 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
PerfGuard: A Performance-Aware Agent for Visual Content Generation
Jan 30, 2026The advancement of Large Language Model (LLM)-powered agents has enabled automated task processing through reasoning and tool invocation capabilities. However, existing frameworks often operate under the idealized assumption that tool executions are invariably successful, relying solely on textual descriptions that fail to distinguish precise performance boundaries and cannot adapt to iterative tool updates. This gap introduces uncertainty in planning and execution, particularly in domains like visual content generation (AIGC), where nuanced tool performance significantly impacts outcomes. To address this, we propose PerfGuard, a performance-aware agent framework for visual content generation that systematically models tool performance boundaries and integrates them into task planning and scheduling. Our framework introduces three core mechanisms: (1) Performance-Aware Selection Modeling (PASM), which replaces generic tool descriptions with a multi-dimensional scoring system based on fine-grained performance evaluations; (2) Adaptive Preference Update (APU), which dynamically optimizes tool selection by comparing theoretical rankings with actual execution rankings; and (3) Capability-Aligned Planning Optimization (CAPO), which guides the planner to generate subtasks aligned with performance-aware strategies. Experimental comparisons against state-of-the-art methods demonstrate PerfGuard's advantages in tool selection accuracy, execution reliability, and alignment with user intent, validating its robustness and practical utility for complex AIGC tasks. The project code is available at https://github.com/FelixChan9527/PerfGuard.
Reframing Conversational Design in HRI: Deliberate Design with AI Scaffolds
Jan 17, 2026Large language models (LLMs) have enabled conversational robots to move beyond constrained dialogue toward free-form interaction. However, without context-specific adaptation, generic LLM outputs can be ineffective or inappropriate. This adaptation is often attempted through prompt engineering, which is non-intuitive and tedious. Moreover, predominant design practice in HRI relies on impression-based, trial-and-error refinement without structured methods or tools, making the process inefficient and inconsistent. To address this, we present the AI-Aided Conversation Engine (ACE), a system that supports the deliberate design of human-robot conversations. ACE contributes three key innovations: 1) an LLM-powered voice agent that scaffolds initial prompt creation to overcome the "blank page problem," 2) an annotation interface that enables the collection of granular and grounded feedback on conversational transcripts, and 3) using LLMs to translate user feedback into prompt refinements. We evaluated ACE through two user studies, examining both designs' experience and end users' interactions with robots designed using ACE. Results show that ACE facilitates the creation of robot behavior prompts with greater clarity and specificity, and that the prompts generated with ACE lead to higher-quality human-robot conversational interactions.
Rotate Your Character: Revisiting Video Diffusion Models for High-Quality 3D Character Generation
Jan 09, 2026Generating high-quality 3D characters from single images remains a significant challenge in digital content creation, particularly due to complex body poses and self-occlusion. In this paper, we present RCM (Rotate your Character Model), an advanced image-to-video diffusion framework tailored for high-quality novel view synthesis (NVS) and 3D character generation. Compared to existing diffusion-based approaches, RCM offers several key advantages: (1) transferring characters with any complex poses into a canonical pose, enabling consistent novel view synthesis across the entire viewing orbit, (2) high-resolution orbital video generation at 1024x1024 resolution, (3) controllable observation positions given different initial camera poses, and (4) multi-view conditioning supporting up to 4 input images, accommodating diverse user scenarios. Extensive experiments demonstrate that RCM outperforms state-of-the-art methods in both novel view synthesis and 3D generation quality.
Benchmarking neural surrogates on realistic spatiotemporal multiphysics flows
Dec 21, 2025Predicting multiphysics dynamics is computationally expensive and challenging due to the severe coupling of multi-scale, heterogeneous physical processes. While neural surrogates promise a paradigm shift, the field currently suffers from an "illusion of mastery", as repeatedly emphasized in top-tier commentaries: existing evaluations overly rely on simplified, low-dimensional proxies, which fail to expose the models' inherent fragility in realistic regimes. To bridge this critical gap, we present REALM (REalistic AI Learning for Multiphysics), a rigorous benchmarking framework designed to test neural surrogates on challenging, application-driven reactive flows. REALM features 11 high-fidelity datasets spanning from canonical multiphysics problems to complex propulsion and fire safety scenarios, alongside a standardized end-to-end training and evaluation protocol that incorporates multiphysics-aware preprocessing and a robust rollout strategy. Using this framework, we systematically benchmark over a dozen representative surrogate model families, including spectral operators, convolutional models, Transformers, pointwise operators, and graph/mesh networks, and identify three robust trends: (i) a scaling barrier governed jointly by dimensionality, stiffness, and mesh irregularity, leading to rapidly growing rollout errors; (ii) performance primarily controlled by architectural inductive biases rather than parameter count; and (iii) a persistent gap between nominal accuracy metrics and physically trustworthy behavior, where models with high correlations still miss key transient structures and integral quantities. Taken together, REALM exposes the limits of current neural surrogates on realistic multiphysics flows and offers a rigorous testbed to drive the development of next-generation physics-aware architectures.
