 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndroidGen: Building an Android Language Agent under Data Scarcity
Apr 27, 2025

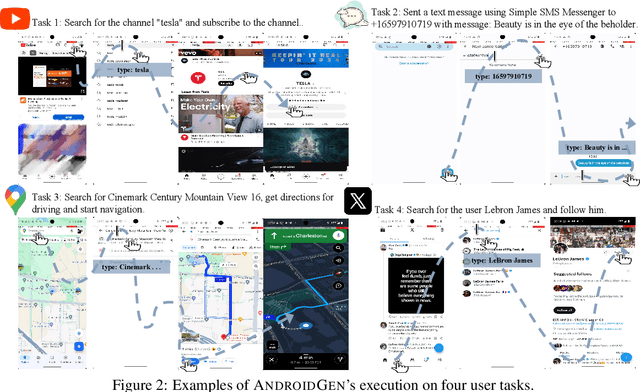
Large language models have opened up a world of possibilities for various NLP tasks, sparking optimism for the future. Despite their potential, LLMs have yet to be widely used as agents on real mobile devices. The main challenge is the need for high-quality data sources. Time constraints and labor intensity often hinder human annotation. On the other hand, existing LLMs exhibit inadequate completion rates and need a robust data filtration strategy. Given these challenges, we develop a framework called AndroidGen to enhance the capabilities of LLM-based agents under data scarcity. In addition, we leverage AndroidGen to collect trajectories given human tasks and train open-source LLMs on these trajectories to develop an open-source mobile agent without manually labeled trajectories. We extensively evaluate AndroidGen with AndroidWorld, AitW, and various popular applications, demonstrating its improvements and revealing potential areas for future improvement. Code, model, and data are available at https://github.com/THUDM/AndroidGen.
AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents
Oct 31, 2024



