 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs
Feb 03, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key approach for enhancing LLM reasoning.However, standard frameworks like Group Relative Policy Optimization (GRPO) typically employ a uniform rollout budget, leading to resource inefficiency. Moreover, existing adaptive methods often rely on instance-level metrics, such as task pass rates, failing to capture the model's dynamic learning state. To address these limitations, we propose CoBA-RL, a reinforcement learning algorithm designed to adaptively allocate rollout budgets based on the model's evolving capability. Specifically, CoBA-RL utilizes a Capability-Oriented Value function to map tasks to their potential training gains and employs a heap-based greedy strategy to efficiently self-calibrate the distribution of computational resources to samples with high training value. Extensive experiments demonstrate that our approach effectively orchestrates the trade-off between exploration and exploitation, delivering consistent generalization improvements across multiple challenging benchmarks. These findings underscore that quantifying sample training value and optimizing budget allocation are pivotal for advancing LLM post-training efficiency.
MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
Jan 29, 2026Long-horizon agentic reasoning necessitates effectively compressing growing interaction histories into a limited context window. Most existing memory systems serialize history as text, where token-level cost is uniform and scales linearly with length, often spending scarce budget on low-value details. To this end, we introduce MemOCR, a multimodal memory agent that improves long-horizon reasoning under tight context budgets by allocating memory space with adaptive information density through visual layout. Concretely, MemOCR maintains a structured rich-text memory (e.g., headings, highlights) and renders it into an image that the agent consults for memory access, visually prioritizing crucial evidence while aggressively compressing auxiliary details. To ensure robustness across varying memory budgets, we train MemOCR with reinforcement learning under budget-aware objectives that expose the agent to diverse compression levels. Across long-context multi-hop and single-hop question-answering benchmarks, MemOCR outperforms strong text-based baselines and achieves more effective context utilization under extreme budgets.
FedRD: Reducing Divergences for Generalized Federated Learning via Heterogeneity-aware Parameter Guidance
Jan 28, 2026Heterogeneous federated learning (HFL) aims to ensure effective and privacy-preserving collaboration among different entities. As newly joined clients require significant adjustments and additional training to align with the existing system, the problem of generalizing federated learning models to unseen clients under heterogeneous data has become progressively crucial. Consequently, we highlight two unsolved challenging issues in federated domain generalization: Optimization Divergence and Performance Divergence. To tackle the above challenges, we propose FedRD, a novel heterogeneity-aware federated learning algorithm that collaboratively utilizes parameter-guided global generalization aggregation and local debiased classification to reduce divergences, aiming to obtain an optimal global model for participating and unseen clients. Extensive experiments on public multi-domain datasets demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
FedCCA: Client-Centric Adaptation against Data Heterogeneity in Federated Learning on IoT Devices
Jan 25, 2026With the rapid development of the Internet of Things (IoT), AI model training on private data such as human sensing data is highly desired. Federated learning (FL) has emerged as a privacy-preserving distributed training framework for this purpuse. However, the data heterogeneity issue among IoT devices can significantly degrade the model performance and convergence speed in FL. Existing approaches limit in fixed client selection and aggregation on cloud server, making the privacy-preserving extraction of client-specific information during local training challenging. To this end, we propose Client-Centric Adaptation federated learning (FedCCA), an algorithm that optimally utilizes client-specific knowledge to learn a unique model for each client through selective adaptation, aiming to alleviate the influence of data heterogeneity. Specifically, FedCCA employs dynamic client selection and adaptive aggregation based on the additional client-specific encoder. To enhance multi-source knowledge transfer, we adopt an attention-based global aggregation strategy. We conducted extensive experiments on diverse datasets to assess the efficacy of FedCCA. The experimental results demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
PASTA: A Scalable Framework for Multi-Policy AI Compliance Evaluation
Jan 16, 2026AI compliance is becoming increasingly critical as AI systems grow more powerful and pervasive. Yet the rapid expansion of AI policies creates substantial burdens for resource-constrained practitioners lacking policy expertise. Existing approaches typically address one policy at a time, making multi-policy compliance costly. We present PASTA, a scalable compliance tool integrating four innovations: (1) a comprehensive model-card format supporting descriptive inputs across development stages; (2) a policy normalization scheme; (3) an efficient LLM-powered pairwise evaluation engine with cost-saving strategies; and (4) an interface delivering interpretable evaluations via compliance heatmaps and actionable recommendations. Expert evaluation shows PASTA's judgments closely align with human experts ($ρ\geq .626$). The system evaluates five major policies in under two minutes at approximately \$3. A user study (N = 12) confirms practitioners found outputs easy-to-understand and actionable, introducing a novel framework for scalable automated AI governance.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
TCDE: Topic-Centric Dual Expansion of Queries and Documents with Large Language Models for Information Retrieval
Dec 19, 2025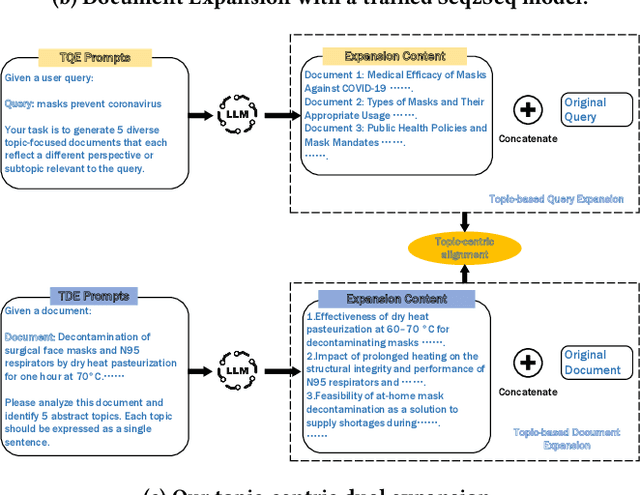

