 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFL-Sailer: Efficient and Privacy-Preserving Federated Learning for Scalable Single-Cell Epigenetic Data Analysis via Adaptive Sampling
May 06, 2026Single-cell ATAC-seq (scATAC-seq) enables high-resolution mapping of chromatin accessibility, yet privacy regulations and data size constraints hinder multi-institutional sharing. Federated learning (FL) offers a privacy-preserving alternative, but faces three fundamental barriers in scATAC-seq analysis: ultra-high dimensionality, extreme sparsity, and severe cross-institutional heterogeneity. We propose FL-Sailer, the first FL framework designed for scATAC-seq data. FL-Sailer integrates two key innovations: (i) adaptive leverage score sampling, which selects biologically interpretable features while reducing dimensionality by 80%, and (ii) an invariant VAE architecture, which disentangles biological signals from technical confounders via mutual information minimization. We provide a convergence guarantee, showing that FL-Sailer converges to an approximate solution of the original high-dimensional problem with bounded error. Extensive experiments on synthetic and real epigenomic datasets demonstrate that FL-Sailer not only enables previously infeasible multi-institutional collaborations but also surpasses centralized methods by leveraging adaptive sampling as an implicit regularizer to suppress technical noise. Our work establishes that federated learning, when tailored to domain-specific challenges, can become a superior paradigm for collaborative epigenomic research.
Location-Agnostic Channel Knowledge Map Construction for Dynamic Scenes
Mar 10, 2026To alleviate the pilot and CSI-feedback burden in 6G, channel knowledge map (CKM) has emerged as a promising approach that predicts CSI solely from user locations. Nevertheless, accurate location information is rarely available in current systems. Moreover, the uncertainty inherent to highly dynamic scenes further degrades the performance of existing schemes that typically assume quasi-static scenarios. In this paper, we propose a novel framework named location-agnostic dynamic CKM (LAD-CKM). Specifically, LAD-CKM is constructed through dynamic radio frequency (RF) radiance field rendering, which takes instantaneous uplink CSI and partial downlink CSI as inputs. To enable effective rendering, a dedicated radiator representation network (RARE-Net) is designed to capture the spatial-spectral correlations within the inputs. Furthermore, an adaptive deformation module is devised to deform the uplink CSI-based queries of RARE-Net according to instantaneous channel dynamics, thereby enhancing CSI prediction accuracy under mobility. In addition, a novel synthetic channel dataset is created in outdoor dynamic scenes via ray-tracing. Simulation results demonstrate that LAD-CKM yields significant performance gains compared with existing baselines in terms of effective data rate.
Prediction-Powered Risk Monitoring of Deployed Models for Detecting Harmful Distribution Shifts
Feb 02, 2026We study the problem of monitoring model performance in dynamic environments where labeled data are limited. To this end, we propose prediction-powered risk monitoring (PPRM), a semi-supervised risk-monitoring approach based on prediction-powered inference (PPI). PPRM constructs anytime-valid lower bounds on the running risk by combining synthetic labels with a small set of true labels. Harmful shifts are detected via a threshold-based comparison with an upper bound on the nominal risk, satisfying assumption-free finite-sample guarantees in the probability of false alarm. We demonstrate the effectiveness of PPRM through extensive experiments on image classification, large language model (LLM), and telecommunications monitoring tasks.
F$^4$-CKM: Learning Channel Knowledge Map with Radio Frequency Radiance Field Rendering
Jan 07, 2026In 6G mobile communications, acquiring accurate and timely channel state information (CSI) becomes increasingly challenging due to the growing antenna array size and bandwidth. To alleviate the CSI feedback burden, the channel knowledge map (CKM) has emerged as a promising approach by leveraging environment-aware techniques to predict CSI based solely on user locations. However, how to effectively construct a CKM remains an open issue. In this paper, we propose F$^4$-CKM, a novel CKM construction framework characterized by four distinctive features: radiance Field rendering, spatial-Frequency-awareness, location-Free usage, and Fast learning. Central to our design is the adaptation of radiance field rendering techniques from computer vision to the radio frequency (RF) domain, enabled by a novel Wireless Radiator Representation (WiRARE) network that captures the spatial-frequency characteristics of wireless channels. Additionally, a novel shaping filter module and an angular sampling strategy are introduced to facilitate CKM construction. Extensive experiments demonstrate that F$^4$-CKM significantly outperforms existing baselines in terms of wireless channel prediction accuracy and efficiency.
