additional visual cues, capturing both global context and local appearance. The extracted global-local visual prompts as extra conditional control, alongside textual prompts to form dual prompts, greatly enhance the quality of the restoration. Extensive experimental results demonstrate that DPIR delivers superior image restoration performance.
PsyCounAssist: A Full-Cycle AI-Powered Psychological Counseling Assistant System
Apr 23, 2025
Psychological counseling is a highly personalized and dynamic process that requires therapists to continuously monitor emotional changes, document session insights, and maintain therapeutic continuity. In this paper, we introduce PsyCounAssist, a comprehensive AI-powered counseling assistant system specifically designed to augment psychological counseling practices. PsyCounAssist integrates multimodal emotion recognition combining speech and photoplethysmography (PPG) signals for accurate real-time affective analysis, automated structured session reporting using large language models (LLMs), and personalized AI-generated follow-up support. Deployed on Android-based tablet devices, the system demonstrates practical applicability and flexibility in real-world counseling scenarios. Experimental evaluation confirms the reliability of PPG-based emotional classification and highlights the system's potential for non-intrusive, privacy-aware emotional support. PsyCounAssist represents a novel approach to ethically and effectively integrating AI into psychological counseling workflows.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025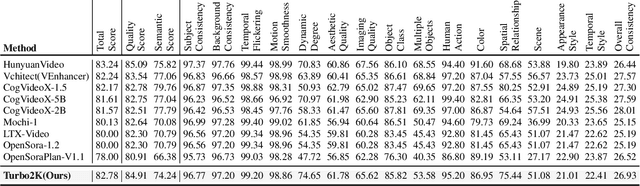

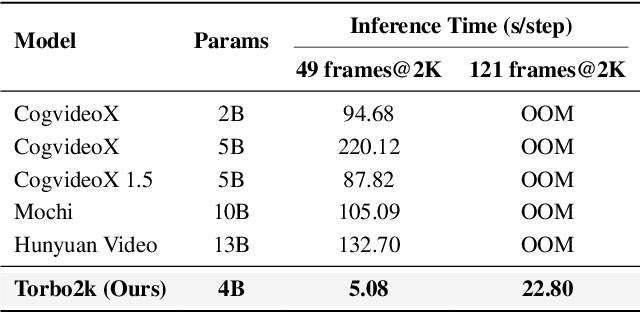

Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
MedHallTune: An Instruction-Tuning Benchmark for Mitigating Medical Hallucination in Vision-Language Models
Feb 28, 2025The increasing use of vision-language models (VLMs) in healthcare applications presents great challenges related to hallucinations, in which the models may generate seemingly plausible results that are in fact incorrect. Such hallucinations can jeopardize clinical decision making, potentially harming the diagnosis and treatments. In this work, we propose MedHallTune, a large-scale benchmark designed specifically to evaluate and mitigate hallucinations in medical VLMs. Comprising over 100,000 images and 1,000,000 instruction pairs, MedHallTune includes both hallucination and non-hallucination samples, each with ground-truth annotations. We conduct a comprehensive evaluation of current medical and general VLMs using MedHallTune, assessing their performance across key metrics, including clinical accuracy, relevance, detail level, and risk level. The experimental results show that fine-tuning with MedHallTune successfully improves the ability of several existing models to manage hallucinations and boost their zero-shot performance on downstream visual-question-answering (VQA) tasks, making them more reliable for practical medical applications. Our work contributes to the development of more trustworthy VLMs. Codes and dataset will be available at \href{https://github.com/russellyq/MedHallTune}{MedHallTune}.
CoMA: Compositional Human Motion Generation with Multi-modal Agents
Dec 10, 2024



3D human motion generation has seen substantial advancement in recent years. While state-of-the-art approaches have improved performance significantly, they still struggle with complex and detailed motions unseen in training data, largely due to the scarcity of motion datasets and the prohibitive cost of generating new training examples. To address these challenges, we introduce CoMA, an agent-based solution for complex human motion generation, editing, and comprehension. CoMA leverages multiple collaborative agents powered by large language and vision models, alongside a mask transformer-based motion generator featuring body part-specific encoders and codebooks for fine-grained control. Our framework enables generation of both short and long motion sequences with detailed instructions, text-guided motion editing, and self-correction for improved quality. Evaluations on the HumanML3D dataset demonstrate competitive performance against state-of-the-art methods. Additionally, we create a set of context-rich, compositional, and long text prompts, where user studies show our method significantly outperforms existing approaches.