 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
ROME: Robust Model Ensembling for Semantic Communication Against Semantic Jamming Attacks
Jan 02, 2025Recently, semantic communication (SC) has garnered increasing attention for its efficiency, yet it remains vulnerable to semantic jamming attacks. These attacks entail introducing crafted perturbation signals to legitimate signals over the wireless channel, thereby misleading the receivers' semantic interpretation. This paper investigates the above issue from a practical perspective. Contrasting with previous studies focusing on power-fixed attacks, we extensively consider a more challenging scenario of power-variable attacks by devising an innovative attack model named Adjustable Perturbation Generator (APG), which is capable of generating semantic jamming signals of various power levels. To combat semantic jamming attacks, we propose a novel framework called Robust Model Ensembling (ROME) for secure semantic communication. Specifically, ROME can detect the presence of semantic jamming attacks and their power levels. When high-power jamming attacks are detected, ROME adapts to raise its robustness at the cost of generalization ability, and thus effectively accommodating the attacks. Furthermore, we theoretically analyze the robustness of the system, demonstrating its superiority in combating semantic jamming attacks via adaptive robustness. Simulation results show that the proposed ROME approach exhibits significant adaptability and delivers graceful robustness and generalization ability under power-variable semantic jamming attacks.
Towards Compatible Semantic Communication: A Perspective on Digital Coding and Modulation
Dec 25, 2024



Semantic communication (SC) is emerging as a pivotal innovation within the 6G framework, aimed at enabling more intelligent transmission. This development has led to numerous studies focused on designing advanced systems through powerful deep learning techniques. Nevertheless, many of these approaches envision an analog transmission manner by formulating the transmitted signals as continuous-valued semantic representation vectors, limiting their compatibility with existing digital systems. To enhance compatibility, it is essential to explore digitized SC systems. This article systematically identifies two promising paradigms for designing digital SC: probabilistic and deterministic approaches, according to the modulation strategies. For both, we first provide a comprehensive analysis of the methodologies. Then, we put forward the principles of designing digital SC systems with a specific focus on informativeness and robustness of semantic representations to enhance performance, along with constellation design. Additionally, we present a case study to demonstrate the effectiveness of these methods. Moreover, this article also explores the intrinsic advantages and opportunities provided by digital SC systems, and then outlines several potential research directions for future investigation.
Learned Image Transmission with Hierarchical Variational Autoencoder
Sep 04, 2024



In this paper, we introduce an innovative hierarchical joint source-channel coding (HJSCC) framework for image transmission, utilizing a hierarchical variational autoencoder (VAE). Our approach leverages a combination of bottom-up and top-down paths at the transmitter to autoregressively generate multiple hierarchical representations of the original image. These representations are then directly mapped to channel symbols for transmission by the JSCC encoder. We extend this framework to scenarios with a feedback link, modeling transmission over a noisy channel as a probabilistic sampling process and deriving a novel generative formulation for JSCC with feedback. Compared with existing approaches, our proposed HJSCC provides enhanced adaptability by dynamically adjusting transmission bandwidth, encoding these representations into varying amounts of channel symbols. Additionally, we introduce a rate attention module to guide the JSCC encoder in optimizing its encoding strategy based on prior information. Extensive experiments on images of varying resolutions demonstrate that our proposed model outperforms existing baselines in rate-distortion performance and maintains robustness against channel noise.
