 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Provably Improve Return Conditioned Supervised Learning?
Jun 10, 2025



In sequential decision-making problems, Return-Conditioned Supervised Learning (RCSL) has gained increasing recognition for its simplicity and stability in modern decision-making tasks. Unlike traditional offline reinforcement learning (RL) algorithms, RCSL frames policy learning as a supervised learning problem by taking both the state and return as input. This approach eliminates the instability often associated with temporal difference (TD) learning in offline RL. However, RCSL has been criticized for lacking the stitching property, meaning its performance is inherently limited by the quality of the policy used to generate the offline dataset. To address this limitation, we propose a principled and simple framework called Reinforced RCSL. The key innovation of our framework is the introduction of a concept we call the in-distribution optimal return-to-go. This mechanism leverages our policy to identify the best achievable in-dataset future return based on the current state, avoiding the need for complex return augmentation techniques. Our theoretical analysis demonstrates that Reinforced RCSL can consistently outperform the standard RCSL approach. Empirical results further validate our claims, showing significant performance improvements across a range of benchmarks.
Federated In-Context Learning: Iterative Refinement for Improved Answer Quality
Jun 09, 2025For question-answering (QA) tasks, in-context learning (ICL) enables language models to generate responses without modifying their parameters by leveraging examples provided in the input. However, the effectiveness of ICL heavily depends on the availability of high-quality examples, which are often scarce due to data privacy constraints, annotation costs, and distribution disparities. A natural solution is to utilize examples stored on client devices, but existing approaches either require transmitting model parameters - incurring significant communication overhead - or fail to fully exploit local datasets, limiting their effectiveness. To address these challenges, we propose Federated In-Context Learning (Fed-ICL), a general framework that enhances ICL through an iterative, collaborative process. Fed-ICL progressively refines responses by leveraging multi-round interactions between clients and a central server, improving answer quality without the need to transmit model parameters. We establish theoretical guarantees for the convergence of Fed-ICL and conduct extensive experiments on standard QA benchmarks, demonstrating that our proposed approach achieves strong performance while maintaining low communication costs.
Towards Agentic Recommender Systems in the Era of Multimodal Large Language Models
Mar 20, 2025Recent breakthroughs in Large Language Models (LLMs) have led to the emergence of agentic AI systems that extend beyond the capabilities of standalone models. By empowering LLMs to perceive external environments, integrate multimodal information, and interact with various tools, these agentic systems exhibit greater autonomy and adaptability across complex tasks. This evolution brings new opportunities to recommender systems (RS): LLM-based Agentic RS (LLM-ARS) can offer more interactive, context-aware, and proactive recommendations, potentially reshaping the user experience and broadening the application scope of RS. Despite promising early results, fundamental challenges remain, including how to effectively incorporate external knowledge, balance autonomy with controllability, and evaluate performance in dynamic, multimodal settings. In this perspective paper, we first present a systematic analysis of LLM-ARS: (1) clarifying core concepts and architectures; (2) highlighting how agentic capabilities -- such as planning, memory, and multimodal reasoning -- can enhance recommendation quality; and (3) outlining key research questions in areas such as safety, efficiency, and lifelong personalization. We also discuss open problems and future directions, arguing that LLM-ARS will drive the next wave of RS innovation. Ultimately, we foresee a paradigm shift toward intelligent, autonomous, and collaborative recommendation experiences that more closely align with users' evolving needs and complex decision-making processes.
Quantum Diffusion Models for Few-Shot Learning
Nov 06, 2024



Modern quantum machine learning (QML) methods involve the variational optimization of parameterized quantum circuits on training datasets, followed by predictions on testing datasets. Most state-of-the-art QML algorithms currently lack practical advantages due to their limited learning capabilities, especially in few-shot learning tasks. In this work, we propose three new frameworks employing quantum diffusion model (QDM) as a solution for the few-shot learning: label-guided generation inference (LGGI); label-guided denoising inference (LGDI); and label-guided noise addition inference (LGNAI). Experimental results demonstrate that our proposed algorithms significantly outperform existing methods.
Return Augmented Decision Transformer for Off-Dynamics Reinforcement Learning
Oct 30, 2024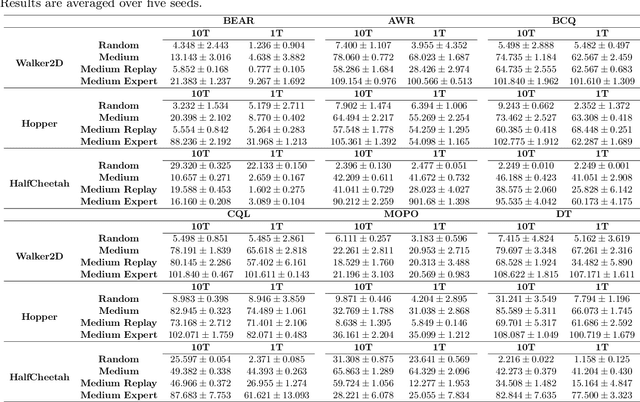
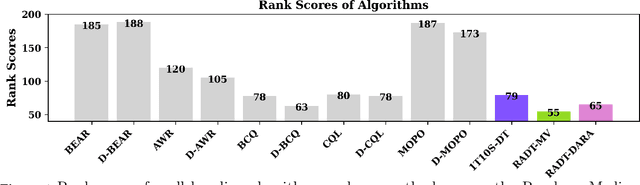


