 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted KL-Divergence for Document Ranking Model Refinement
Jun 10, 2024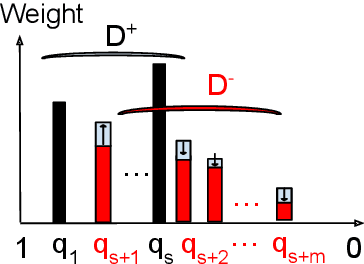
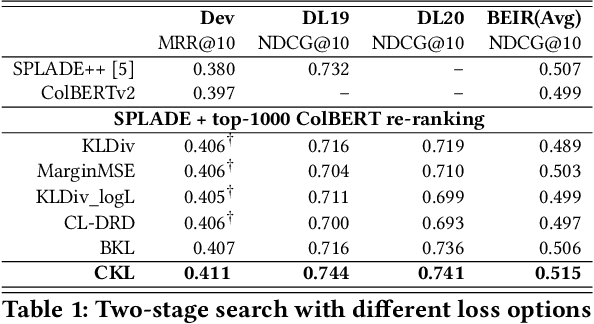
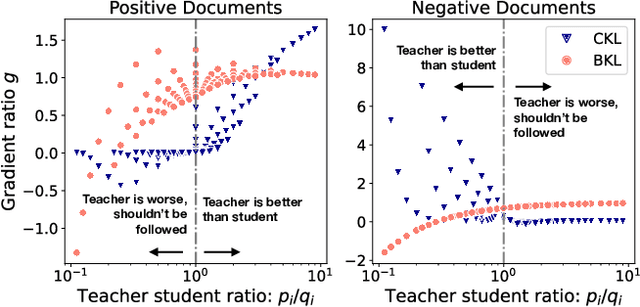
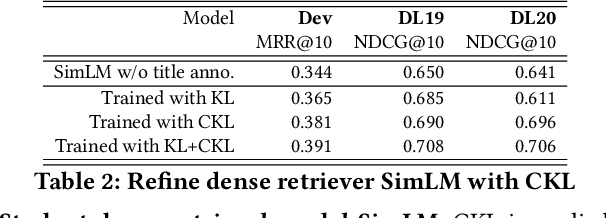
Transformer-based retrieval and reranking models for text document search are often refined through knowledge distillation together with contrastive learning. A tight distribution matching between the teacher and student models can be hard as over-calibration may degrade training effectiveness when a teacher does not perform well. This paper contrastively reweights KL divergence terms to prioritize the alignment between a student and a teacher model for proper separation of positive and negative documents. This paper analyzes and evaluates the proposed loss function on the MS MARCO and BEIR datasets to demonstrate its effectiveness in improving the relevance of tested student models.
Approximate Cluster-Based Sparse Document Retrieval with Segmented Maximum Term Weights
Apr 13, 2024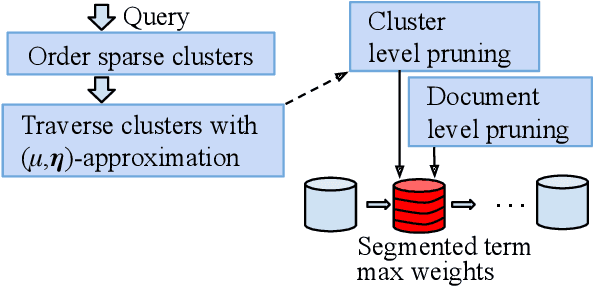

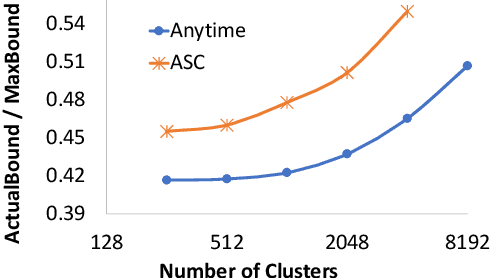
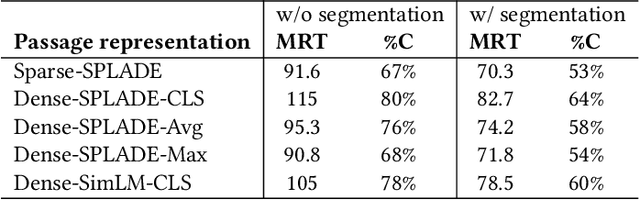
This paper revisits cluster-based retrieval that partitions the inverted index into multiple groups and skips the index partially at cluster and document levels during online inference using a learned sparse representation. It proposes an approximate search scheme with two parameters to control the rank-safeness competitiveness of pruning with segmented maximum term weights within each cluster. Cluster-level maximum weight segmentation allows an improvement in the rank score bound estimation and threshold-based pruning to be approximately adaptive to bound estimation tightness, resulting in better relevance and efficiency. The experiments with MS MARCO passage ranking and BEIR datasets demonstrate the usefulness of the proposed scheme with a comparison to the baselines. This paper presents the design of this approximate retrieval scheme with rank-safeness analysis, compares clustering and segmentation options, and reports evaluation results.