From Analog to Digital: Multi-Order Digital Joint Coding-Modulation for Semantic Communication
Jun 08, 2024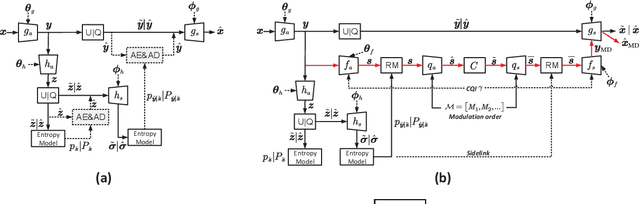
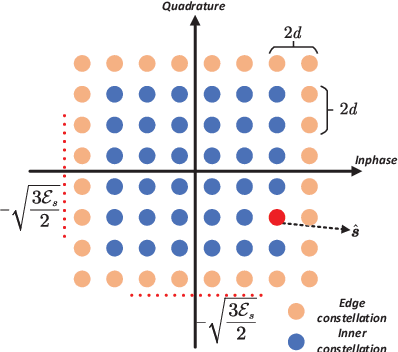
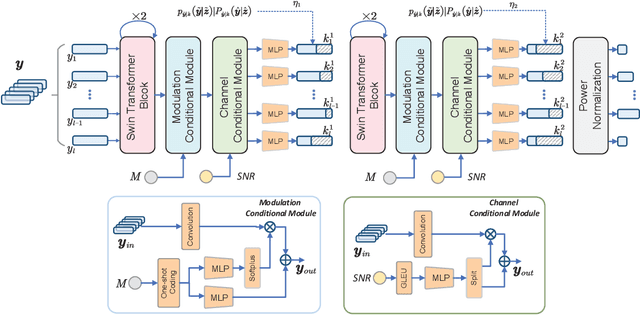
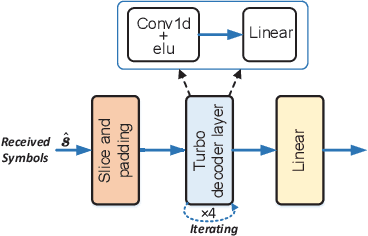
Recent studies in joint source-channel coding (JSCC) have fostered a fresh paradigm in end-to-end semantic communication. Despite notable performance achievements, present initiatives in building semantic communication systems primarily hinge on the transmission of continuous channel symbols, thus presenting challenges in compatibility with established digital systems. In this paper, we introduce a novel approach to address this challenge by developing a multi-order digital joint coding-modulation (MDJCM) scheme for semantic communications. Initially, we construct a digital semantic communication system by integrating a multi-order modulation/demodulation module into a nonlinear transform source-channel coding (NTSCC) framework. Recognizing the non-differentiable nature of modulation/demodulation, we propose a novel substitution training strategy. Herein, we treat modulation/demodulation as a constrained quantization process and introduce scaling operations alongside manually crafted noise to approximate this process. As a result, employing this approximation in training semantic communication systems can be deployed in practical modulation/demodulation scenarios with superior performance. Additionally, we demonstrate the equivalence by analyzing the involved probability distribution. Moreover, to further upgrade the performance, we develop a hierarchical dimension-reduction strategy to provide a gradual information extraction process. Extensive experimental evaluations demonstrate the superiority of our proposed method over existing digital and non-digital JSCC techniques.
Feature Allocation for Semantic Communication with Space-Time Importance Awareness
Jan 26, 2024In the realm of semantic communication, the significance of encoded features can vary, while wireless channels are known to exhibit fluctuations across multiple subchannels in different domains. Consequently, critical features may traverse subchannels with poor states, resulting in performance degradation. To tackle this challenge, we introduce a framework called Feature Allocation for Semantic Transmission (FAST), which offers adaptability to channel fluctuations across both spatial and temporal domains. In particular, an importance evaluator is first developed to assess the importance of various features. In the temporal domain, channel prediction is utilized to estimate future channel state information (CSI). Subsequently, feature allocation is implemented by assigning suitable transmission time slots to different features. Furthermore, we extend FAST to the space-time domain, considering two common scenarios: precoding-free and precoding-based multiple-input multiple-output (MIMO) systems. An important attribute of FAST is its versatility, requiring no intricate fine-tuning. Simulation results demonstrate that this approach significantly enhances the performance of semantic communication systems in image transmission. It retains its superiority even when faced with substantial changes in system configuration.