We study offline off-dynamics reinforcement learning (RL) to utilize data from an easily accessible source domain to enhance policy learning in a target domain with limited data. Our approach centers on return-conditioned supervised learning (RCSL), particularly focusing on the decision transformer (DT), which can predict actions conditioned on desired return guidance and complete trajectory history. Previous works tackle the dynamics shift problem by augmenting the reward in the trajectory from the source domain to match the optimal trajectory in the target domain. However, this strategy can not be directly applicable in RCSL owing to (1) the unique form of the RCSL policy class, which explicitly depends on the return, and (2) the absence of a straightforward representation of the optimal trajectory distribution. We propose the Return Augmented Decision Transformer (RADT) method, where we augment the return in the source domain by aligning its distribution with that in the target domain. We provide the theoretical analysis demonstrating that the RCSL policy learned from RADT achieves the same level of suboptimality as would be obtained without a dynamics shift. We introduce two practical implementations RADT-DARA and RADT-MV respectively. Extensive experiments conducted on D4RL datasets reveal that our methods generally outperform dynamic programming based methods in off-dynamics RL scenarios.
JustQ: Automated Deployment of Fair and Accurate Quantum Neural Networks
Mar 17, 2024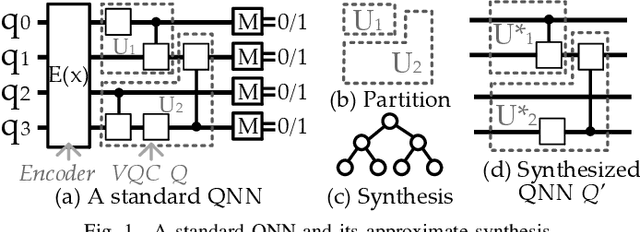

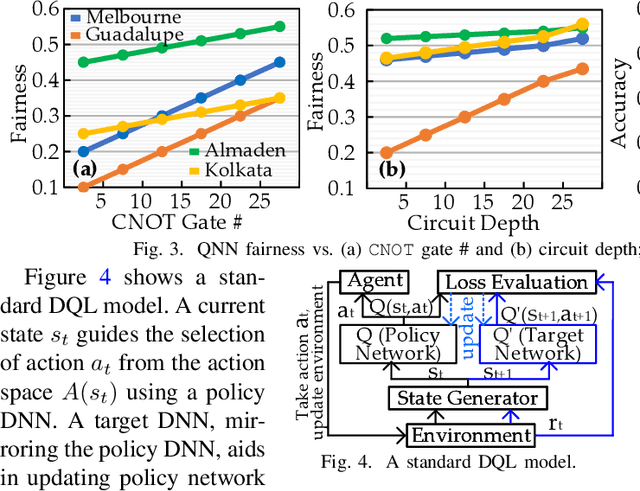
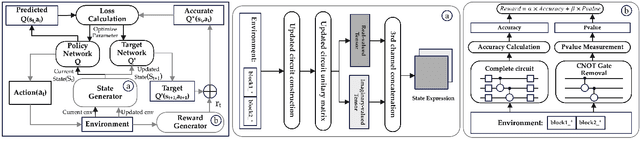
Despite the success of Quantum Neural Networks (QNNs) in decision-making systems, their fairness remains unexplored, as the focus primarily lies on accuracy. This work conducts a design space exploration, unveiling QNN unfairness, and highlighting the significant influence of QNN deployment and quantum noise on accuracy and fairness. To effectively navigate the vast QNN deployment design space, we propose JustQ, a framework for deploying fair and accurate QNNs on NISQ computers. It includes a complete NISQ error model, reinforcement learning-based deployment, and a flexible optimization objective incorporating both fairness and accuracy. Experimental results show JustQ outperforms previous methods, achieving superior accuracy and fairness. This work pioneers fair QNN design on NISQ computers, paving the way for future investigations.
LLMCarbon: Modeling the end-to-end Carbon Footprint of Large Language Models
Sep 25, 2023
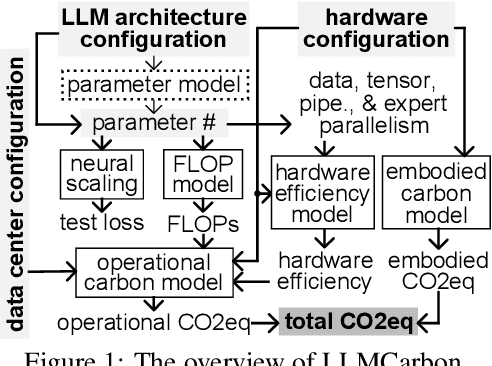
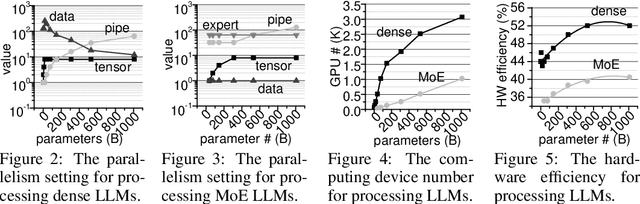

