 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICON: Invariant Counterfactual Optimization with Neuro-Symbolic Priors for Text-Based Person Search
Jan 22, 2026Text-Based Person Search (TBPS) holds unique value in real-world surveillance bridging visual perception and language understanding, yet current paradigms utilizing pre-training models often fail to transfer effectively to complex open-world scenarios. The reliance on "Passive Observation" leads to multifaceted spurious correlations and spatial semantic misalignment, causing a lack of robustness against distribution shifts. To fundamentally resolve these defects, this paper proposes ICON (Invariant Counterfactual Optimization with Neuro-symbolic priors), a framework integrating causal and topological priors. First, we introduce Rule-Guided Spatial Intervention to strictly penalize sensitivity to bounding box noise, forcibly severing location shortcuts to achieve geometric invariance. Second, Counterfactual Context Disentanglement is implemented via semantic-driven background transplantation, compelling the model to ignore background interference for environmental independence. Then, we employ Saliency-Driven Semantic Regularization with adaptive masking to resolve local saliency bias and guarantee holistic completeness. Finally, Neuro-Symbolic Topological Alignment utilizes neuro-symbolic priors to constrain feature matching, ensuring activated regions are topologically consistent with human structural logic. Experimental results demonstrate that ICON not only maintains leading performance on standard benchmarks but also exhibits exceptional robustness against occlusion, background interference, and localization noise. This approach effectively advances the field by shifting from fitting statistical co-occurrences to learning causal invariance.
FlowCritic: Bridging Value Estimation with Flow Matching in Reinforcement Learning
Oct 26, 2025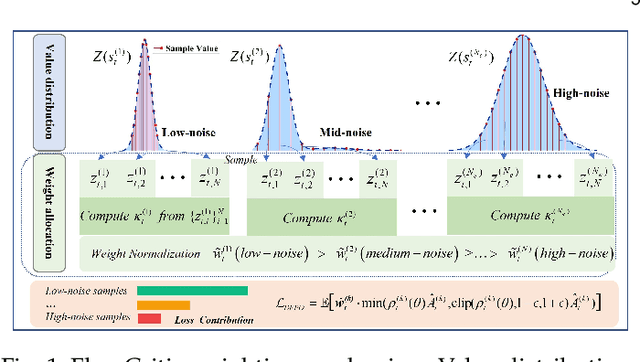
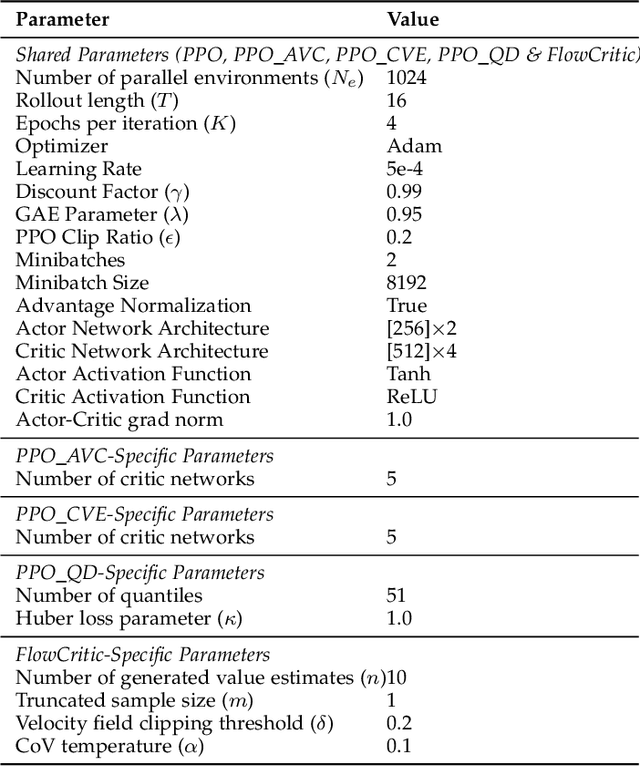
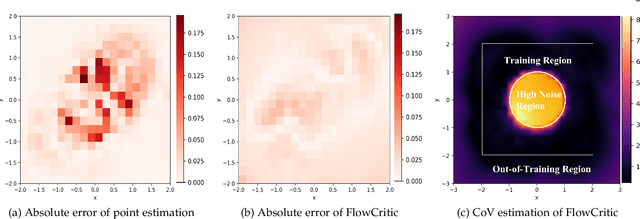
Reliable value estimation serves as the cornerstone of reinforcement learning (RL) by evaluating long-term returns and guiding policy improvement, significantly influencing the convergence speed and final performance. Existing works improve the reliability of value function estimation via multi-critic ensembles and distributional RL, yet the former merely combines multi point estimation without capturing distributional information, whereas the latter relies on discretization or quantile regression, limiting the expressiveness of complex value distributions. Inspired by flow matching's success in generative modeling, we propose a generative paradigm for value estimation, named FlowCritic. Departing from conventional regression for deterministic value prediction, FlowCritic leverages flow matching to model value distributions and generate samples for value estimation.
UAV-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UAV Imitation Learning
