 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar and Camera Fusion for Object Detection and Tracking: A Comprehensive Survey
Oct 24, 2024



Multi-modal fusion is imperative to the implementation of reliable object detection and tracking in complex environments. Exploiting the synergy of heterogeneous modal information endows perception systems the ability to achieve more comprehensive, robust, and accurate performance. As a nucleus concern in wireless-vision collaboration, radar-camera fusion has prompted prospective research directions owing to its extensive applicability, complementarity, and compatibility. Nonetheless, there still lacks a systematic survey specifically focusing on deep fusion of radar and camera for object detection and tracking. To fill this void, we embark on an endeavor to comprehensively review radar-camera fusion in a holistic way. First, we elaborate on the fundamental principles, methodologies, and applications of radar-camera fusion perception. Next, we delve into the key techniques concerning sensor calibration, modal representation, data alignment, and fusion operation. Furthermore, we provide a detailed taxonomy covering the research topics related to object detection and tracking in the context of radar and camera technologies.Finally, we discuss the emerging perspectives in the field of radar-camera fusion perception and highlight the potential areas for future research.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
HDNet: Hierarchical Dynamic Network for Gait Recognition using Millimeter-Wave Radar
Nov 01, 2022



Gait recognition is widely used in diversified practical applications. Currently, the most prevalent approach is to recognize human gait from RGB images, owing to the progress of computer vision technologies. Nevertheless, the perception capability of RGB cameras deteriorates in rough circumstances, and visual surveillance may cause privacy invasion. Due to the robustness and non-invasive feature of millimeter wave (mmWave) radar, radar-based gait recognition has attracted increasing attention in recent years. In this research, we propose a Hierarchical Dynamic Network (HDNet) for gait recognition using mmWave radar. In order to explore more dynamic information, we propose point flow as a novel point clouds descriptor. We also devise a dynamic frame sampling module to promote the efficiency of computation without deteriorating performance noticeably. To prove the superiority of our methods, we perform extensive experiments on two public mmWave radar-based gait recognition datasets, and the results demonstrate that our model is superior to existing state-of-the-art methods.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022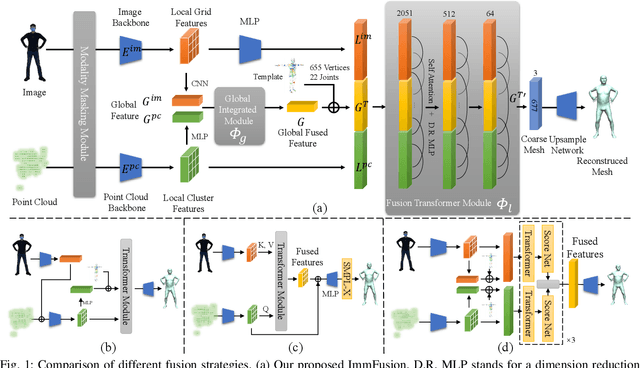
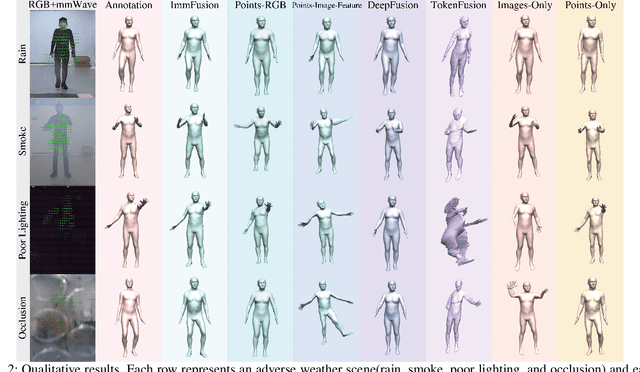