Alleviating Distortion Accumulation in Multi-Hop Semantic Communication
Aug 22, 2023Recently, semantic communication has been investigated to boost the performance of end-to-end image transmission systems. However, existing semantic approaches are generally based on deep learning and belong to lossy transmission. Consequently, as the receiver continues to transmit received images to another device, the distortion of images accumulates with each transmission. Unfortunately, most recent advances overlook this issue and only consider single-hop scenarios, where images are transmitted only once from a transmitter to a receiver. In this letter, we propose a novel framework of a multi-hop semantic communication system. To address the problem of distortion accumulation, we introduce a novel recursive training method for the encoder and decoder of semantic communication systems. Specifically, the received images are recursively input into the encoder and decoder to retrain the semantic communication system. This empowers the system to handle distorted received images and achieve higher performance. Our extensive simulation results demonstrate that the proposed methods significantly alleviate distortion accumulation in multi-hop semantic communication.
SCAN: Semantic Communication with Adaptive Channel Feedback
Jun 27, 2023In existing semantic communication systems for image transmission, some images are generally reconstructed with considerably low quality. As a result, the reliable transmission of each image cannot be guaranteed, bringing significant uncertainty to semantic communication systems. To address this issue, we propose a novel performance metric to characterize the reliability of semantic communication systems termed semantic distortion outage probability (SDOP), which is defined as the probability of the instantaneous distortion larger than a given target threshold. Then, since the images with lower reconstruction quality are generally less robust and need to be allocated with more communication resources, we propose a novel framework of Semantic Communication with Adaptive chaNnel feedback (SCAN). It can reduce SDOP by adaptively adjusting the overhead of channel feedback for images with different reconstruction qualities, thereby enhancing transmission reliability. To realize SCAN, we first develop a deep learning-enabled semantic communication system for multiple-input multiple-output (MIMO) channels (DeepSC-MIMO) by leveraging the channel state information (CSI) and noise variance in the model design. We then develop a performance evaluator to predict the reconstruction quality of each image at the transmitter by distilling knowledge from DeepSC-MIMO. In this way, images with lower predicted reconstruction quality will be allocated with a longer CSI codeword to guarantee the reconstruction quality. We perform extensive experiments to demonstrate that the proposed scheme can significantly improve the reliability of image transmission while greatly reducing the feedback overhead.
One-shot Learning for Channel Estimation in Massive MIMO Systems
Jun 09, 2023



In conventional supervised deep learning based channel estimation algorithms, a large number of training samples are required for offline training. However, in practical communication systems, it is difficult to obtain channel samples for every signal-to-noise ratio (SNR). Furthermore, the generalization ability of these deep neural networks (DNN) is typically poor. In this work, we propose a one-shot self-supervised learning framework for channel estimation in multi-input multi-output (MIMO) systems. The required number of samples for offline training is small and our approach can be directly deployed to adapt to variable channels. Our framework consists of a traditional channel estimation module and a denoising module. The denoising module is designed based on the one-shot learning method Self2Self and employs Bernoulli sampling to generate training labels. Besides,we further utilize a blind spot strategy and dropout technique to avoid overfitting. Simulation results show that the performance of the proposed one-shot self-supervised learning method is very close to the supervised learning approach while obtaining improved generalization ability for different channel environments.
Deep-Unfolding for Next-Generation Transceivers
May 15, 2023The stringent performance requirements of future wireless networks, such as ultra-high data rates, extremely high reliability and low latency, are spurring worldwide studies on defining the next-generation multiple-input multiple-output (MIMO) transceivers. For the design of advanced transceivers in wireless communications, optimization approaches often leading to iterative algorithms have achieved great success for MIMO transceivers. However, these algorithms generally require a large number of iterations to converge, which entails considerable computational complexity and often requires fine-tuning of various parameters. With the development of deep learning, approximating the iterative algorithms with deep neural networks (DNNs) can significantly reduce the computational time. However, DNNs typically lead to black-box solvers, which requires amounts of data and extensive training time. To further overcome these challenges, deep-unfolding has emerged which incorporates the benefits of both deep learning and iterative algorithms, by unfolding the iterative algorithm into a layer-wise structure analogous to DNNs. In this article, we first go through the framework of deep-unfolding for transceiver design with matrix parameters and its recent advancements. Then, some endeavors in applying deep-unfolding approaches in next-generation advanced transceiver design are presented. Moreover, some open issues for future research are highlighted.