May 21, 2025Unmanned Aerial Vehicles (UAVs) are evolving into language-interactive platforms, enabling more intuitive forms of human-drone interaction. While prior works have primarily focused on high-level planning and long-horizon navigation, we shift attention to language-guided fine-grained trajectory control, where UAVs execute short-range, reactive flight behaviors in response to language instructions. We formalize this problem as the Flying-on-a-Word (Flow) task and introduce UAV imitation learning as an effective approach. In this framework, UAVs learn fine-grained control policies by mimicking expert pilot trajectories paired with atomic language instructions. To support this paradigm, we present UAV-Flow, the first real-world benchmark for language-conditioned, fine-grained UAV control. It includes a task formulation, a large-scale dataset collected in diverse environments, a deployable control framework, and a simulation suite for systematic evaluation. Our design enables UAVs to closely imitate the precise, expert-level flight trajectories of human pilots and supports direct deployment without sim-to-real gap. We conduct extensive experiments on UAV-Flow, benchmarking VLN and VLA paradigms. Results show that VLA models are superior to VLN baselines and highlight the critical role of spatial grounding in the fine-grained Flow setting.
Reservoir-enhanced Segment Anything Model for Subsurface Diagnosis
Apr 26, 2025Urban roads and infrastructure, vital to city operations, face growing threats from subsurface anomalies like cracks and cavities. Ground Penetrating Radar (GPR) effectively visualizes underground conditions employing electromagnetic (EM) waves; however, accurate anomaly detection via GPR remains challenging due to limited labeled data, varying subsurface conditions, and indistinct target boundaries. Although visually image-like, GPR data fundamentally represent EM waves, with variations within and between waves critical for identifying anomalies. Addressing these, we propose the Reservoir-enhanced Segment Anything Model (Res-SAM), an innovative framework exploiting both visual discernibility and wave-changing properties of GPR data. Res-SAM initially identifies apparent candidate anomaly regions given minimal prompts, and further refines them by analyzing anomaly-induced changing information within and between EM waves in local GPR data, enabling precise and complete anomaly region extraction and category determination. Real-world experiments demonstrate that Res-SAM achieves high detection accuracy (>85%) and outperforms state-of-the-art. Notably, Res-SAM requires only minimal accessible non-target data, avoids intensive training, and incorporates simple human interaction to enhance reliability. Our research provides a scalable, resource-efficient solution for rapid subsurface anomaly detection across diverse environments, improving urban safety monitoring while reducing manual effort and computational cost.