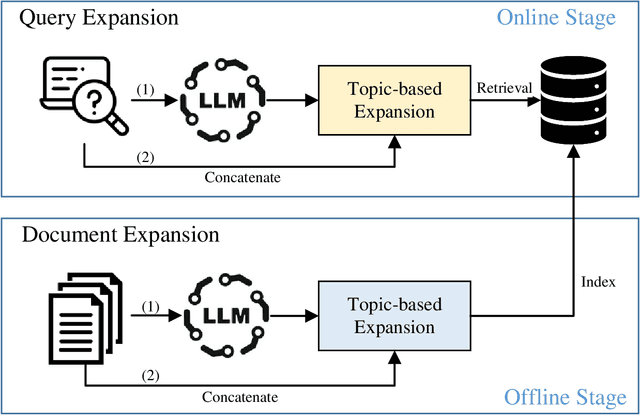

Query Expansion (QE) enriches queries and Document Expansion (DE) enriches documents, and these two techniques are often applied separately. However, such separate application may lead to semantic misalignment between the expanded queries (or documents) and their relevant documents (or queries). To address this serious issue, we propose TCDE, a dual expansion strategy that leverages large language models (LLMs) for topic-centric enrichment on both queries and documents. In TCDE, we design two distinct prompt templates for processing each query and document. On the query side, an LLM is guided to identify distinct sub-topics within each query and generate a focused pseudo-document for each sub-topic. On the document side, an LLM is guided to distill each document into a set of core topic sentences. The resulting outputs are used to expand the original query and document. This topic-centric dual expansion process establishes semantic bridges between queries and their relevant documents, enabling better alignment for downstream retrieval models. Experiments on two challenging benchmarks, TREC Deep Learning and BEIR, demonstrate that TCDE achieves substantial improvements over strong state-of-the-art expansion baselines. In particular, on dense retrieval tasks, it outperforms several state-of-the-art methods, with a relative improvement of 2.8\% in NDCG@10 on the SciFact dataset. Experimental results validate the effectiveness of our topic-centric and dual expansion strategy.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Continuous Vision-Language-Action Co-Learning with Semantic-Physical Alignment for Behavioral Cloning
Nov 18, 2025
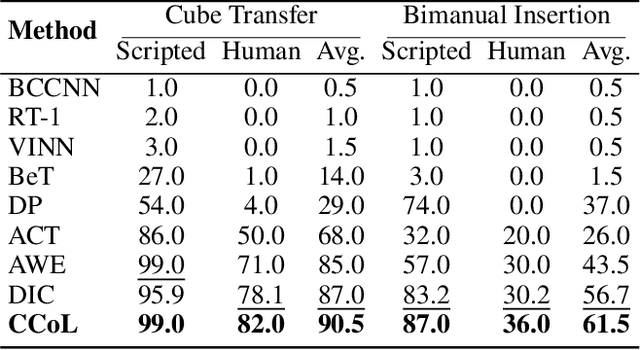


Language-conditioned manipulation facilitates human-robot interaction via behavioral cloning (BC), which learns control policies from human demonstrations and serves as a cornerstone of embodied AI. Overcoming compounding errors in sequential action decisions remains a central challenge to improving BC performance. Existing approaches mitigate compounding errors through data augmentation, expressive representation, or temporal abstraction. However, they suffer from physical discontinuities and semantic-physical misalignment, leading to inaccurate action cloning and intermittent execution. In this paper, we present Continuous vision-language-action Co-Learning with Semantic-Physical Alignment (CCoL), a novel BC framework that ensures temporally consistent execution and fine-grained semantic grounding. It generates robust and smooth action execution trajectories through continuous co-learning across vision, language, and proprioceptive inputs (e.g., robot internal states). Meanwhile, we anchor language semantics to visuomotor representations by a bidirectional cross-attention to learn contextual information for action generation, successfully overcoming the problem of semantic-physical misalignment. Extensive experiments show that CCoL achieves an average 8.0% relative improvement across three simulation suites, with up to 19.2% relative gain in human-demonstrated bimanual insertion tasks. Real-world tests on a 7-DoF robot further confirm CCoL's generalization under unseen and noisy object states.
BSO: Binary Spiking Online Optimization Algorithm
Nov 16, 2025Binary Spiking Neural Networks (BSNNs) offer promising efficiency advantages for resource-constrained computing. However, their training algorithms often require substantial memory overhead due to latent weights storage and temporal processing requirements. To address this issue, we propose Binary Spiking Online (BSO) optimization algorithm, a novel online training algorithm that significantly reduces training memory. BSO directly updates weights through flip signals under the online training framework. These signals are triggered when the product of gradient momentum and weights exceeds a threshold, eliminating the need for latent weights during training. To enhance performance, we propose T-BSO, a temporal-aware variant that leverages the inherent temporal dynamics of BSNNs by capturing gradient information across time steps for adaptive threshold adjustment. Theoretical analysis establishes convergence guarantees for both BSO and T-BSO, with formal regret bounds characterizing their convergence rates. Extensive experiments demonstrate that both BSO and T-BSO achieve superior optimization performance compared to existing training methods for BSNNs. The codes are available at https://github.com/hamings1/BSO.