Joint Transmission and Deblurring: A Semantic Communication Approach Using Events
Jan 16, 2025



Deep learning-based joint source-channel coding (JSCC) is emerging as a promising technology for effective image transmission. However, most existing approaches focus on transmitting clear images, overlooking real-world challenges such as motion blur caused by camera shaking or fast-moving objects. Motion blur often degrades image quality, making transmission and reconstruction more challenging. Event cameras, which asynchronously record pixel intensity changes with extremely low latency, have shown great potential for motion deblurring tasks. However, the efficient transmission of the abundant data generated by event cameras remains a significant challenge. In this work, we propose a novel JSCC framework for the joint transmission of blurry images and events, aimed at achieving high-quality reconstructions under limited channel bandwidth. This approach is designed as a deblurring task-oriented JSCC system. Since RGB cameras and event cameras capture the same scene through different modalities, their outputs contain both shared and domain-specific information. To avoid repeatedly transmitting the shared information, we extract and transmit their shared information and domain-specific information, respectively. At the receiver, the received signals are processed by a deblurring decoder to generate clear images. Additionally, we introduce a multi-stage training strategy to train the proposed model. Simulation results demonstrate that our method significantly outperforms existing JSCC-based image transmission schemes, addressing motion blur effectively.
ROME: Robust Model Ensembling for Semantic Communication Against Semantic Jamming Attacks
Jan 02, 2025Recently, semantic communication (SC) has garnered increasing attention for its efficiency, yet it remains vulnerable to semantic jamming attacks. These attacks entail introducing crafted perturbation signals to legitimate signals over the wireless channel, thereby misleading the receivers' semantic interpretation. This paper investigates the above issue from a practical perspective. Contrasting with previous studies focusing on power-fixed attacks, we extensively consider a more challenging scenario of power-variable attacks by devising an innovative attack model named Adjustable Perturbation Generator (APG), which is capable of generating semantic jamming signals of various power levels. To combat semantic jamming attacks, we propose a novel framework called Robust Model Ensembling (ROME) for secure semantic communication. Specifically, ROME can detect the presence of semantic jamming attacks and their power levels. When high-power jamming attacks are detected, ROME adapts to raise its robustness at the cost of generalization ability, and thus effectively accommodating the attacks. Furthermore, we theoretically analyze the robustness of the system, demonstrating its superiority in combating semantic jamming attacks via adaptive robustness. Simulation results show that the proposed ROME approach exhibits significant adaptability and delivers graceful robustness and generalization ability under power-variable semantic jamming attacks.
Towards Compatible Semantic Communication: A Perspective on Digital Coding and Modulation
Dec 25, 2024



Semantic communication (SC) is emerging as a pivotal innovation within the 6G framework, aimed at enabling more intelligent transmission. This development has led to numerous studies focused on designing advanced systems through powerful deep learning techniques. Nevertheless, many of these approaches envision an analog transmission manner by formulating the transmitted signals as continuous-valued semantic representation vectors, limiting their compatibility with existing digital systems. To enhance compatibility, it is essential to explore digitized SC systems. This article systematically identifies two promising paradigms for designing digital SC: probabilistic and deterministic approaches, according to the modulation strategies. For both, we first provide a comprehensive analysis of the methodologies. Then, we put forward the principles of designing digital SC systems with a specific focus on informativeness and robustness of semantic representations to enhance performance, along with constellation design. Additionally, we present a case study to demonstrate the effectiveness of these methods. Moreover, this article also explores the intrinsic advantages and opportunities provided by digital SC systems, and then outlines several potential research directions for future investigation.
