 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Quantum-Enhanced Multi-Task Learning with Learnable Weighting for Pharmacokinetic and Toxicity Prediction
Sep 04, 2025Prediction for ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) plays a crucial role in drug discovery and development, accelerating the screening and optimization of new drugs. Existing methods primarily rely on single-task learning (STL), which often fails to fully exploit the complementarities between tasks. Besides, it requires more computational resources while training and inference of each task independently. To address these issues, we propose a new unified Quantum-enhanced and task-Weighted Multi-Task Learning (QW-MTL) framework, specifically designed for ADMET classification tasks. Built upon the Chemprop-RDKit backbone, QW-MTL adopts quantum chemical descriptors to enrich molecular representations with additional information about the electronic structure and interactions. Meanwhile, it introduces a novel exponential task weighting scheme that combines dataset-scale priors with learnable parameters to achieve dynamic loss balancing across tasks. To the best of our knowledge, this is the first work to systematically conduct joint multi-task training across all 13 Therapeutics Data Commons (TDC) classification benchmarks, using leaderboard-style data splits to ensure a standardized and realistic evaluation setting. Extensive experimental results show that QW-MTL significantly outperforms single-task baselines on 12 out of 13 tasks, achieving high predictive performance with minimal model complexity and fast inference, demonstrating the effectiveness and efficiency of multi-task molecular learning enhanced by quantum-informed features and adaptive task weighting.
An Interpretable Multi-Plane Fusion Framework With Kolmogorov-Arnold Network Guided Attention Enhancement for Alzheimer's Disease Diagnosis
Aug 08, 2025Alzheimer's disease (AD) is a progressive neurodegenerative disorder that severely impairs cognitive function and quality of life. Timely intervention in AD relies heavily on early and precise diagnosis, which remains challenging due to the complex and subtle structural changes in the brain. Most existing deep learning methods focus only on a single plane of structural magnetic resonance imaging (sMRI) and struggle to accurately capture the complex and nonlinear relationships among pathological regions of the brain, thus limiting their ability to precisely identify atrophic features. To overcome these limitations, we propose an innovative framework, MPF-KANSC, which integrates multi-plane fusion (MPF) for combining features from the coronal, sagittal, and axial planes, and a Kolmogorov-Arnold Network-guided spatial-channel attention