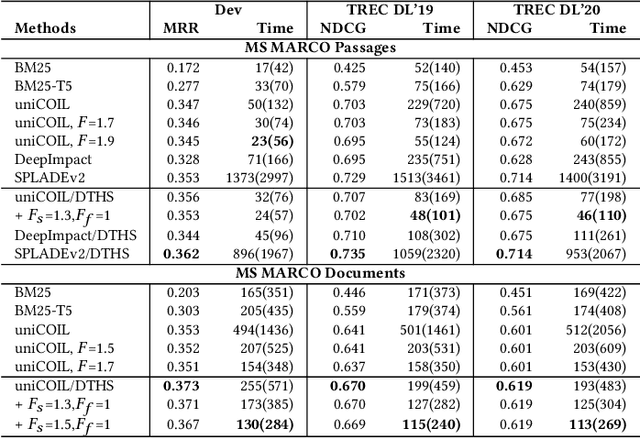
Representation Sparsification with Hybrid Thresholding for Fast SPLADE-based Document Retrieval
Jun 20, 2023


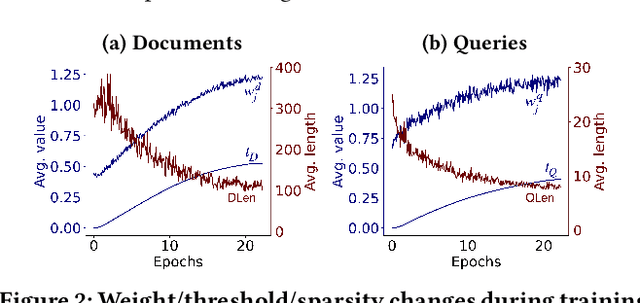
Learned sparse document representations using a transformer-based neural model has been found to be attractive in both relevance effectiveness and time efficiency. This paper describes a representation sparsification scheme based on hard and soft thresholding with an inverted index approximation for faster SPLADE-based document retrieval. It provides analytical and experimental results on the impact of this learnable hybrid thresholding scheme.
* This paper is published in SIGIR'23
Optimizing Guided Traversal for Fast Learned Sparse Retrieval
May 02, 2023
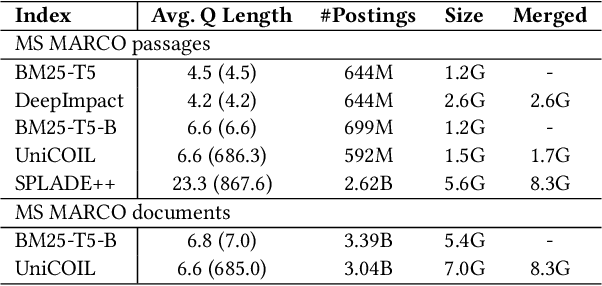
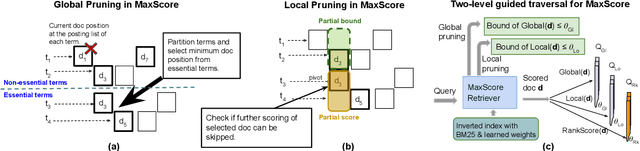
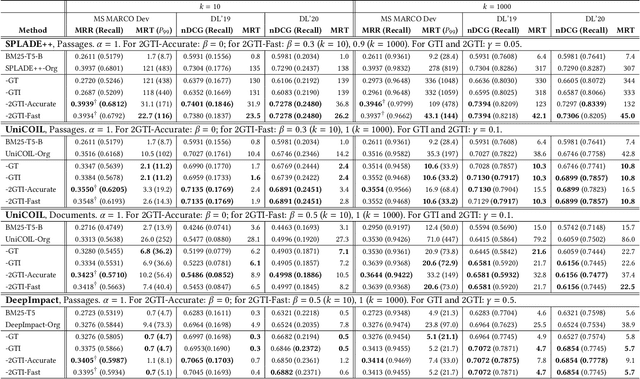
Recent studies show that BM25-driven dynamic index skipping can greatly accelerate MaxScore-based document retrieval based on the learned sparse representation derived by DeepImpact. This paper investigates the effectiveness of such a traversal guidance strategy during top k retrieval when using other models such as SPLADE and uniCOIL, and finds that unconstrained BM25-driven skipping could have a visible relevance degradation when the BM25 model is not well aligned with a learned weight model or when retrieval depth k is small. This paper generalizes the previous work and optimizes the BM25 guided index traversal with a two-level pruning control scheme and model alignment for fast retrieval using a sparse representation. Although there can be a cost of increased latency, the proposed scheme is much faster than the original MaxScore method without BM25 guidance while retaining the relevance effectiveness. This paper analyzes the competitiveness of this two-level pruning scheme, and evaluates its tradeoff in ranking relevance and time efficiency when searching several test datasets.
