 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxel-CKM: Voxelized Radio Frequency Radiance Fields for Fast and Few-Shot CKM Construction
Jun 02, 2026Channel knowledge maps (CKMs) are designed to predict channel state information (CSI) from user locations, thereby enabling low-overhead CSI acquisition. However, existing CKM construction methods often require hours-to-days of training time and dense measurements, resulting in substantial deployment cost. In this paper, we propose Voxel-CKM, a novel voxelized radio frequency (RF) radiance field framework for fast and few-shot CKM construction. The core idea is to replace implicit neural representations with explicit voxel grids to efficiently capture the spatial variation of wireless channels. Building upon this, we further introduce a compact vector-matrix (VM) decomposition to parameterize these voxel grids using a small set of matrices and vectors, which significantly accelerates convergence and facilitates fast CKM construction. To enable few-shot learning, we incorporate a transmitter prior as an inductive bias to guide the learning process under sparse measurements. Additionally, a total-variation (TV) regularization loss is proposed to mitigate overfitting and stabilize optimization. Experiments show that Voxel-CKM substantially accelerates training convergence and improves performance in the few-shot regime.
Joint Source-Channel-Check Coding with HARQ for Reliable Semantic Communications
Mar 25, 2026Semantic communication has emerged as a promising paradigm for improving transmission efficiency and task-level reliability, yet most existing reliability-enhancement approaches rely on retransmission strategies driven by semantic fidelity checking that require additional check codewords solely for retransmission triggering, thereby incurring substantial communication overhead. In this paper, we propose S3CHARQ, a Joint Source-Channel-Check Coding framework with hybrid automatic repeat request that fundamentally rethinks the role of check codewords in semantic communications. By integrating the check codeword into the JSCC process, S3CHARQ enables JS3C, allowing the check codeword to simultaneously support semantic fidelity verification and reconstruction enhancement. At the transmitter, a semantic fidelity-aware check encoder embeds auxiliary reconstruction information into the check codeword. At the receiver, the JSCC and check codewords are jointly decoded by a JS3C decoder, while the check codeword is additionally exploited for perceptual quality estimation. Moreover, because retransmission decisions are necessarily based on imperfect semantic quality estimation in the absence of ground-truth reconstruction, estimation errors are unavoidable and fundamentally limit the effectiveness of rule-based decision schemes. To overcome this limitation, we develop a reinforcement learning-based retransmission decision module that enables adaptive, sample-level retransmission decisions, effectively balancing recovery and refinement information under dynamic channel conditions. Experimental results demonstrate that compared with existing HARQ-based semantic communication systems, the proposed S3CHARQ framework achieves a 2.36 dB improvement in the 97th percentile PSNR, as well as a 37.45% reduction in outage probability.
Location-Agnostic Channel Knowledge Map Construction for Dynamic Scenes
Mar 10, 2026To alleviate the pilot and CSI-feedback burden in 6G, channel knowledge map (CKM) has emerged as a promising approach that predicts CSI solely from user locations. Nevertheless, accurate location information is rarely available in current systems. Moreover, the uncertainty inherent to highly dynamic scenes further degrades the performance of existing schemes that typically assume quasi-static scenarios. In this paper, we propose a novel framework named location-agnostic dynamic CKM (LAD-CKM). Specifically, LAD-CKM is constructed through dynamic radio frequency (RF) radiance field rendering, which takes instantaneous uplink CSI and partial downlink CSI as inputs. To enable effective rendering, a dedicated radiator representation network (RARE-Net) is designed to capture the spatial-spectral correlations within the inputs. Furthermore, an adaptive deformation module is devised to deform the uplink CSI-based queries of RARE-Net according to instantaneous channel dynamics, thereby enhancing CSI prediction accuracy under mobility. In addition, a novel synthetic channel dataset is created in outdoor dynamic scenes via ray-tracing. Simulation results demonstrate that LAD-CKM yields significant performance gains compared with existing baselines in terms of effective data rate.
Prediction-Powered Risk Monitoring of Deployed Models for Detecting Harmful Distribution Shifts
Feb 02, 2026We study the problem of monitoring model performance in dynamic environments where labeled data are limited. To this end, we propose prediction-powered risk monitoring (PPRM), a semi-supervised risk-monitoring approach based on prediction-powered inference (PPI). PPRM constructs anytime-valid lower bounds on the running risk by combining synthetic labels with a small set of true labels. Harmful shifts are detected via a threshold-based comparison with an upper bound on the nominal risk, satisfying assumption-free finite-sample guarantees in the probability of false alarm. We demonstrate the effectiveness of PPRM through extensive experiments on image classification, large language model (LLM), and telecommunications monitoring tasks.