Coarse-to-Fine: A Dual-Phase Channel-Adaptive Method for Wireless Image Transmission
Dec 11, 2024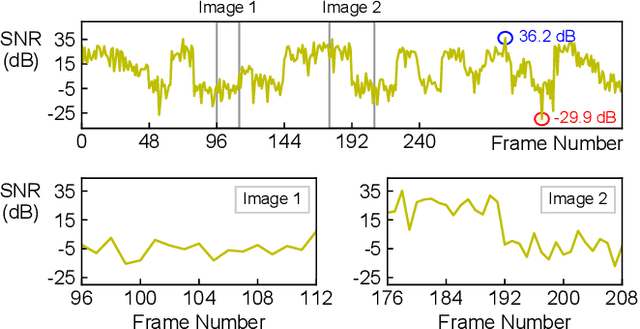
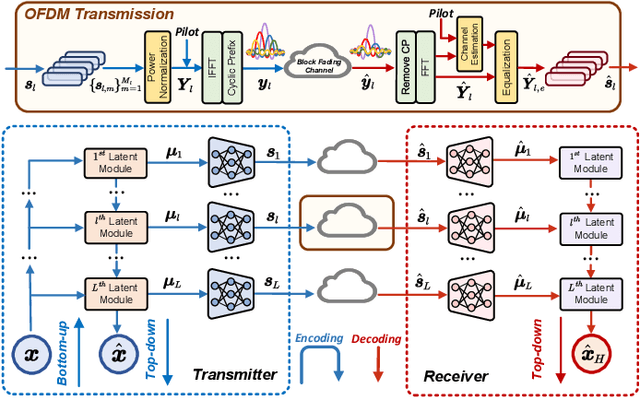
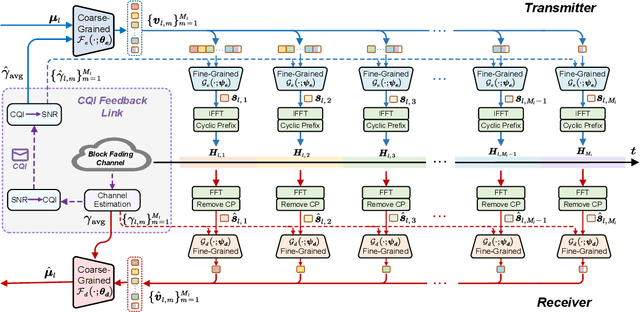
Developing channel-adaptive deep joint source-channel coding (JSCC) systems is a critical challenge in wireless image transmission. While recent advancements have been made, most existing approaches are designed for static channel environments, limiting their ability to capture the dynamics of channel environments. As a result, their performance may degrade significantly in practical systems. In this paper, we consider time-varying block fading channels, where the transmission of a single image can experience multiple fading events. We propose a novel coarse-to-fine channel-adaptive JSCC framework (CFA-JSCC) that is designed to handle both significant fluctuations and rapid changes in wireless channels. Specifically, in the coarse-grained phase, CFA-JSCC utilizes the average signal-to-noise ratio (SNR) to adjust the encoding strategy, providing a preliminary adaptation to the prevailing channel conditions. Subsequently, in the fine-grained phase, CFA-JSCC leverages instantaneous SNR to dynamically refine the encoding strategy. This refinement is achieved by re-encoding the remaining channel symbols whenever the channel conditions change. Additionally, to reduce the overhead for SNR feedback, we utilize a limited set of channel quality indicators (CQIs) to represent the channel SNR and further propose a reinforcement learning (RL)-based CQI selection strategy to learn this mapping. This strategy incorporates a novel reward shaping scheme that provides intermediate rewards to facilitate the training process. Experimental results demonstrate that our CFA-JSCC provides enhanced flexibility in capturing channel variations and improved robustness in time-varying channel environments.
Rate-Adaptive Generative Semantic Communication Using Conditional Diffusion Models
Sep 04, 2024


Recent advances in deep learning-based joint source-channel coding (DJSCC) have shown promise for end-to-end semantic image transmission. However, most existing schemes primarily focus on optimizing pixel-wise metrics, which often fail to align with human perception, leading to lower perceptual quality. In this letter, we propose a novel generative DJSCC approach using conditional diffusion models to enhance the perceptual quality of transmitted images. Specifically, by utilizing entropy models, we effectively manage transmission bandwidth based on the estimated entropy of transmitted sym-bols. These symbols are then used at the receiver as conditional information to guide a conditional diffusion decoder in image reconstruction. Our model is built upon the emerging advanced mamba-like linear attention (MLLA) skeleton, which excels in image processing tasks while also offering fast inference speed. Besides, we introduce a multi-stage training strategy to ensure the stability and improve the overall performance of the model. Simulation results demonstrate that our proposed method significantly outperforms existing approaches in terms of perceptual quality.
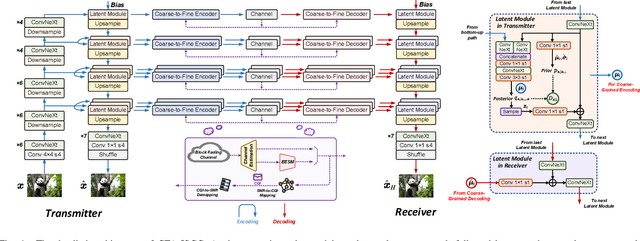
Learned Image Transmission with Hierarchical Variational Autoencoder
Sep 04, 2024



In this paper, we introduce an innovative hierarchical joint source-channel coding (HJSCC) framework for image transmission, utilizing a hierarchical variational autoencoder (VAE). Our approach leverages a combination of bottom-up and top-down paths at the transmitter to autoregressively generate multiple hierarchical representations of the original image. These representations are then directly mapped to channel symbols for transmission by the JSCC encoder. We extend this framework to scenarios with a feedback link, modeling transmission over a noisy channel as a probabilistic sampling process and deriving a novel generative formulation for JSCC with feedback. Compared with existing approaches, our proposed HJSCC provides enhanced adaptability by dynamically adjusting transmission bandwidth, encoding these representations into varying amounts of channel symbols. Additionally, we introduce a rate attention module to guide the JSCC encoder in optimizing its encoding strategy based on prior information. Extensive experiments on images of varying resolutions demonstrate that our proposed model outperforms existing baselines in rate-distortion performance and maintains robustness against channel noise.