 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Transmission and Deblurring: A Semantic Communication Approach Using Events
Jan 16, 2025



Deep learning-based joint source-channel coding (JSCC) is emerging as a promising technology for effective image transmission. However, most existing approaches focus on transmitting clear images, overlooking real-world challenges such as motion blur caused by camera shaking or fast-moving objects. Motion blur often degrades image quality, making transmission and reconstruction more challenging. Event cameras, which asynchronously record pixel intensity changes with extremely low latency, have shown great potential for motion deblurring tasks. However, the efficient transmission of the abundant data generated by event cameras remains a significant challenge. In this work, we propose a novel JSCC framework for the joint transmission of blurry images and events, aimed at achieving high-quality reconstructions under limited channel bandwidth. This approach is designed as a deblurring task-oriented JSCC system. Since RGB cameras and event cameras capture the same scene through different modalities, their outputs contain both shared and domain-specific information. To avoid repeatedly transmitting the shared information, we extract and transmit their shared information and domain-specific information, respectively. At the receiver, the received signals are processed by a deblurring decoder to generate clear images. Additionally, we introduce a multi-stage training strategy to train the proposed model. Simulation results demonstrate that our method significantly outperforms existing JSCC-based image transmission schemes, addressing motion blur effectively.
Rate-Adaptive Generative Semantic Communication Using Conditional Diffusion Models
Sep 04, 2024


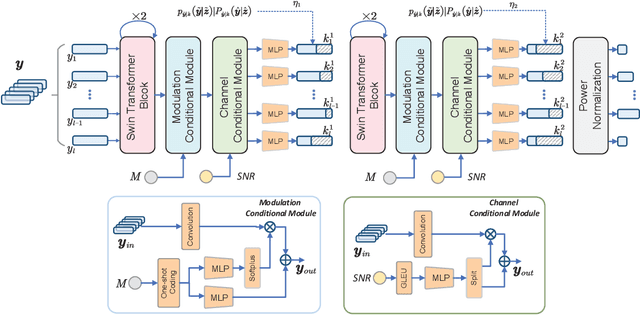
Recent advances in deep learning-based joint source-channel coding (DJSCC) have shown promise for end-to-end semantic image transmission. However, most existing schemes primarily focus on optimizing pixel-wise metrics, which often fail to align with human perception, leading to lower perceptual quality. In this letter, we propose a novel generative DJSCC approach using conditional diffusion models to enhance the perceptual quality of transmitted images. Specifically, by utilizing entropy models, we effectively manage transmission bandwidth based on the estimated entropy of transmitted sym-bols. These symbols are then used at the receiver as conditional information to guide a conditional diffusion decoder in image reconstruction. Our model is built upon the emerging advanced mamba-like linear attention (MLLA) skeleton, which excels in image processing tasks while also offering fast inference speed. Besides, we introduce a multi-stage training strategy to ensure the stability and improve the overall performance of the model. Simulation results demonstrate that our proposed method significantly outperforms existing approaches in terms of perceptual quality.
Digital Wireless Image Transmission via Distribution Matching
Jun 16, 2024Deep learning-based joint source-channel coding (JSCC) is emerging as a potential technology to meet the demand for effective data transmission, particularly for image transmission. Nevertheless, most existing advancements only consider analog transmission, where the channel symbols are continuous, making them incompatible with practical digital communication systems. In this work, we address this by involving the modulation process and consider mapping the continuous channel symbols into discrete space. Recognizing the non-uniform distribution of the output channel symbols in existing methods, we propose two effective methods to improve the performance. Firstly, we introduce a uniform modulation scheme, where the distance between two constellations is adjustable to match the non-uniform nature of the distribution. In addition, we further design a non-uniform modulation scheme according to the output distribution. To this end, we first generate the constellations by performing feature clustering on an analog image transmission system, then the generated constellations are employed to modulate the continuous channel symbols. For both schemes, we fine-tune the digital system to alleviate the performance loss caused by modulation. Here, the straight-through estimator (STE) is considered to overcome the non-differentiable nature. Our experimental results demonstrate that the proposed schemes significantly outperform existing digital image transmission systems.
From Analog to Digital: Multi-Order Digital Joint Coding-Modulation for Semantic Communication
Jun 08, 2024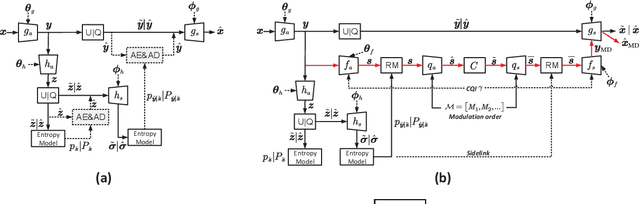
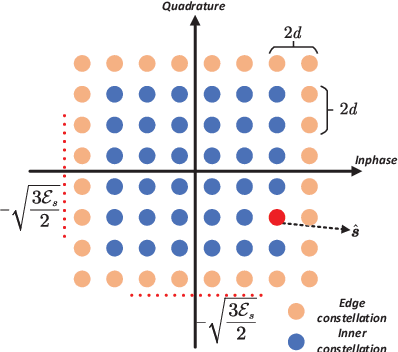
Recent studies in joint source-channel coding (JSCC) have fostered a fresh paradigm in end-to-end semantic communication. Despite notable performance achievements, present initiatives in building semantic communication systems primarily hinge on the transmission of continuous channel symbols, thus presenting challenges in compatibility with established digital systems. In this paper, we introduce a novel approach to address this challenge by developing a multi-order digital joint coding-modulation (MDJCM) scheme for semantic communications. Initially, we construct a digital semantic communication system by integrating a multi-order modulation/demodulation module into a nonlinear transform source-channel coding (NTSCC) framework. Recognizing the non-differentiable nature of modulation/demodulation, we propose a novel substitution training strategy. Herein, we treat modulation/demodulation as a constrained quantization process and introduce scaling operations alongside manually crafted noise to approximate this process. As a result, employing this approximation in training semantic communication systems can be deployed in practical modulation/demodulation scenarios with superior performance. Additionally, we demonstrate the equivalence by analyzing the involved probability distribution. Moreover, to further upgrade the performance, we develop a hierarchical dimension-reduction strategy to provide a gradual information extraction process. Extensive experimental evaluations demonstrate the superiority of our proposed method over existing digital and non-digital JSCC techniques.