Unifying Deep Predicate Invention with Pre-trained Foundation Models
Dec 19, 2025Long-horizon robotic tasks are hard due to continuous state-action spaces and sparse feedback. Symbolic world models help by decomposing tasks into discrete predicates that capture object properties and relations. Existing methods learn predicates either top-down, by prompting foundation models without data grounding, or bottom-up, from demonstrations without high-level priors. We introduce UniPred, a bilevel learning framework that unifies both. UniPred uses large language models (LLMs) to propose predicate effect distributions that supervise neural predicate learning from low-level data, while learned feedback iteratively refines the LLM hypotheses. Leveraging strong visual foundation model features, UniPred learns robust predicate classifiers in cluttered scenes. We further propose a predicate evaluation method that supports symbolic models beyond STRIPS assumptions. Across five simulated and one real-robot domains, UniPred achieves 2-4 times higher success rates than top-down methods and 3-4 times faster learning than bottom-up approaches, advancing scalable and flexible symbolic world modeling for robotics.
Cambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
Clone Deterministic 3D Worlds with Geometrically-Regularized World Models
Oct 30, 2025A world model is an internal model that simulates how the world evolves. Given past observations and actions, it predicts the future of both the embodied agent and its environment. Accurate world models are essential for enabling agents to think, plan, and reason effectively in complex, dynamic settings. Despite rapid progress, current world models remain brittle and degrade over long horizons. We argue that a central cause is representation quality: exteroceptive inputs (e.g., images) are high-dimensional, and lossy or entangled latents make dynamics learning unnecessarily hard. We therefore ask whether improving representation learning alone can substantially improve world-model performance. In this work, we take a step toward building a truly accurate world model by addressing a fundamental yet open problem: constructing a model that can fully clone and overfit to a deterministic 3D world. We propose Geometrically-Regularized World Models (GRWM), which enforces that consecutive points along a natural sensory trajectory remain close in latent representation space. This approach yields significantly improved latent representations that align closely with the true topology of the environment. GRWM is plug-and-play, requires only minimal architectural modification, scales with trajectory length, and is compatible with diverse latent generative backbones. Across deterministic 3D settings and long-horizon prediction tasks, GRWM significantly increases rollout fidelity and stability. Analyses show that its benefits stem from learning a latent manifold with superior geometric structure. These findings support a clear takeaway: improving representation learning is a direct and useful path to robust world models, delivering reliable long-horizon predictions without enlarging the dynamics module.