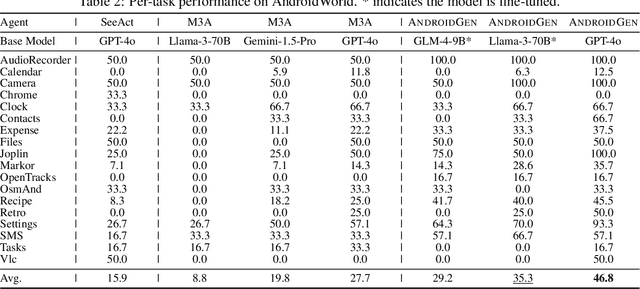
Autonomous agents have become increasingly important for interacting with the real world. Android agents, in particular, have been recently a frequently-mentioned interaction method. However, existing studies for training and evaluating Android agents lack systematic research on both open-source and closed-source models. In this work, we propose AndroidLab as a systematic Android agent framework. It includes an operation environment with different modalities, action space, and a reproducible benchmark. It supports both large language models (LLMs) and multimodal models (LMMs) in the same action space. AndroidLab benchmark includes predefined Android virtual devices and 138 tasks across nine apps built on these devices. By using the AndroidLab environment, we develop an Android Instruction dataset and train six open-source LLMs and LMMs, lifting the average success rates from 4.59\% to 21.50\% for LLMs and from 1.93\% to 13.28\% for LMMs. AndroidLab is open-sourced and publicly available at \url{https://github.com/THUDM/Android-Lab}.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024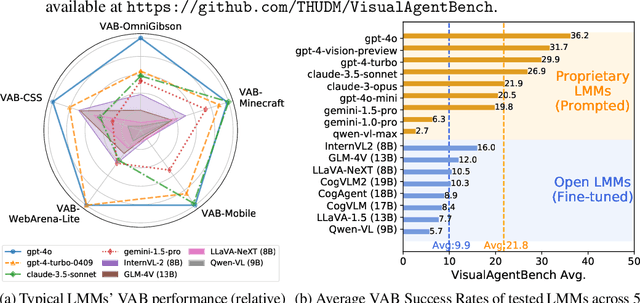
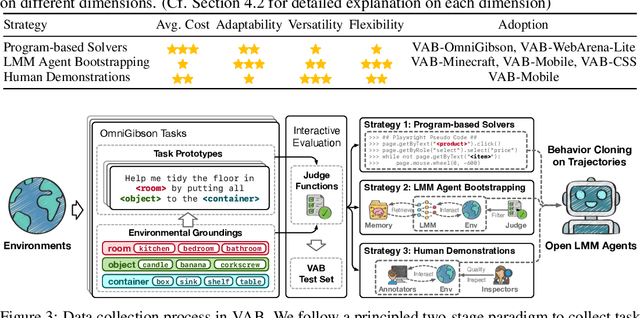
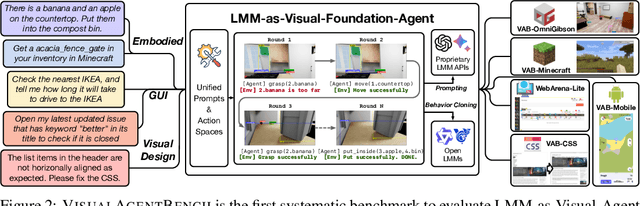
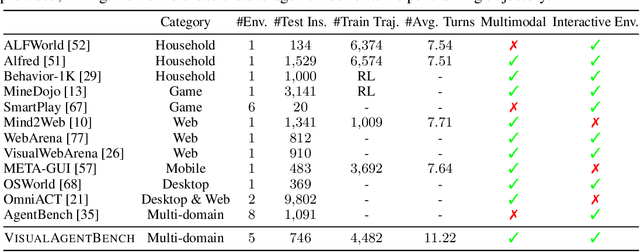
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024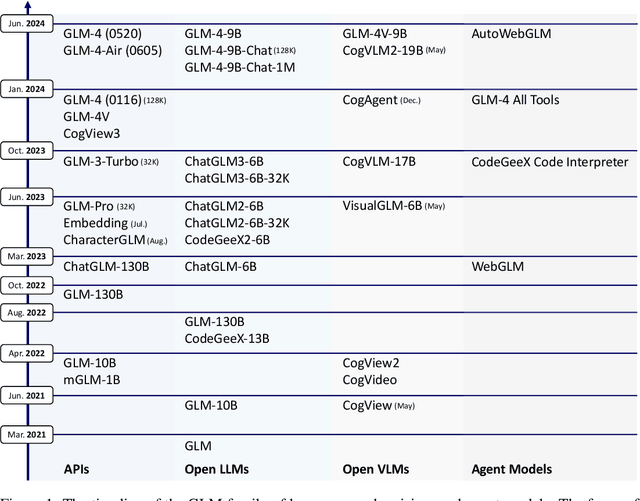
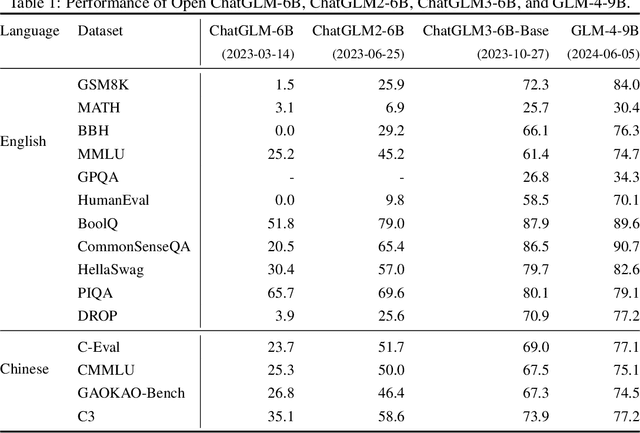
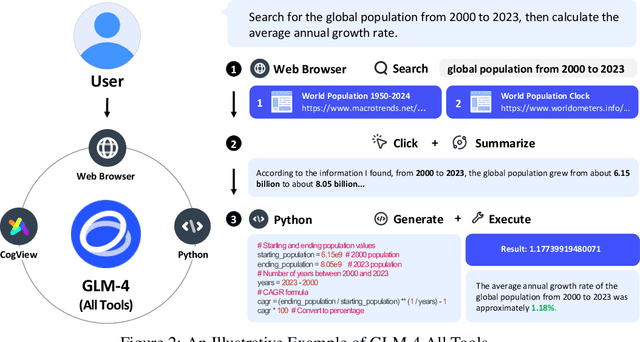
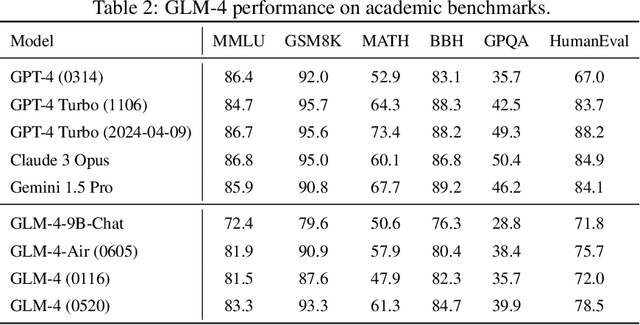
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts
May 07, 2024Large language models (LLMs) have manifested strong ability to generate codes for productive activities. However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are predominantly oriented towards introductory tasks on algorithm and data science, insufficiently satisfying challenging requirements prevalent in real-world coding. To fill this gap, we propose NaturalCodeBench (NCB), a challenging code benchmark designed to mirror the complexity and variety of scenarios in real coding tasks. NCB comprises 402 high-quality problems in Python and Java, meticulously selected from natural user queries from online coding services, covering 6 different domains. Noting the extraordinary difficulty in creating testing cases for real-world queries, we also introduce a semi-automated pipeline to enhance the efficiency of test case construction. Comparing with manual solutions, it achieves an efficiency increase of more than 4 times. Our systematic experiments on 39 LLMs find that performance gaps on NCB between models with close HumanEval scores could still be significant, indicating a lack of focus on practical code synthesis scenarios or over-specified optimization on HumanEval. On the other hand, even the best-performing GPT-4 is still far from satisfying on NCB. The evaluation toolkit and development set are available at https://github.com/THUDM/NaturalCodeBench.
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023



Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench