Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted KL-Divergence for Document Ranking Model Refinement
Paper and Code
Jun 10, 2024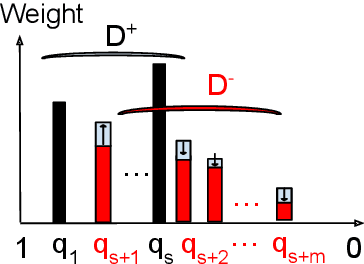
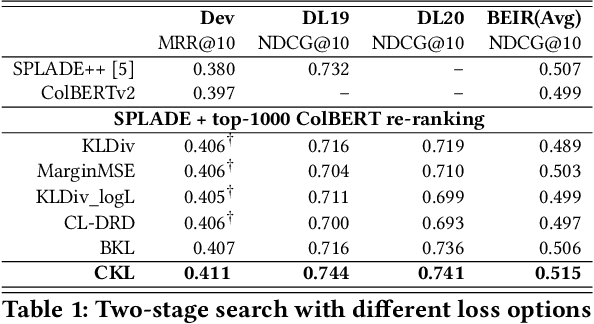
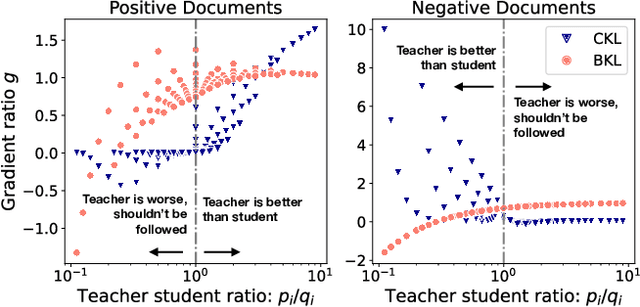
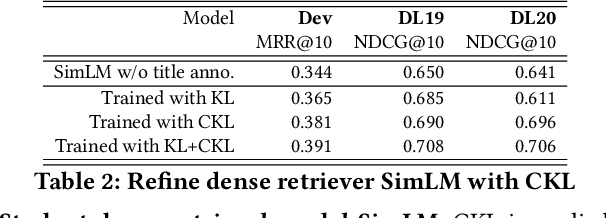
Transformer-based retrieval and reranking models for text document search are often refined through knowledge distillation together with contrastive learning. A tight distribution matching between the teacher and student models can be hard as over-calibration may degrade training effectiveness when a teacher does not perform well. This paper contrastively reweights KL divergence terms to prioritize the alignment between a student and a teacher model for proper separation of positive and negative documents. This paper analyzes and evaluates the proposed loss function on the MS MARCO and BEIR datasets to demonstrate its effectiveness in improving the relevance of tested student models.
View paper on