Taming VR Teleoperation and Learning from Demonstration for Multi-Task Bimanual Table Service Manipulation
Aug 21, 2025
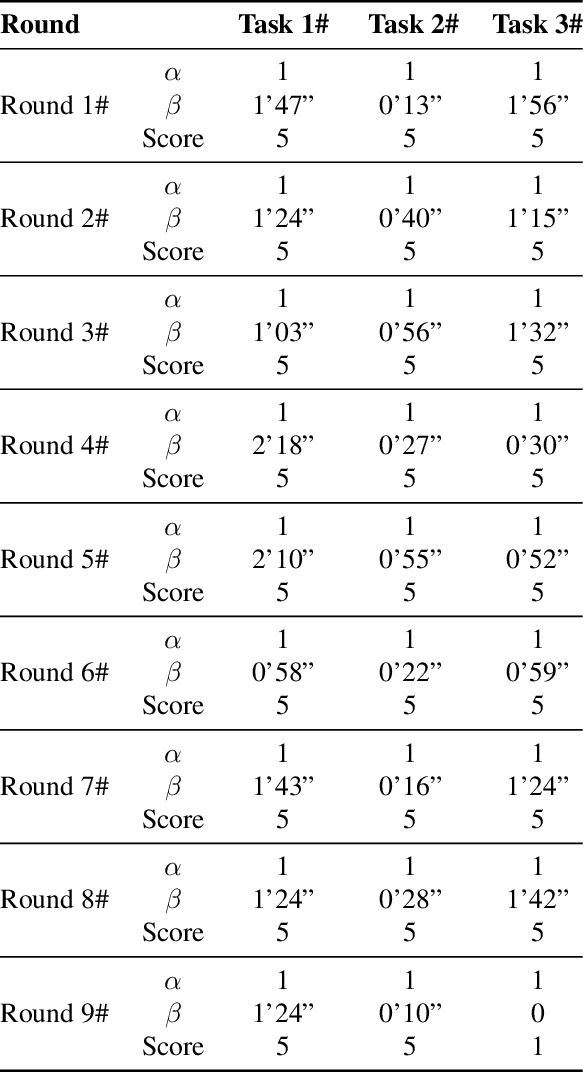


This technical report presents the champion solution of the Table Service Track in the ICRA 2025 What Bimanuals Can Do (WBCD) competition. We tackled a series of demanding tasks under strict requirements for speed, precision, and reliability: unfolding a tablecloth (deformable-object manipulation), placing a pizza into the container (pick-and-place), and opening and closing a food container with the lid. Our solution combines VR-based teleoperation and Learning from Demonstrations (LfD) to balance robustness and autonomy. Most subtasks were executed through high-fidelity remote teleoperation, while the pizza placement was handled by an ACT-based policy trained from 100 in-person teleoperated demonstrations with randomized initial configurations. By carefully integrating scoring rules, task characteristics, and current technical capabilities, our approach achieved both high efficiency and reliability, ultimately securing the first place in the competition.
Spatial 3D-LLM: Exploring Spatial Awareness in 3D Vision-Language Models
Jul 22, 2025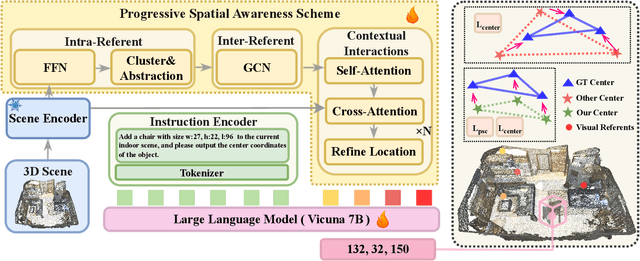

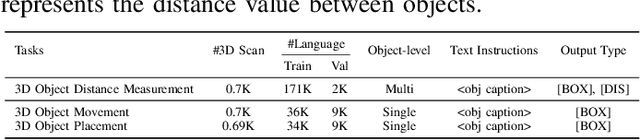
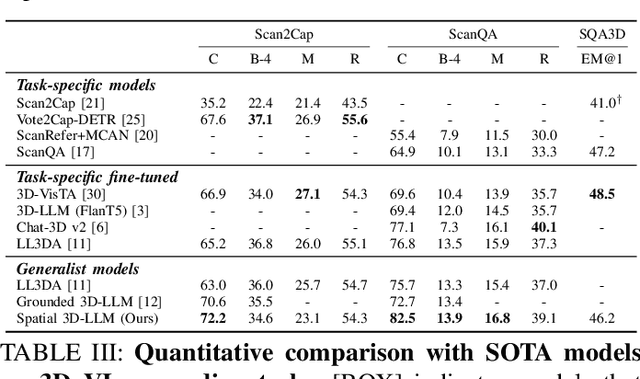
New era has unlocked exciting possibilities for extending Large Language Models (LLMs) to tackle 3D vision-language tasks. However, most existing 3D multimodal LLMs (MLLMs) rely on compressing holistic 3D scene information or segmenting independent objects to perform these tasks, which limits their spatial awareness due to insufficient representation of the richness inherent in 3D scenes. To overcome these limitations, we propose Spatial 3D-LLM, a 3D MLLM specifically designed to enhance spatial awareness for 3D vision-language tasks by enriching the spatial embeddings of 3D scenes. Spatial 3D-LLM integrates an LLM backbone with a progressive spatial awareness scheme that progressively captures spatial information as the perception field expands, generating location-enriched 3D scene embeddings to serve as visual prompts. Furthermore, we introduce two novel tasks: 3D object distance measurement and 3D layout editing, and construct a 3D instruction dataset, MODEL, to evaluate the model's spatial awareness capabilities. Experimental results demonstrate that Spatial 3D-LLM achieves state-of-the-art performance across a wide range of 3D vision-language tasks, revealing the improvements stemmed from our progressive spatial awareness scheme of mining more profound spatial information. Our code is available at https://github.com/bjshuyuan/Spatial-3D-LLM.