* This paper is published in WWW'23
Dual Skipping Guidance for Document Retrieval with Learned Sparse Representations
Apr 23, 2022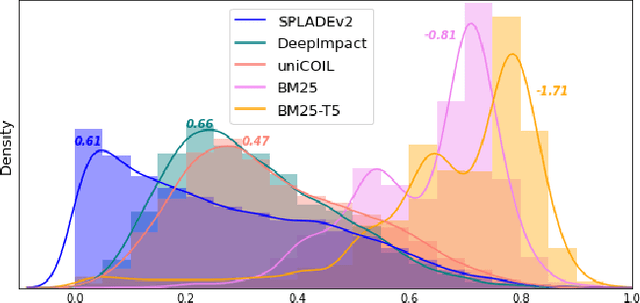
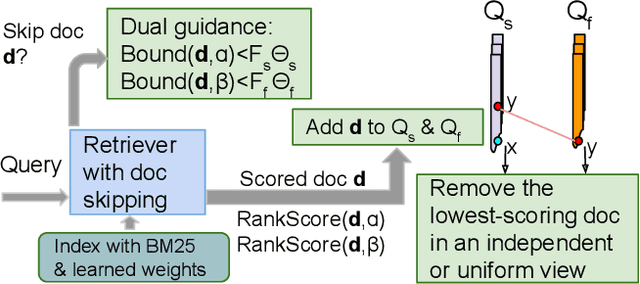
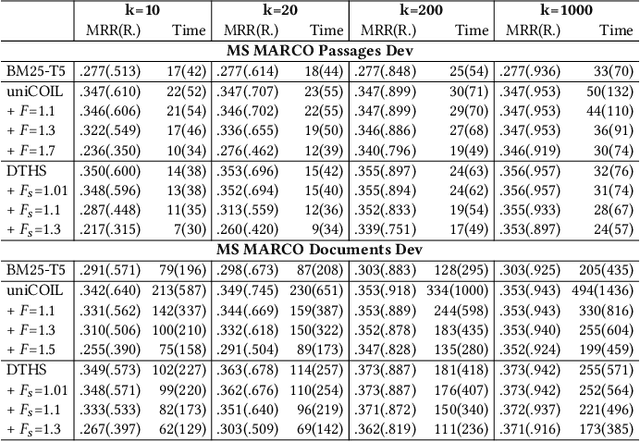
This paper proposes a dual skipping guidance scheme with hybrid scoring to accelerate document retrieval that uses learned sparse representations while still delivering a good relevance. This scheme uses both lexical BM25 and learned neural term weights to bound and compose the rank score of a candidate document separately for skipping and final ranking, and maintains two top-k thresholds during inverted index traversal. This paper evaluates time efficiency and ranking relevance of the proposed scheme in searching MS MARCO TREC datasets.
Compact Token Representations with Contextual Quantization for Efficient Document Re-ranking
Mar 29, 2022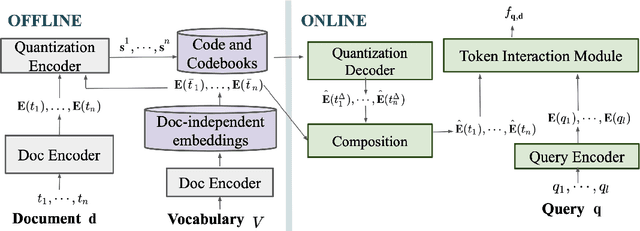

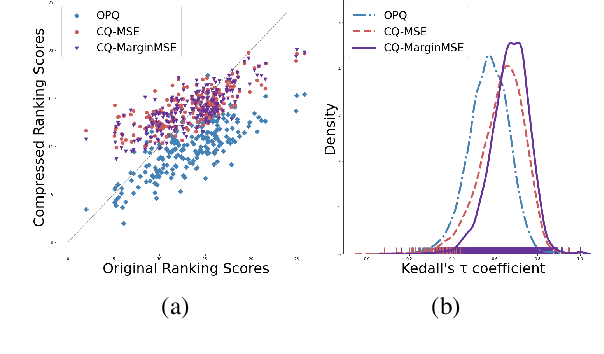
Transformer based re-ranking models can achieve high search relevance through context-aware soft matching of query tokens with document tokens. To alleviate runtime complexity of such inference, previous work has adopted a late interaction architecture with pre-computed contextual token representations at the cost of a large online storage. This paper proposes contextual quantization of token embeddings by decoupling document-specific and document-independent ranking contributions during codebook-based compression. This allows effective online decompression and embedding composition for better search relevance. This paper presents an evaluation of the above compact token representation model in terms of relevance and space efficiency.