mechanism (KANSC) to more effectively learn and represent sMRI atrophy features. Specifically, the proposed model enables parallel feature extraction from multiple anatomical planes, thus capturing more comprehensive structural information. The KANSC attention mechanism further leverages a more flexible and accurate nonlinear function approximation technique, facilitating precise identification and localization of disease-related abnormalities. Experiments on the ADNI dataset confirm that the proposed MPF-KANSC achieves superior performance in AD diagnosis. Moreover, our findings provide new evidence of right-lateralized asymmetry in subcortical structural changes during AD progression, highlighting the model's promising interpretability.
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
Nov 04, 2024



Large language models (LLMs) have shown remarkable potential as autonomous agents, particularly in web-based tasks. However, existing LLM web agents heavily rely on expensive proprietary LLM APIs, while open LLMs lack the necessary decision-making capabilities. This paper introduces WebRL, a self-evolving online curriculum reinforcement learning framework designed to train high-performance web agents using open LLMs. WebRL addresses three key challenges in building LLM web agents, including the scarcity of training tasks, sparse feedback signals, and policy distribution drift in online learning. Specifically, WebRL incorporates 1) a self-evolving curriculum that generates new tasks from unsuccessful attempts, 2) a robust outcome-supervised reward model (ORM), and 3) adaptive reinforcement learning strategies to ensure consistent improvements. We apply WebRL to transform open Llama-3.1 and GLM-4 models into proficient web agents. On WebArena-Lite, WebRL improves the success rate of Llama-3.1-8B from 4.8% to 42.4%, and from 6.1% to 43% for GLM-4-9B. These open models significantly surpass the performance of GPT-4-Turbo (17.6%) and GPT-4o (13.9%) and outperform previous state-of-the-art web agents trained on open LLMs (AutoWebGLM, 18.2%). Our findings demonstrate WebRL's effectiveness in bridging the gap between open and proprietary LLM-based web agents, paving the way for more accessible and powerful autonomous web interaction systems.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024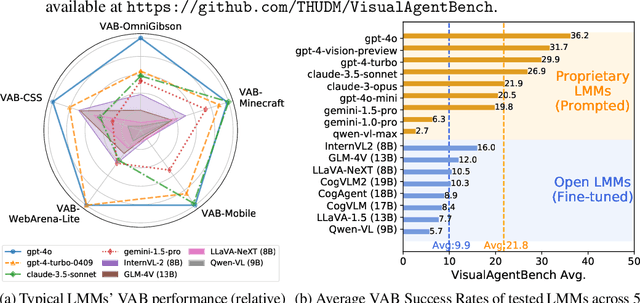
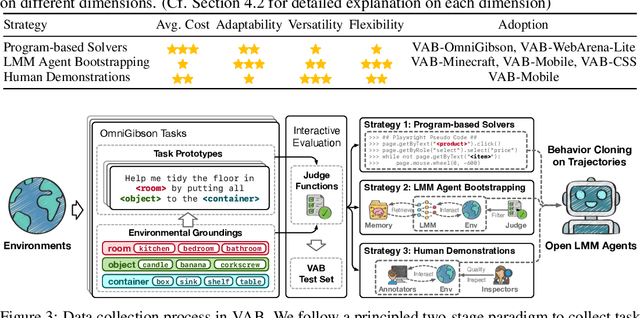
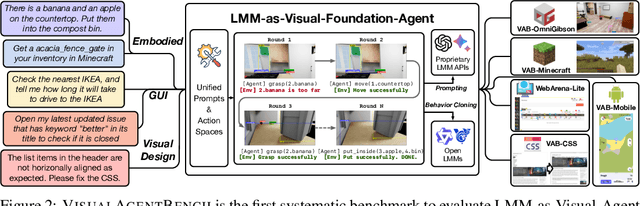
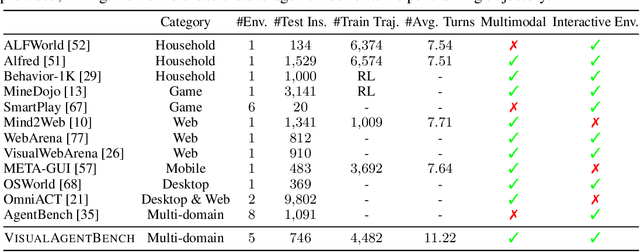
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024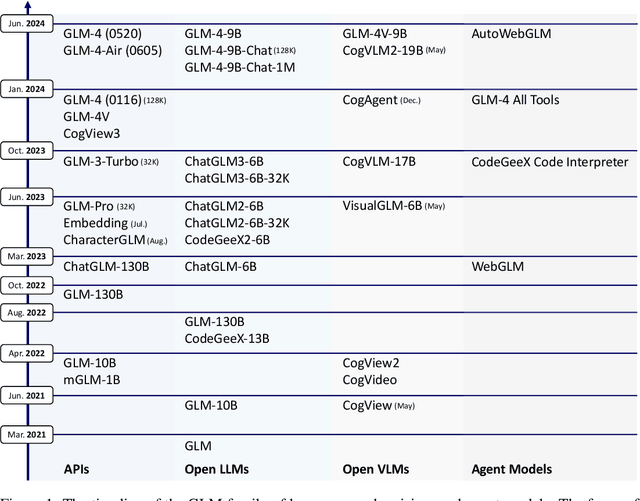
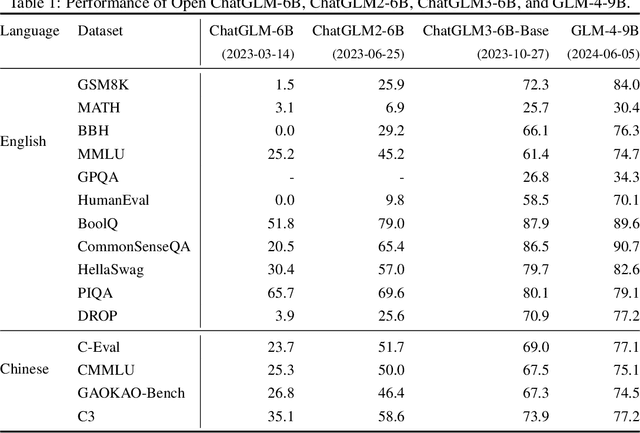
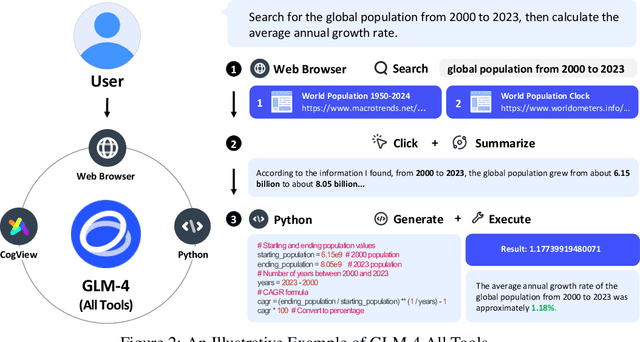
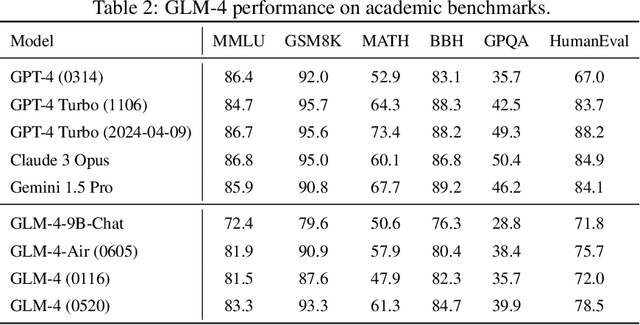
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.