 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDFFDNet: Towards Accurate and Efficient Unsupervised Multi-Grid Image Registration
Sep 09, 2025Previous deep image registration methods that employ single homography, multi-grid homography, or thin-plate spline often struggle with real scenes containing depth disparities due to their inherent limitations. To address this, we propose an Exponential-Decay Free-Form Deformation Network (EDFFDNet), which employs free-form deformation with an exponential-decay basis function. This design achieves higher efficiency and performs well in scenes with depth disparities, benefiting from its inherent locality. We also introduce an Adaptive Sparse Motion Aggregator (ASMA), which replaces the MLP motion aggregator used in previous methods. By transforming dense interactions into sparse ones, ASMA reduces parameters and improves accuracy. Additionally, we propose a progressive correlation refinement strategy that leverages global-local correlation patterns for coarse-to-fine motion estimation, further enhancing efficiency and accuracy. Experiments demonstrate that EDFFDNet reduces parameters, memory, and total runtime by 70.5%, 32.6%, and 33.7%, respectively, while achieving a 0.5 dB PSNR gain over the state-of-the-art method. With an additional local refinement stage,EDFFDNet-2 further improves PSNR by 1.06 dB while maintaining lower computational costs. Our method also demonstrates strong generalization ability across datasets, outperforming previous deep learning methods.
Structure-Aware Radar-Camera Depth Estimation
Jun 05, 2025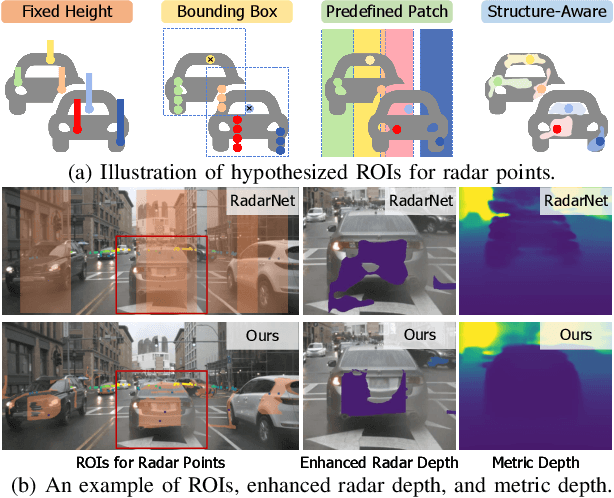
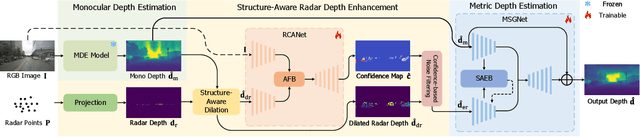
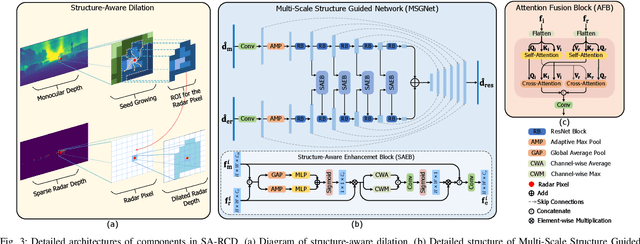
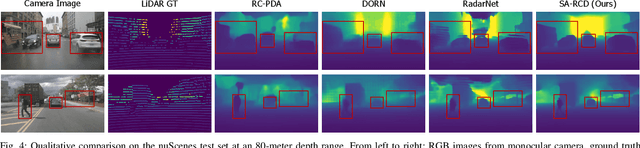
Monocular depth estimation aims to determine the depth of each pixel from an RGB image captured by a monocular camera. The development of deep learning has significantly advanced this field by facilitating the learning of depth features from some well-annotated datasets \cite{Geiger_Lenz_Stiller_Urtasun_2013,silberman2012indoor}. Eigen \textit{et al.} \cite{eigen2014depth} first introduce a multi-scale fusion network for depth regression. Following this, subsequent improvements have come from reinterpreting the regression task as a classification problem \cite{bhat2021adabins,Li_Wang_Liu_Jiang_2022}, incorporating additional priors \cite{shao2023nddepth,yang2023gedepth}, and developing more effective objective function \cite{xian2020structure,Yin_Liu_Shen_Yan_2019}. Despite these advances, generalizing to unseen domains remains a challenge. Recently, several methods have employed affine-invariant loss to enable multi-dataset joint training \cite{MiDaS,ZeroDepth,guizilini2023towards,Dany}. Among them, Depth Anything \cite{Dany} has shown leading performance in zero-shot monocular depth estimation. While it struggles to estimate accurate metric depth due to the lack of explicit depth cues, it excels at extracting structural information from unseen images, producing structure-detailed monocular depth.
Language Driven Occupancy Prediction
Nov 25, 2024