Generative Evaluation of Complex Reasoning in Large Language Models
Apr 03, 2025
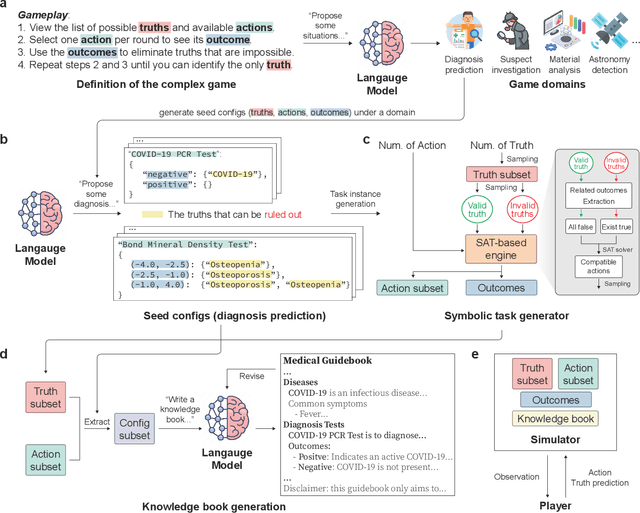
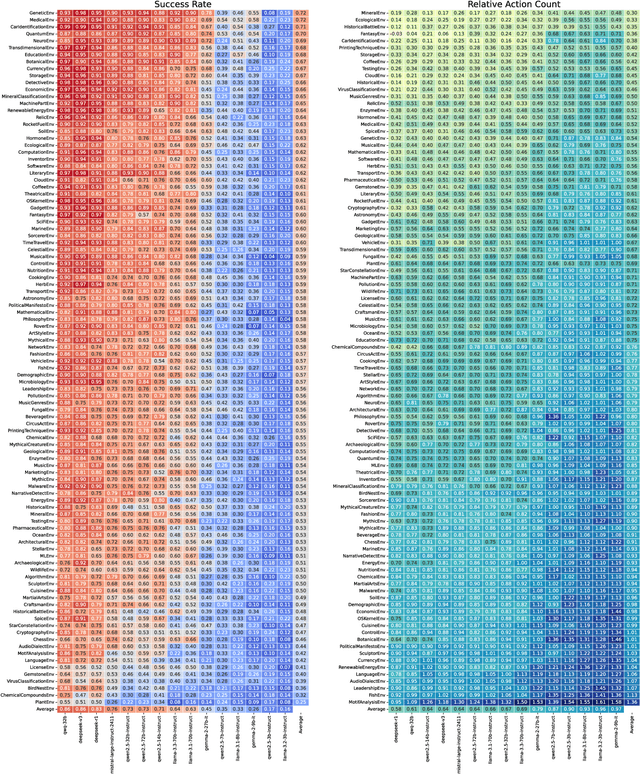
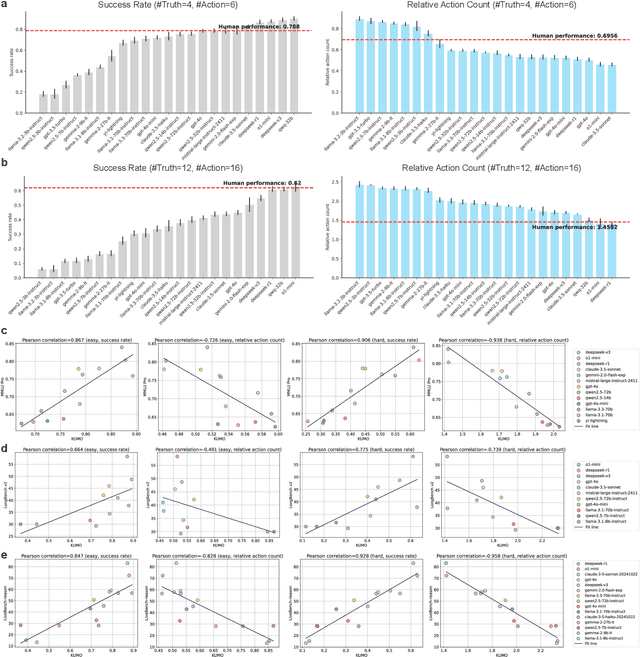
With powerful large language models (LLMs) demonstrating superhuman reasoning capabilities, a critical question arises: Do LLMs genuinely reason, or do they merely recall answers from their extensive, web-scraped training datasets? Publicly released benchmarks inevitably become contaminated once incorporated into subsequent LLM training sets, undermining their reliability as faithful assessments. To address this, we introduce KUMO, a generative evaluation framework designed specifically for assessing reasoning in LLMs. KUMO synergistically combines LLMs with symbolic engines to dynamically produce diverse, multi-turn reasoning tasks that are partially observable and adjustable in difficulty. Through an automated pipeline, KUMO continuously generates novel tasks across open-ended domains, compelling models to demonstrate genuine generalization rather than memorization. We evaluated 23 state-of-the-art LLMs on 5,000 tasks across 100 domains created by KUMO, benchmarking their reasoning abilities against university students. Our findings reveal that many LLMs have outperformed university-level performance on easy reasoning tasks, and reasoning-scaled LLMs reach university-level performance on complex reasoning challenges. Moreover, LLM performance on KUMO tasks correlates strongly with results on newly released real-world reasoning benchmarks, underscoring KUMO's value as a robust, enduring assessment tool for genuine LLM reasoning capabilities.