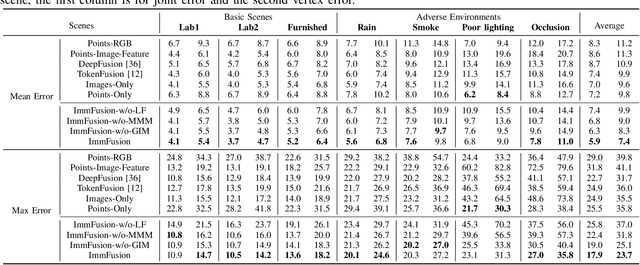
3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
MuVAM: A Multi-View Attention-based Model for Medical Visual Question Answering
Jul 07, 2021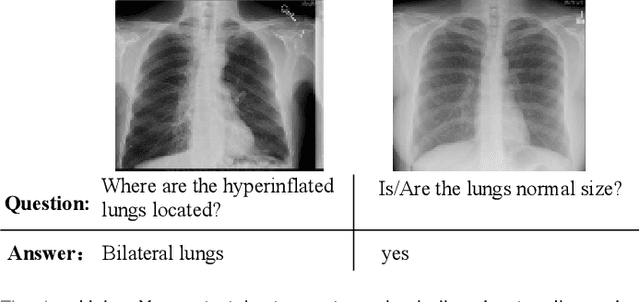
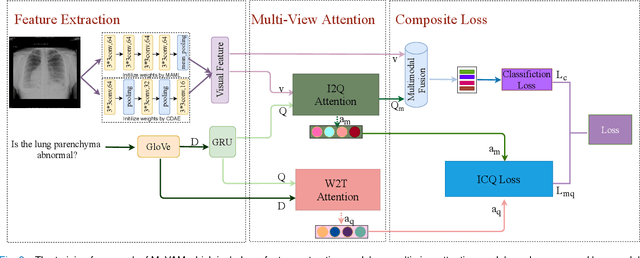
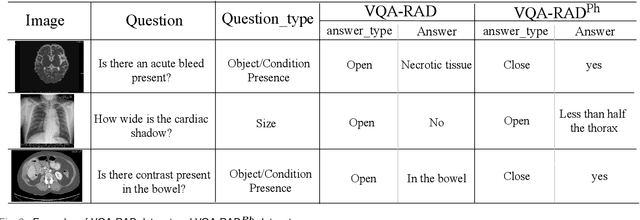
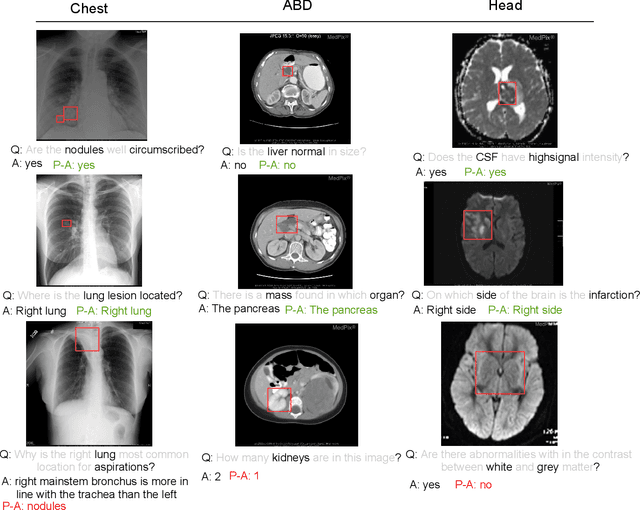
Medical Visual Question Answering (VQA) is a multi-modal challenging task widely considered by research communities of the computer vision and natural language processing. Since most current medical VQA models focus on visual content, ignoring the importance of text, this paper proposes a multi-view attention-based model(MuVAM) for medical visual question answering which integrates the high-level semantics of medical images on the basis of text description. Firstly, different methods are utilized to extract the features of the image and the question for the two modalities of vision and text. Secondly, this paper proposes a multi-view attention mechanism that include Image-to-Question (I2Q) attention and Word-to-Text (W2T) attention. Multi-view attention can correlate the question with image and word in order to better analyze the question and get an accurate answer. Thirdly, a composite loss is presented to predict the answer accurately after multi-modal feature fusion and improve the similarity between visual and textual cross-modal features. It consists of classification loss and image-question complementary (IQC) loss. Finally, for data errors and missing labels in the VQA-RAD dataset, we collaborate with medical experts to correct and complete this dataset and then construct an enhanced dataset, VQA-RADPh. The experiments on these two datasets show that the effectiveness of MuVAM surpasses the state-of-the-art method.