 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
Nov 04, 2024



Large language models (LLMs) have shown remarkable potential as autonomous agents, particularly in web-based tasks. However, existing LLM web agents heavily rely on expensive proprietary LLM APIs, while open LLMs lack the necessary decision-making capabilities. This paper introduces WebRL, a self-evolving online curriculum reinforcement learning framework designed to train high-performance web agents using open LLMs. WebRL addresses three key challenges in building LLM web agents, including the scarcity of training tasks, sparse feedback signals, and policy distribution drift in online learning. Specifically, WebRL incorporates 1) a self-evolving curriculum that generates new tasks from unsuccessful attempts, 2) a robust outcome-supervised reward model (ORM), and 3) adaptive reinforcement learning strategies to ensure consistent improvements. We apply WebRL to transform open Llama-3.1 and GLM-4 models into proficient web agents. On WebArena-Lite, WebRL improves the success rate of Llama-3.1-8B from 4.8% to 42.4%, and from 6.1% to 43% for GLM-4-9B. These open models significantly surpass the performance of GPT-4-Turbo (17.6%) and GPT-4o (13.9%) and outperform previous state-of-the-art web agents trained on open LLMs (AutoWebGLM, 18.2%). Our findings demonstrate WebRL's effectiveness in bridging the gap between open and proprietary LLM-based web agents, paving the way for more accessible and powerful autonomous web interaction systems.
AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents
Oct 31, 2024



Autonomous agents have become increasingly important for interacting with the real world. Android agents, in particular, have been recently a frequently-mentioned interaction method. However, existing studies for training and evaluating Android agents lack systematic research on both open-source and closed-source models. In this work, we propose AndroidLab as a systematic Android agent framework. It includes an operation environment with different modalities, action space, and a reproducible benchmark. It supports both large language models (LLMs) and multimodal models (LMMs) in the same action space. AndroidLab benchmark includes predefined Android virtual devices and 138 tasks across nine apps built on these devices. By using the AndroidLab environment, we develop an Android Instruction dataset and train six open-source LLMs and LMMs, lifting the average success rates from 4.59\% to 21.50\% for LLMs and from 1.93\% to 13.28\% for LMMs. AndroidLab is open-sourced and publicly available at \url{https://github.com/THUDM/Android-Lab}.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024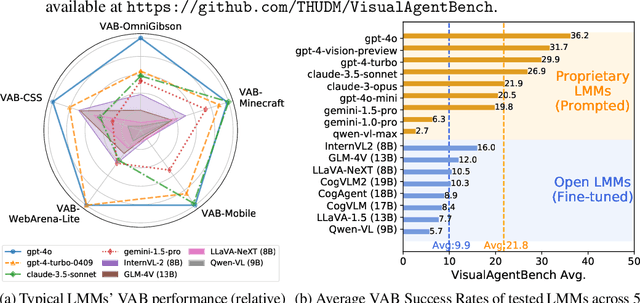
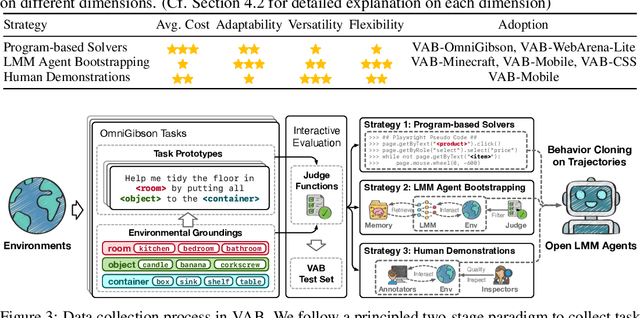
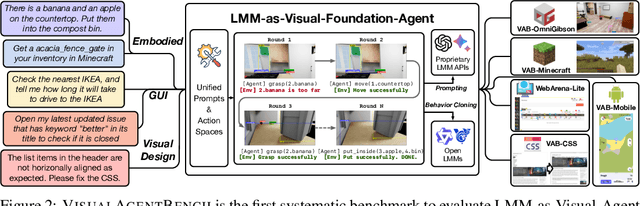
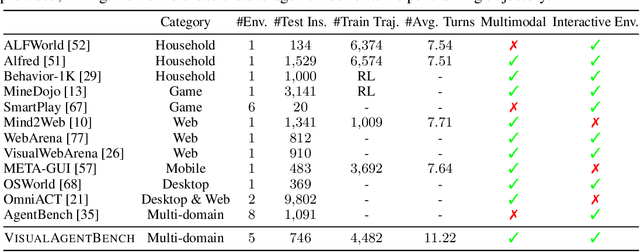
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.