We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and utimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our semantic transitive labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-ofthe-art zero-shot occupancy prediction approaches on the Occ3D-nuScenes dataset. Notably, even based on the simpler BEVDet model, with an input resolution of 256 * 704,Occ-BEVDet achieves an mIoU of 20.29, surpassing previous approaches that rely on temporal images, higher-resolution inputs, or larger backbone networks. The code for the proposed method is available at https://github.com/pkqbajng/LOcc.
InterNet: Unsupervised Cross-modal Homography Estimation Based on Interleaved Modality Transfer and Self-supervised Homography Prediction
Sep 26, 2024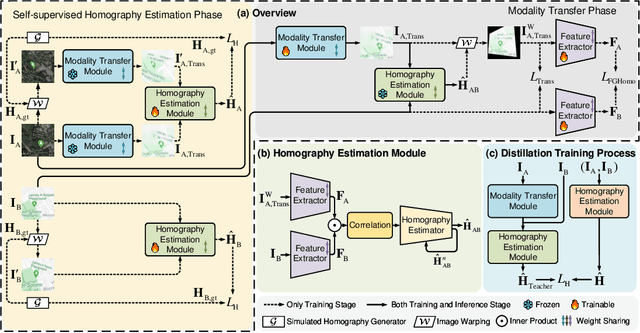
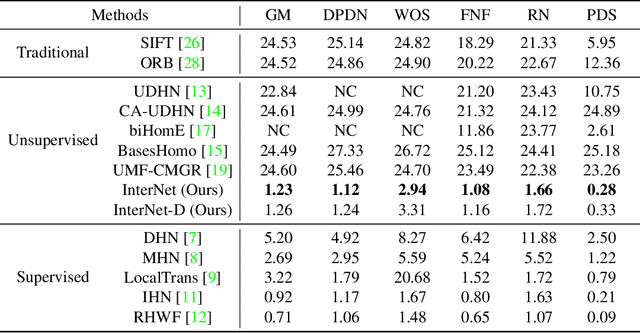


We propose a novel unsupervised cross-modal homography estimation framework, based on interleaved modality transfer and self-supervised homography prediction, named InterNet. InterNet integrates modality transfer and self-supervised homography estimation, introducing an innovative interleaved optimization framework to alternately promote both components. The modality transfer gradually narrows the modality gaps, facilitating the self-supervised homography estimation to fully leverage the synthetic intra-modal data. The self-supervised homography estimation progressively achieves reliable predictions, thereby providing robust cross-modal supervision for the modality transfer. To further boost the estimation accuracy, we also formulate a fine-grained homography feature loss to improve the connection between two components. Furthermore, we employ a simple yet effective distillation training technique to reduce model parameters and improve cross-domain generalization ability while maintaining comparable performance. Experiments reveal that InterNet achieves the state-of-the-art (SOTA) performance among unsupervised methods, and even outperforms many supervised methods such as MHN and LocalTrans.
Learned Image Transmission with Hierarchical Variational Autoencoder
Sep 04, 2024