F$^4$-CKM: Learning Channel Knowledge Map with Radio Frequency Radiance Field Rendering
Jan 07, 2026In 6G mobile communications, acquiring accurate and timely channel state information (CSI) becomes increasingly challenging due to the growing antenna array size and bandwidth. To alleviate the CSI feedback burden, the channel knowledge map (CKM) has emerged as a promising approach by leveraging environment-aware techniques to predict CSI based solely on user locations. However, how to effectively construct a CKM remains an open issue. In this paper, we propose F$^4$-CKM, a novel CKM construction framework characterized by four distinctive features: radiance Field rendering, spatial-Frequency-awareness, location-Free usage, and Fast learning. Central to our design is the adaptation of radiance field rendering techniques from computer vision to the radio frequency (RF) domain, enabled by a novel Wireless Radiator Representation (WiRARE) network that captures the spatial-frequency characteristics of wireless channels. Additionally, a novel shaping filter module and an angular sampling strategy are introduced to facilitate CKM construction. Extensive experiments demonstrate that F$^4$-CKM significantly outperforms existing baselines in terms of wireless channel prediction accuracy and efficiency.
Reliable LLM-Based Edge-Cloud-Expert Cascades for Telecom Knowledge Systems
Dec 23, 2025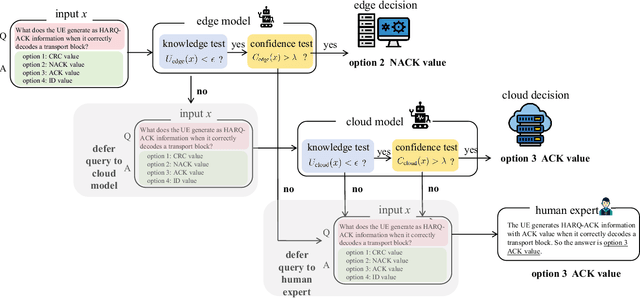
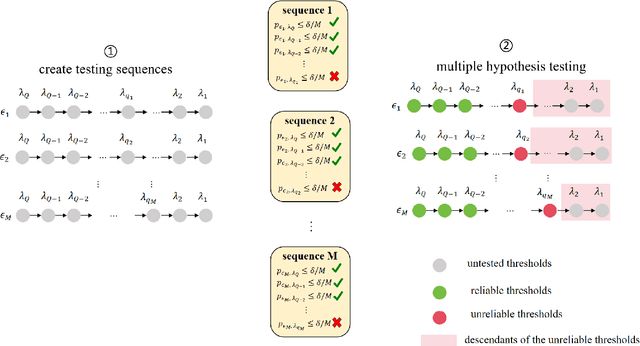
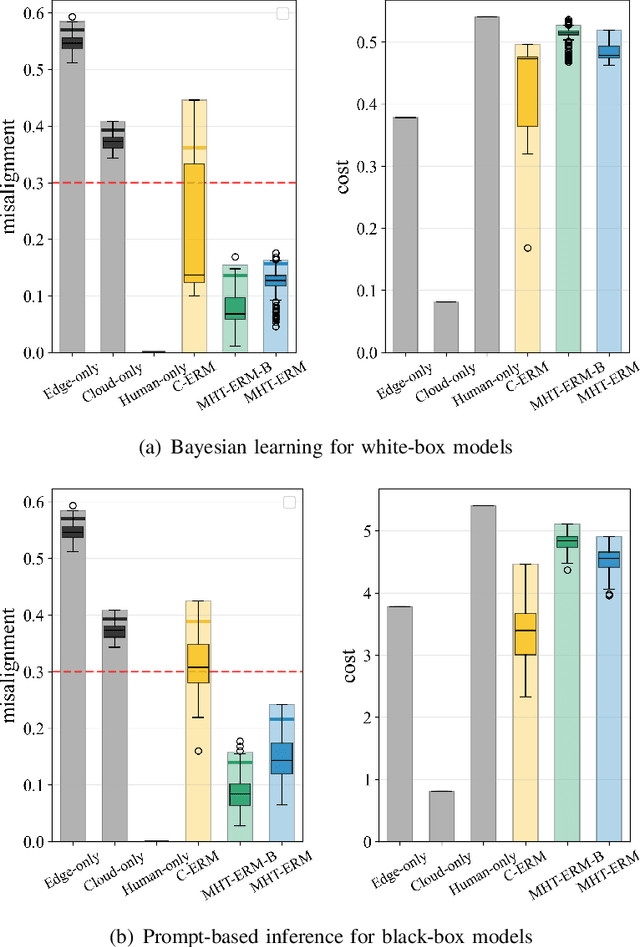
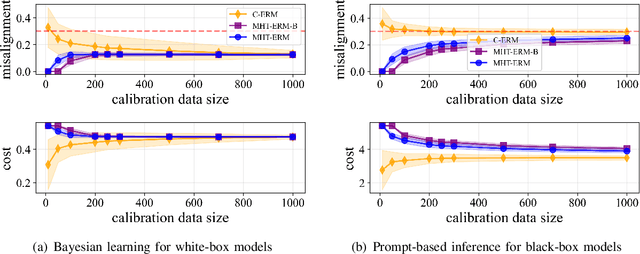
Large language models (LLMs) are emerging as key enablers of automation in domains such as telecommunications, assisting with tasks including troubleshooting, standards interpretation, and network optimization. However, their deployment in practice must balance inference cost, latency, and reliability. In this work, we study an edge-cloud-expert cascaded LLM-based knowledge system that supports decision-making through a question-and-answer pipeline. In it, an efficient edge model handles routine queries, a more capable cloud model addresses complex cases, and human experts