 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDFFDNet: Towards Accurate and Efficient Unsupervised Multi-Grid Image Registration
Sep 09, 2025Previous deep image registration methods that employ single homography, multi-grid homography, or thin-plate spline often struggle with real scenes containing depth disparities due to their inherent limitations. To address this, we propose an Exponential-Decay Free-Form Deformation Network (EDFFDNet), which employs free-form deformation with an exponential-decay basis function. This design achieves higher efficiency and performs well in scenes with depth disparities, benefiting from its inherent locality. We also introduce an Adaptive Sparse Motion Aggregator (ASMA), which replaces the MLP motion aggregator used in previous methods. By transforming dense interactions into sparse ones, ASMA reduces parameters and improves accuracy. Additionally, we propose a progressive correlation refinement strategy that leverages global-local correlation patterns for coarse-to-fine motion estimation, further enhancing efficiency and accuracy. Experiments demonstrate that EDFFDNet reduces parameters, memory, and total runtime by 70.5%, 32.6%, and 33.7%, respectively, while achieving a 0.5 dB PSNR gain over the state-of-the-art method. With an additional local refinement stage,EDFFDNet-2 further improves PSNR by 1.06 dB while maintaining lower computational costs. Our method also demonstrates strong generalization ability across datasets, outperforming previous deep learning methods.
Multi-task CNN Behavioral Embedding Model For Transaction Fraud Detection
Nov 29, 2024

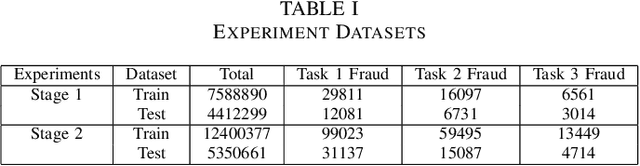
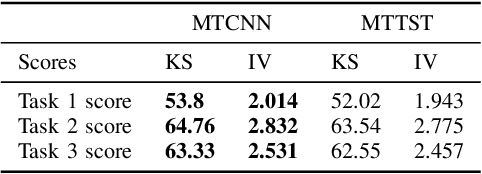
The burgeoning e-Commerce sector requires advanced solutions for the detection of transaction fraud. With an increasing risk of financial information theft and account takeovers, deep learning methods have become integral to the embedding of behavior sequence data in fraud detection. However, these methods often struggle to balance modeling capabilities and efficiency and incorporate domain knowledge. To address these issues, we introduce the multitask CNN behavioral Embedding Model for Transaction Fraud Detection. Our contributions include 1) introducing a single-layer CNN design featuring multirange kernels which outperform LSTM and Transformer models in terms of scalability and domain-focused inductive bias, and 2) the integration of positional encoding with CNN to introduce sequence-order signals enhancing overall performance, and 3) implementing multitask learning with randomly assigned label weights, thus removing the need for manual tuning. Testing on real-world data reveals our model's enhanced performance of downstream transaction models and comparable competitiveness with the Transformer Time Series (TST) model.
MuVAM: A Multi-View Attention-based Model for Medical Visual Question Answering
Jul 07, 2021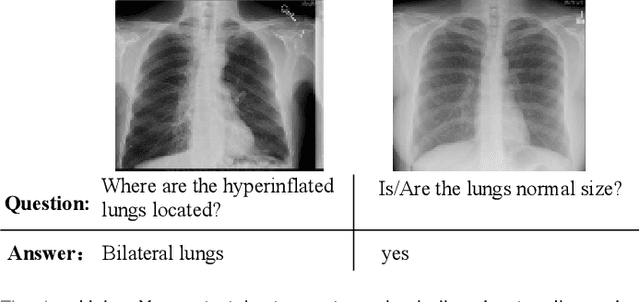
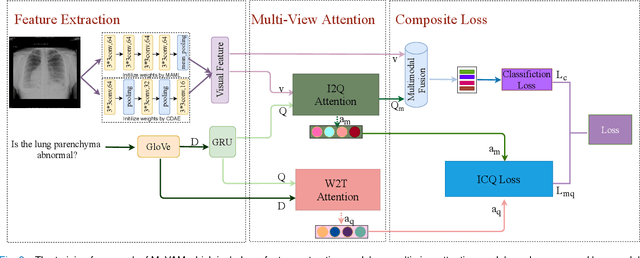
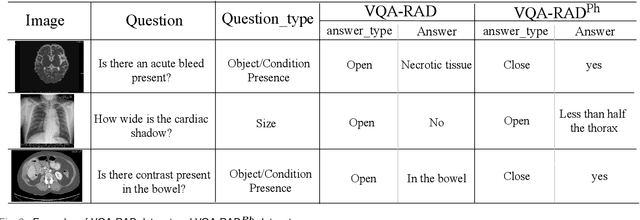
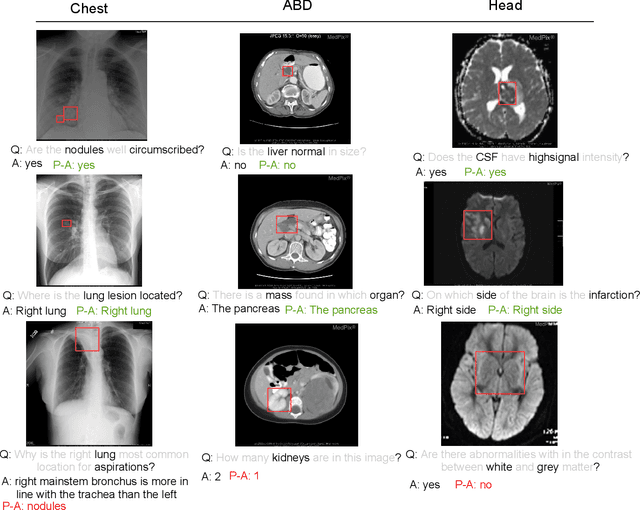