The carbon footprint associated with large language models (LLMs) is a significant concern, encompassing emissions from their training, inference, experimentation, and storage processes, including operational and embodied carbon emissions. An essential aspect is accurately estimating the carbon impact of emerging LLMs even before their training, which heavily relies on GPU usage. Existing studies have reported the carbon footprint of LLM training, but only one tool, mlco2, can predict the carbon footprint of new neural networks prior to physical training. However, mlco2 has several serious limitations. It cannot extend its estimation to dense or mixture-of-experts (MoE) LLMs, disregards critical architectural parameters, focuses solely on GPUs, and cannot model embodied carbon footprints. Addressing these gaps, we introduce \textit{LLMCarbon}, an end-to-end carbon footprint projection model designed for both dense and MoE LLMs. Compared to mlco2, LLMCarbon significantly enhances the accuracy of carbon footprint estimations for various LLMs.
Ranking in Genealogy: Search Results Fusion at Ancestry
Feb 27, 2019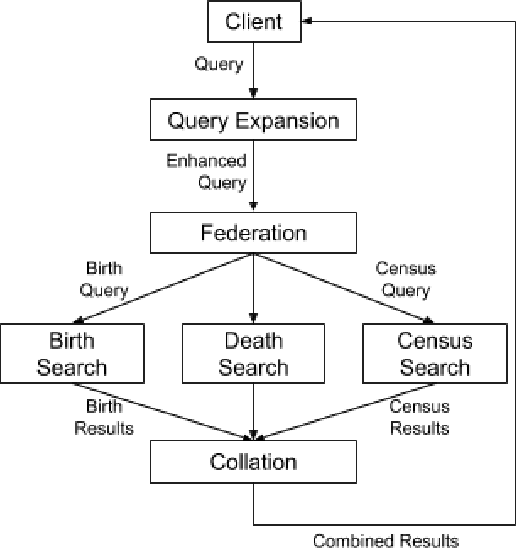
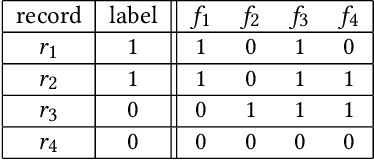
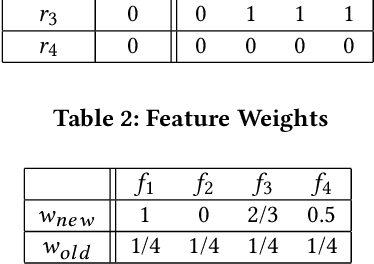
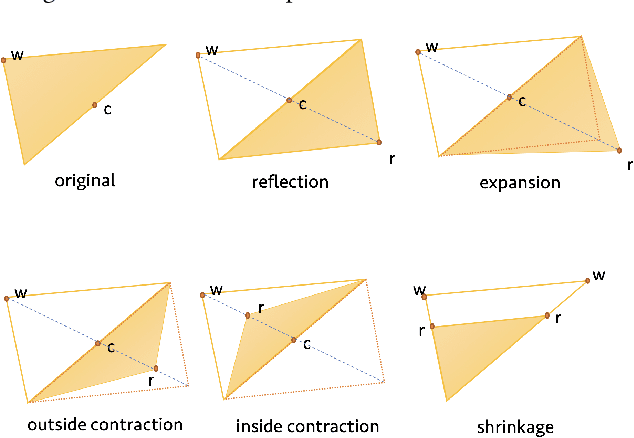
Genealogy research is the study of family history using available resources such as historical records. Ancestry provides its customers with one of the world's largest online genealogical index with billions of records from a wide range of sources, including vital records such as birth and death certificates, census records, court and probate records among many others. Search at Ancestry aims to return relevant records from various record types, allowing our subscribers to build their family trees, research their family history, and make meaningful discoveries about their ancestors from diverse perspectives. In a modern search engine designed for genealogical study, the appropriate ranking of search results to provide highly relevant information represents a daunting challenge. In particular, the disparity in historical records makes it inherently difficult to score records in an equitable fashion. Herein, we provide an overview of our solutions to overcome such record disparity problems in the Ancestry search engine. Specifically, we introduce customized coordinate ascent (customized CA) to speed up ranking within a specific record type. We then propose stochastic search (SS) that linearly combines ranked results federated across contents from various record types. Furthermore, we propose a novel information retrieval metric, normalized cumulative entropy (NCE), to measure the diversity of results. We demonstrate the effectiveness of these two algorithms in terms of relevance (by NDCG) and diversity (by NCE) if applicable in the offline experiments using real customer data at Ancestry.