 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Superblock Pruning for Fast Learned Sparse Retrieval
Apr 23, 2025This paper proposes superblock pruning (SP) during top-k online document retrieval for learned sparse representations. SP structures the sparse index as a set of superblocks on a sequence of document blocks and conducts a superblock-level selection to decide if some superblocks can be pruned before visiting their child blocks. SP generalizes the previous flat block or cluster-based pruning, allowing the early detection of groups of documents that cannot or are less likely to appear in the final top-k list. SP can accelerate sparse retrieval in a rank-safe or approximate manner under a high-relevance competitiveness constraint. Our experiments show that the proposed scheme significantly outperforms state-of-the-art baselines on MS MARCO passages on a single-threaded CPU.
Weighted KL-Divergence for Document Ranking Model Refinement
Jun 10, 2024
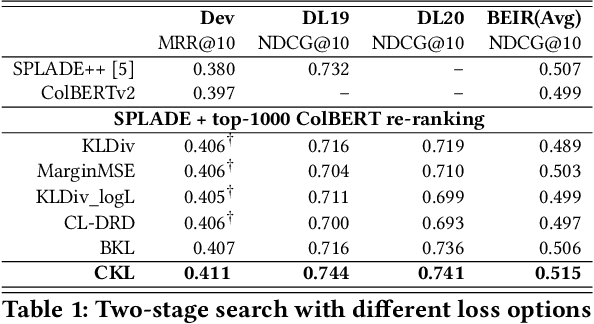
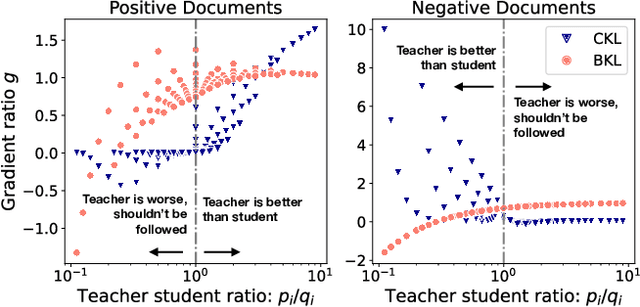
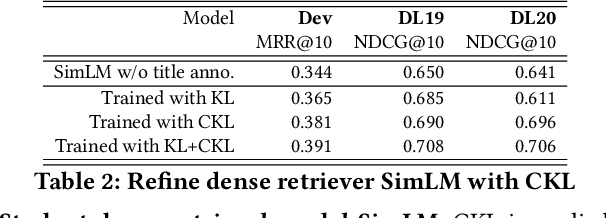
Transformer-based retrieval and reranking models for text document search are often refined through knowledge distillation together with contrastive learning. A tight distribution matching between the teacher and student models can be hard as over-calibration may degrade training effectiveness when a teacher does not perform well. This paper contrastively reweights KL divergence terms to prioritize the alignment between a student and a teacher model for proper separation of positive and negative documents. This paper analyzes and evaluates the proposed loss function on the MS MARCO and BEIR datasets to demonstrate its effectiveness in improving the relevance of tested student models.
Approximate Cluster-Based Sparse Document Retrieval with Segmented Maximum Term Weights
Apr 13, 2024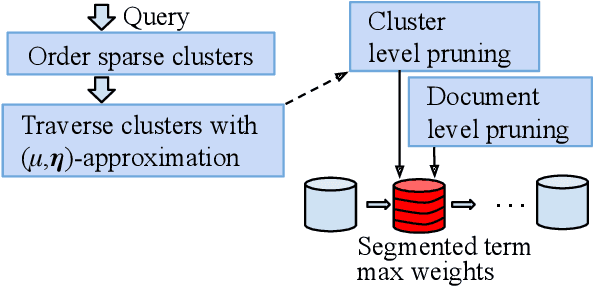

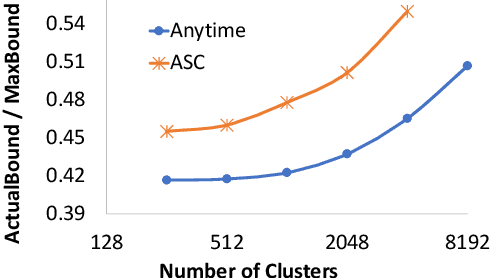
This paper revisits cluster-based retrieval that partitions the inverted index into multiple groups and skips the index partially at cluster and document levels during online inference using a learned sparse representation. It proposes an approximate search scheme with two parameters to control the rank-safeness competitiveness of pruning with segmented maximum term weights within each cluster. Cluster-level maximum weight segmentation allows an improvement in the rank score bound estimation and threshold-based pruning to be approximately adaptive to bound estimation tightness, resulting in better relevance and efficiency. The experiments with MS MARCO passage ranking and BEIR datasets demonstrate the usefulness of the proposed scheme with a comparison to the baselines. This paper presents the design of this approximate retrieval scheme with rank-safeness analysis, compares clustering and segmentation options, and reports evaluation results.
Representation Sparsification with Hybrid Thresholding for Fast SPLADE-based Document Retrieval
Jun 20, 2023


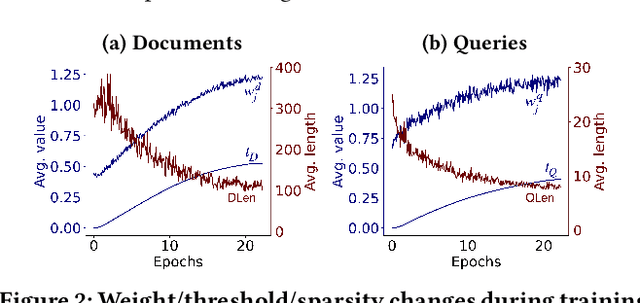
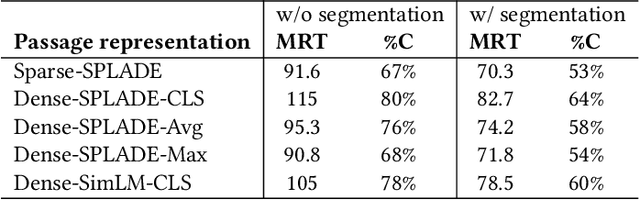
Learned sparse document representations using a transformer-based neural model has been found to be attractive in both relevance effectiveness and time efficiency. This paper describes a representation sparsification scheme based on hard and soft thresholding with an inverted index approximation for faster SPLADE-based document retrieval. It provides analytical and experimental results on the impact of this learnable hybrid thresholding scheme.
* This paper is published in SIGIR'23