Medical Visual Question Answering (VQA) is a multi-modal challenging task widely considered by research communities of the computer vision and natural language processing. Since most current medical VQA models focus on visual content, ignoring the importance of text, this paper proposes a multi-view attention-based model(MuVAM) for medical visual question answering which integrates the high-level semantics of medical images on the basis of text description. Firstly, different methods are utilized to extract the features of the image and the question for the two modalities of vision and text. Secondly, this paper proposes a multi-view attention mechanism that include Image-to-Question (I2Q) attention and Word-to-Text (W2T) attention. Multi-view attention can correlate the question with image and word in order to better analyze the question and get an accurate answer. Thirdly, a composite loss is presented to predict the answer accurately after multi-modal feature fusion and improve the similarity between visual and textual cross-modal features. It consists of classification loss and image-question complementary (IQC) loss. Finally, for data errors and missing labels in the VQA-RAD dataset, we collaborate with medical experts to correct and complete this dataset and then construct an enhanced dataset, VQA-RADPh. The experiments on these two datasets show that the effectiveness of MuVAM surpasses the state-of-the-art method.
Deep Attributed Network Representation Learning via Attribute Enhanced Neighborhood
Apr 12, 2021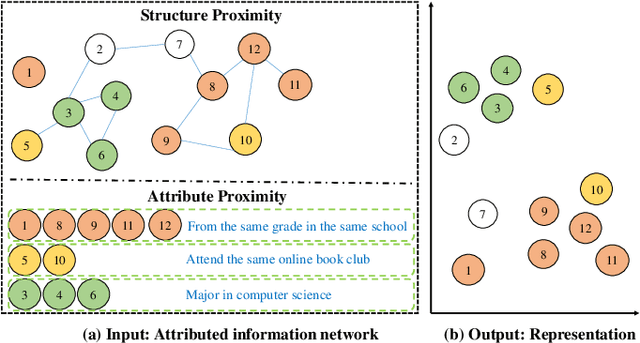


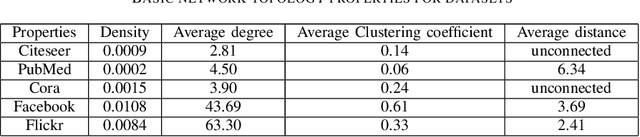
Attributed network representation learning aims at learning node embeddings by integrating network structure and attribute information. It is a challenge to fully capture the microscopic structure and the attribute semantics simultaneously, where the microscopic structure includes the one-step, two-step and multi-step relations, indicating the first-order, second-order and high-order proximity of nodes, respectively. In this paper, we propose a deep attributed network representation learning via attribute enhanced neighborhood (DANRL-ANE) model to improve the robustness and effectiveness of node representations. The DANRL-ANE model adopts the idea of the autoencoder, and expands the decoder component to three branches to capture different order proximity. We linearly combine the adjacency matrix with the attribute similarity matrix as the input of our model, where the attribute similarity matrix is calculated by the cosine similarity between the attributes based on the social homophily. In this way, we preserve the second-order proximity to enhance the robustness of DANRL-ANE model on sparse networks, and deal with the topological and attribute information simultaneously. Moreover, the sigmoid cross-entropy loss function is extended to capture the neighborhood character, so that the first-order proximity is better preserved. We compare our model with the state-of-the-art models on five real-world datasets and two network analysis tasks, i.e., link prediction and node classification. The DANRL-ANE model performs well on various networks, even on sparse networks or networks with isolated nodes given the attribute information is sufficient.