Glioma Multimodal MRI Analysis System for Tumor Layered Diagnosis via Multi-task Semi-supervised Learning
Jan 29, 2025



Gliomas are the most common primary tumors of the central nervous system. Multimodal MRI is widely used for the preliminary screening of gliomas and plays a crucial role in auxiliary diagnosis, therapeutic efficacy, and prognostic evaluation. Currently, the computer-aided diagnostic studies of gliomas using MRI have focused on independent analysis events such as tumor segmentation, grading, and radiogenomic classification, without studying inter-dependencies among these events. In this study, we propose a Glioma Multimodal MRI Analysis System (GMMAS) that utilizes a deep learning network for processing multiple events simultaneously, leveraging their inter-dependencies through an uncertainty-based multi-task learning architecture and synchronously outputting tumor region segmentation, glioma histological subtype, IDH mutation genotype, and 1p/19q chromosome disorder status. Compared with the reported single-task analysis models, GMMAS improves the precision across tumor layered diagnostic tasks. Additionally, we have employed a two-stage semi-supervised learning method, enhancing model performance by fully exploiting both labeled and unlabeled MRI samples. Further, by utilizing an adaptation module based on knowledge self-distillation and contrastive learning for cross-modal feature extraction, GMMAS exhibited robustness in situations of modality absence and revealed the differing significance of each MRI modal. Finally, based on the analysis outputs of the GMMAS, we created a visual and user-friendly platform for doctors and patients, introducing GMMAS-GPT to generate personalized prognosis evaluations and suggestions.