In this paper, we introduce an innovative hierarchical joint source-channel coding (HJSCC) framework for image transmission, utilizing a hierarchical variational autoencoder (VAE). Our approach leverages a combination of bottom-up and top-down paths at the transmitter to autoregressively generate multiple hierarchical representations of the original image. These representations are then directly mapped to channel symbols for transmission by the JSCC encoder. We extend this framework to scenarios with a feedback link, modeling transmission over a noisy channel as a probabilistic sampling process and deriving a novel generative formulation for JSCC with feedback. Compared with existing approaches, our proposed HJSCC provides enhanced adaptability by dynamically adjusting transmission bandwidth, encoding these representations into varying amounts of channel symbols. Additionally, we introduce a rate attention module to guide the JSCC encoder in optimizing its encoding strategy based on prior information. Extensive experiments on images of varying resolutions demonstrate that our proposed model outperforms existing baselines in rate-distortion performance and maintains robustness against channel noise.
SCPNet: Unsupervised Cross-modal Homography Estimation via Intra-modal Self-supervised Learning
Jul 11, 2024



We propose a novel unsupervised cross-modal homography estimation framework based on intra-modal Self-supervised learning, Correlation, and consistent feature map Projection, namely SCPNet. The concept of intra-modal self-supervised learning is first presented to facilitate the unsupervised cross-modal homography estimation. The correlation-based homography estimation network and the consistent feature map projection are combined to form the learnable architecture of SCPNet, boosting the unsupervised learning framework. SCPNet is the first to achieve effective unsupervised homography estimation on the satellite-map image pair cross-modal dataset, GoogleMap, under [-32,+32] offset on a 128x128 image, leading the supervised approach MHN by 14.0% of mean average corner error (MACE). We further conduct extensive experiments on several cross-modal/spectral and manually-made inconsistent datasets, on which SCPNet achieves the state-of-the-art (SOTA) performance among unsupervised approaches, and owns 49.0%, 25.2%, 36.4%, and 10.7% lower MACEs than the supervised approach MHN. Source code is available at https://github.com/RM-Zhang/SCPNet.
Rethinking Early-Fusion Strategies for Improved Multispectral Object Detection
May 25, 2024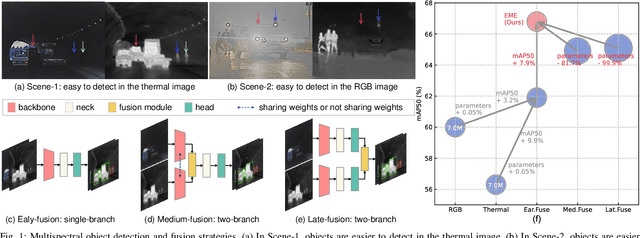
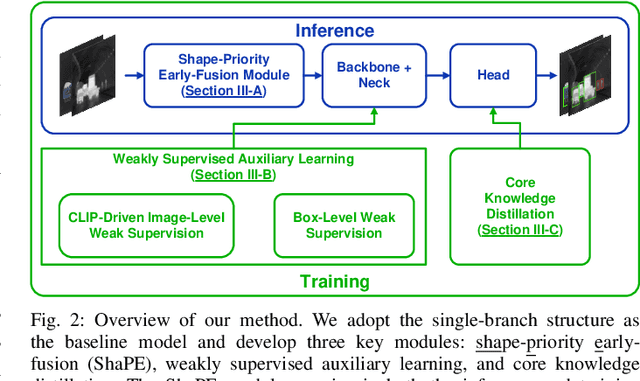


Most recent multispectral object detectors employ a two-branch structure to extract features from RGB and thermal images. While the two-branch structure achieves better performance than a single-branch structure, it overlooks inference efficiency. This conflict is increasingly aggressive, as recent works solely pursue higher performance rather than both performance and efficiency. In this paper, we address this issue by improving the performance of efficient single-branch structures. We revisit the reasons causing the performance gap between these structures. For the first time, we reveal the information interference problem in the naive early-fusion strategy adopted by previous single-branch structures. Besides, we find that the domain gap between multispectral images, and weak feature representation of the single-branch structure are also key obstacles for performance. Focusing on these three problems, we propose corresponding solutions, including a novel shape-priority early-fusion strategy, a weakly supervised learning method, and a core knowledge distillation technique. Experiments demonstrate that single-branch networks equipped with these three contributions achieve significant performance enhancements while retaining high efficiency. Our code will be available at \url{https://github.com/XueZ-phd/Efficient-RGB-T-Early-Fusion-Detection}.
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024



Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.