Composite Re-Ranking for Efficient Document Search with BERT
Mar 12, 2021
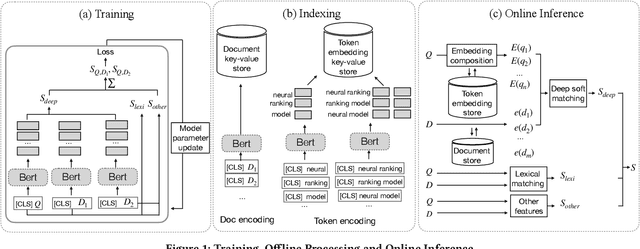

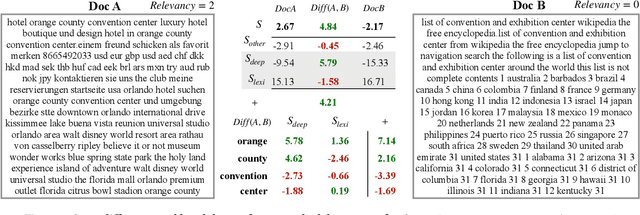
Although considerable efforts have been devoted to transformer-based ranking models for document search, the relevance-efficiency tradeoff remains a critical problem for ad-hoc ranking. To overcome this challenge, this paper presents BECR (BERT-based Composite Re-Ranking), a composite re-ranking scheme that combines deep contextual token interactions and traditional lexical term-matching features. In particular, BECR exploits a token encoding mechanism to decompose the query representations into pre-computable uni-grams and skip-n-grams. By applying token encoding on top of a dual-encoder architecture, BECR separates the attentions between a query and a document while capturing the contextual semantics of a query. In contrast to previous approaches, this framework does not perform expensive BERT computations during online inference. Thus, it is significantly faster, yet still able to achieve high competitiveness in ad-hoc ranking relevance. Finally, an in-depth comparison between BECR and other start-of-the-art neural ranking baselines is described using the TREC datasets, thereby further demonstrating the enhanced relevance and efficiency of BECR.
Semiparametric Methods for Exposure Misclassification in Propensity Score-Based Time-to-Event Data Analysis
Mar 19, 2019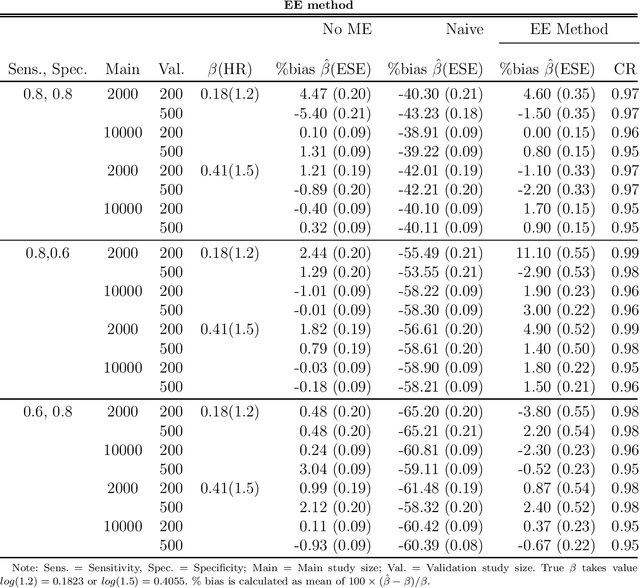
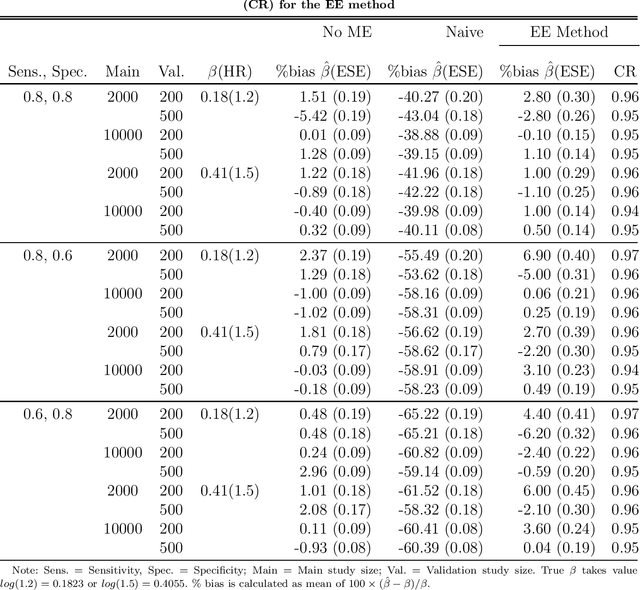
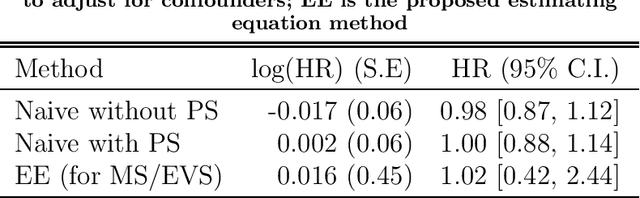
In epidemiology, identifying the effect of exposure variables in relation to a time-to-event outcome is a classical research area of practical importance. Incorporating propensity score in the Cox regression model, as a measure to control for confounding, has certain advantages when outcome is rare. However, in situations involving exposure measured with moderate to substantial error, identifying the exposure effect using propensity score in Cox models remains a challenging yet unresolved problem. In this paper, we propose an estimating equation method to correct for the exposure misclassification-caused bias in the estimation of exposure-outcome associations. We also