are involved only when necessary. We define a misalignment-cost constrained optimization problem, aiming to minimize average processing cost, while guaranteeing alignment of automated answers with expert judgments. We propose a statistically rigorous threshold selection method based on multiple hypothesis testing (MHT) for a query processing mechanism based on knowledge and confidence tests. The approach provides finite-sample guarantees on misalignment risk. Experiments on the TeleQnA dataset -- a telecom-specific benchmark -- demonstrate that the proposed method achieves superior cost-efficiency compared to conventional cascaded baselines, while ensuring reliability at prescribed confidence levels.
Online Conformal Probabilistic Numerics via Adaptive Edge-Cloud Offloading
Mar 18, 2025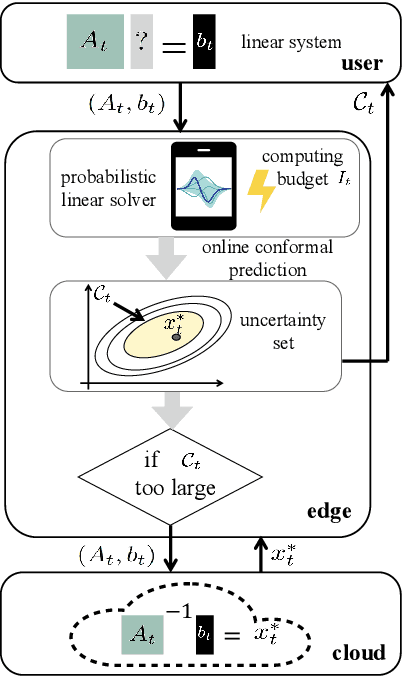
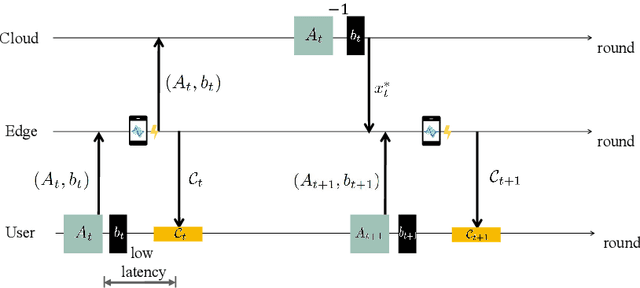
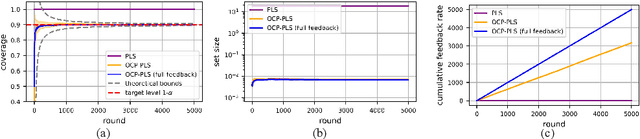
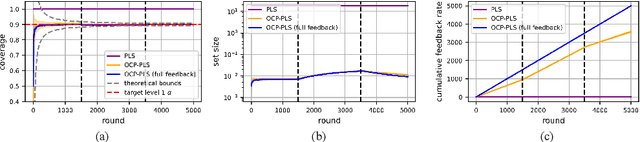
Consider an edge computing setting in which a user submits queries for the solution of a linear system to an edge processor, which is subject to time-varying computing availability. The edge processor applies a probabilistic linear solver (PLS) so as to be able to respond to the user's query within the allotted time and computing budget. Feedback to the user is in the form of an uncertainty set. Due to model misspecification, the uncertainty set obtained via a direct application of PLS does not come with coverage guarantees with respect to the true solution of the linear system. This work introduces a new method to calibrate the uncertainty sets produced by PLS with the aim of guaranteeing long-term coverage requirements. The proposed method, referred to as online conformal prediction-PLS (OCP-PLS), assumes sporadic feedback from cloud to edge. This enables the online calibration of uncertainty thresholds via online conformal prediction (OCP), an online optimization method previously studied in the context of prediction models. The validity of OCP-PLS is verified via experiments that bring insights into trade-offs between coverage, prediction set size, and cloud usage.