MTMT: Consolidating Multiple Thinking Modes to Form a Thought Tree for Strengthening LLM
Dec 05, 2024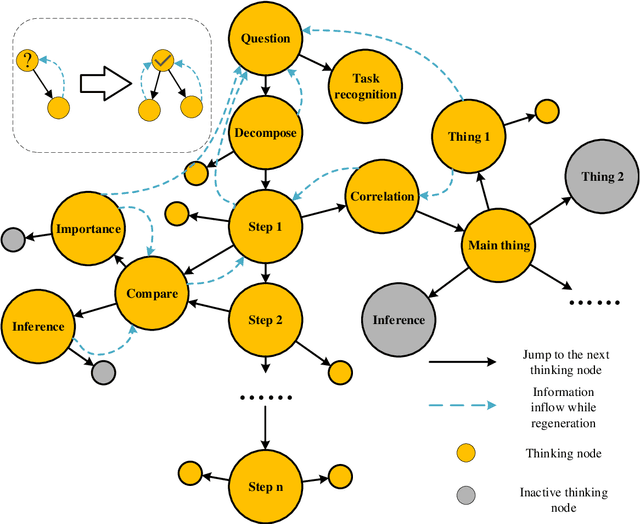
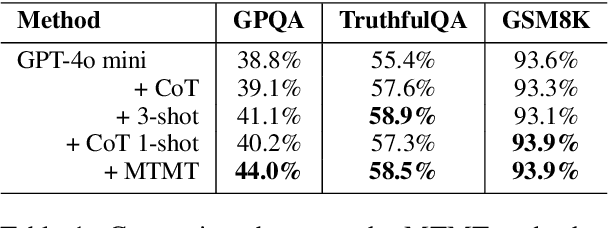
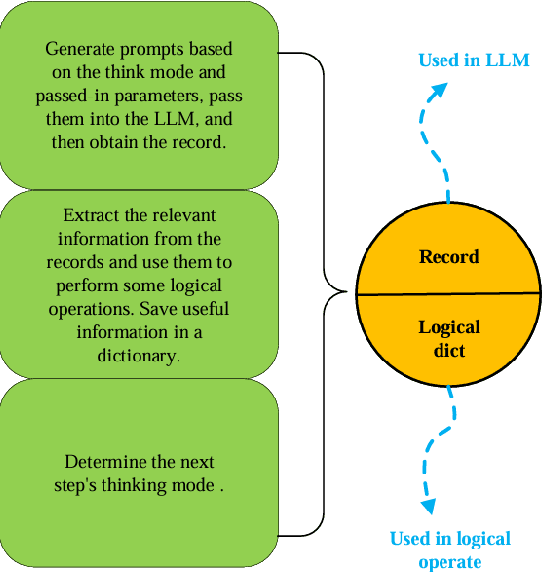
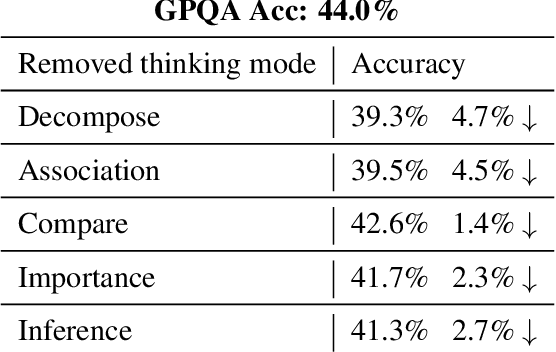
Large language models (LLMs) have shown limitations in tasks requiring complex logical reasoning and multi-step problem-solving. To address these challenges, researchers have employed carefully designed prompts and flowcharts, simulating human cognitive processes to enhance LLM performance, such as the Chain of Thought approach. In this paper, we introduce MTMT (Multi-thinking Modes Tree), a novel method that interacts with LLMs to construct a thought tree, simulating various advanced cognitive processes, including but not limited to association, counterfactual thinking, task decomposition, and comparison. By breaking down the original complex task into simpler sub-questions, MTMT facilitates easier problem-solving for LLMs, enabling more effective utilization of the latent knowledge within LLMs. We evaluate the performance of MTMT under different parameter configurations, using GPT-4o mini as the base model. Our results demonstrate that integrating multiple modes of thinking significantly enhances the ability of LLMs to handle complex tasks.
Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
Oct 10, 2024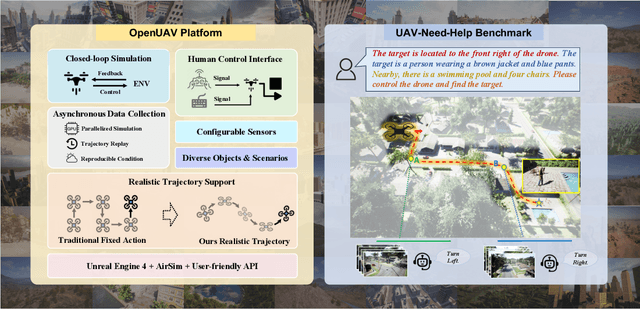
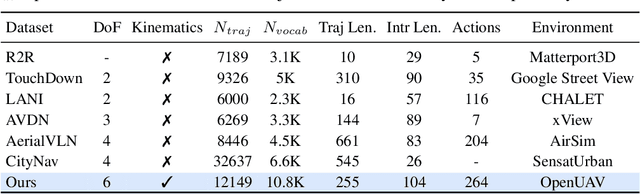
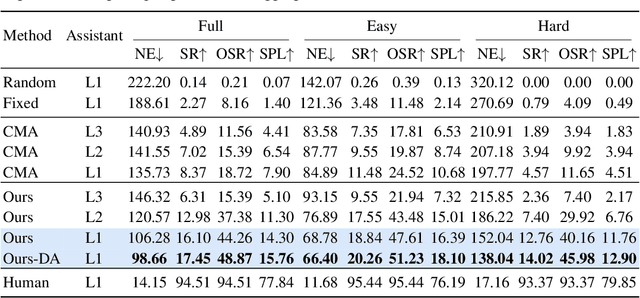
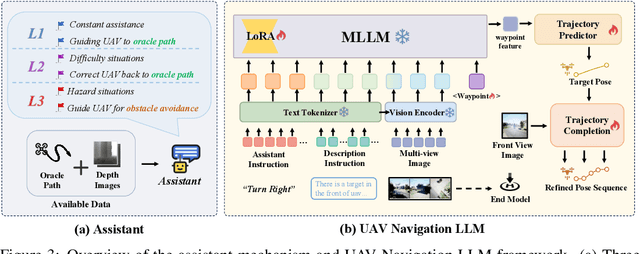
Developing agents capable of navigating to a target location based on language instructions and visual information, known as vision-language navigation (VLN), has attracted widespread interest. Most research has focused on ground-based agents, while UAV-based VLN remains relatively underexplored. Recent efforts in UAV vision-language navigation predominantly adopt ground-based VLN settings, relying on predefined discrete action spaces and neglecting the inherent disparities in agent movement dynamics and the complexity of navigation tasks between ground and aerial environments. To address these disparities and challenges, we propose solutions from three perspectives: platform, benchmark, and methodology. To enable realistic UAV trajectory simulation in VLN tasks, we propose the OpenUAV platform, which features diverse environments, realistic flight control, and extensive algorithmic support. We further construct a target-oriented VLN dataset consisting of approximately 12k trajectories on this platform, serving as the first dataset specifically designed for realistic UAV VLN tasks. To tackle the challenges posed by complex aerial environments, we propose an assistant-guided UAV object search benchmark called UAV-Need-Help, which provides varying levels of guidance information to help UAVs better accomplish realistic VLN tasks. We also propose a UAV navigation LLM that, given multi-view images, task descriptions, and assistant instructions, leverages the multimodal understanding capabilities of the MLLM to jointly process visual and textual information, and performs hierarchical trajectory generation. The evaluation results of our method significantly outperform the baseline models, while there remains a considerable gap between our results and those achieved by human operators, underscoring the challenge presented by the UAV-Need-Help task.
Real-time Detection and Auto focusing of Beam Profiles from Silicon Photonics Gratings using YOLO model
Sep 22, 2024



When observing the chip-to-free-space light beams from silicon photonics (SiPh) to free-space, manual adjustment of camera lens is often required to obtain a focused image of the light beams. In this letter, we demonstrated an auto-focusing system based on you-only-look-once (YOLO) model. The trained YOLO model exhibits high classification accuracy of 99.7% and high confidence level >0.95 when detecting light beams from SiPh gratings. A video demonstration of real-time light beam detection, real-time computation of beam width, and auto focusing of light beams are also included.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.