discuss the asymptotic properties and derive the asymptotic variances of the proposed estimators. We conduct a simulation study to evaluate the performance of the proposed estimators in various settings. As an illustration, we apply our method to correct for the misclassification-caused bias in estimating the association of PM2.5 level with lung cancer mortality using a nationwide prospective cohort, the Nurses' Health Study (NHS). The proposed methodology can be applied using our user-friendly R function published online.
Ranking in Genealogy: Search Results Fusion at Ancestry
Feb 27, 2019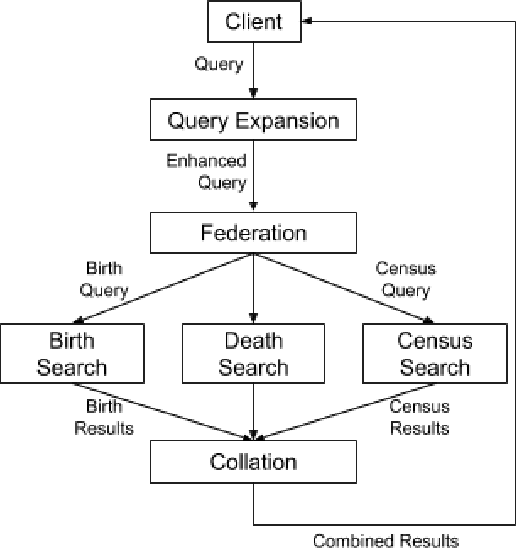
Genealogy research is the study of family history using available resources such as historical records. Ancestry provides its customers with one of the world's largest online genealogical index with billions of records from a wide range of sources, including vital records such as birth and death certificates, census records, court and probate records among many others. Search at Ancestry aims to return relevant records from various record types, allowing our subscribers to build their family trees, research their family history, and make meaningful discoveries about their ancestors from diverse perspectives. In a modern search engine designed for genealogical study, the appropriate ranking of search results to provide highly relevant information represents a daunting challenge. In particular, the disparity in historical records makes it inherently difficult to score records in an equitable fashion. Herein, we provide an overview of our solutions to overcome such record disparity problems in the Ancestry search engine. Specifically, we introduce customized coordinate ascent (customized CA) to speed up ranking within a specific record type. We then propose stochastic search (SS) that linearly combines ranked results federated across contents from various record types. Furthermore, we propose a novel information retrieval metric, normalized cumulative entropy (NCE), to measure the diversity of results. We demonstrate the effectiveness of these two algorithms in terms of relevance (by NDCG) and diversity (by NCE) if applicable in the offline experiments using real customer data at Ancestry.