Joint Transmission and Deblurring: A Semantic Communication Approach Using Events
Jan 16, 2025



Deep learning-based joint source-channel coding (JSCC) is emerging as a promising technology for effective image transmission. However, most existing approaches focus on transmitting clear images, overlooking real-world challenges such as motion blur caused by camera shaking or fast-moving objects. Motion blur often degrades image quality, making transmission and reconstruction more challenging. Event cameras, which asynchronously record pixel intensity changes with extremely low latency, have shown great potential for motion deblurring tasks. However, the efficient transmission of the abundant data generated by event cameras remains a significant challenge. In this work, we propose a novel JSCC framework for the joint transmission of blurry images and events, aimed at achieving high-quality reconstructions under limited channel bandwidth. This approach is designed as a deblurring task-oriented JSCC system. Since RGB cameras and event cameras capture the same scene through different modalities, their outputs contain both shared and domain-specific information. To avoid repeatedly transmitting the shared information, we extract and transmit their shared information and domain-specific information, respectively. At the receiver, the received signals are processed by a deblurring decoder to generate clear images. Additionally, we introduce a multi-stage training strategy to train the proposed model. Simulation results demonstrate that our method significantly outperforms existing JSCC-based image transmission schemes, addressing motion blur effectively.
ROME: Robust Model Ensembling for Semantic Communication Against Semantic Jamming Attacks
Jan 02, 2025Recently, semantic communication (SC) has garnered increasing attention for its efficiency, yet it remains vulnerable to semantic jamming attacks. These attacks entail introducing crafted perturbation signals to legitimate signals over the wireless channel, thereby misleading the receivers' semantic interpretation. This paper investigates the above issue from a practical perspective. Contrasting with previous studies focusing on power-fixed attacks, we extensively consider a more challenging scenario of power-variable attacks by devising an innovative attack model named Adjustable Perturbation Generator (APG), which is capable of generating semantic jamming signals of various power levels. To combat semantic jamming attacks, we propose a novel framework called Robust Model Ensembling (ROME) for secure semantic communication. Specifically, ROME can detect the presence of semantic jamming attacks and their power levels. When high-power jamming attacks are detected, ROME adapts to raise its robustness at the cost of generalization ability, and thus effectively accommodating the attacks. Furthermore, we theoretically analyze the robustness of the system, demonstrating its superiority in combating semantic jamming attacks via adaptive robustness. Simulation results show that the proposed ROME approach exhibits significant adaptability and delivers graceful robustness and generalization ability under power-variable semantic jamming attacks.
Towards Compatible Semantic Communication: A Perspective on Digital Coding and Modulation
Dec 25, 2024



Semantic communication (SC) is emerging as a pivotal innovation within the 6G framework, aimed at enabling more intelligent transmission. This development has led to numerous studies focused on designing advanced systems through powerful deep learning techniques. Nevertheless, many of these approaches envision an analog transmission manner by formulating the transmitted signals as continuous-valued semantic representation vectors, limiting their compatibility with existing digital systems. To enhance compatibility, it is essential to explore digitized SC systems. This article systematically identifies two promising paradigms for designing digital SC: probabilistic and deterministic approaches, according to the modulation strategies. For both, we first provide a comprehensive analysis of the methodologies. Then, we put forward the principles of designing digital SC systems with a specific focus on informativeness and robustness of semantic representations to enhance performance, along with constellation design. Additionally, we present a case study to demonstrate the effectiveness of these methods. Moreover, this article also explores the intrinsic advantages and opportunities provided by digital SC systems, and then outlines several potential research directions for future investigation.