 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVentral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020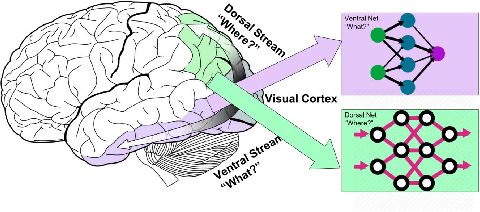
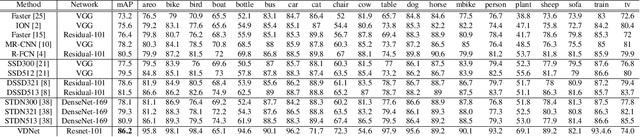
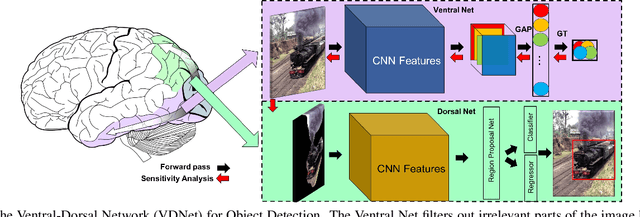

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
Image captioning with weakly-supervised attention penalty
Mar 06, 2019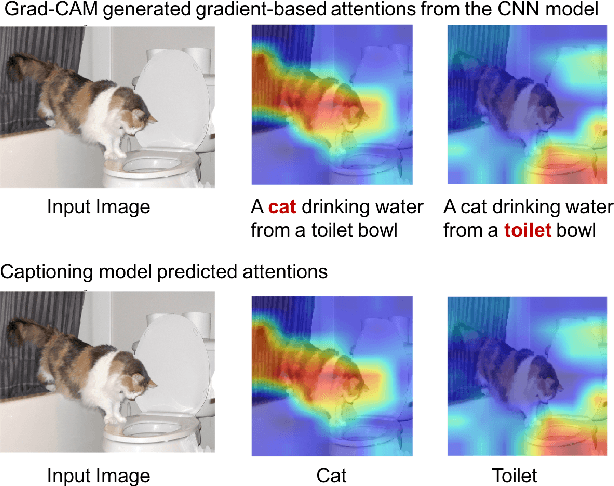
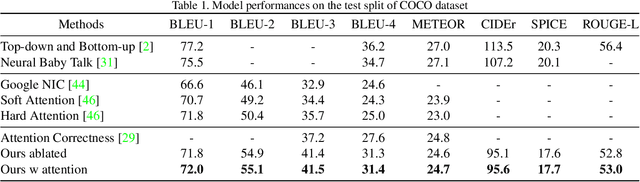
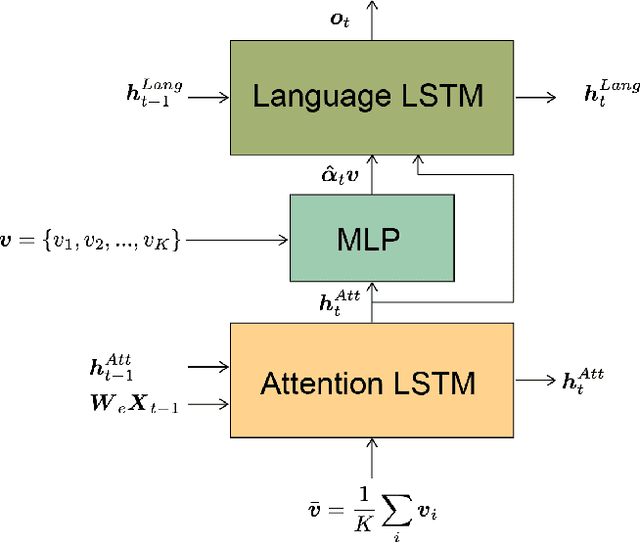

Stories are essential for genealogy research since they can help build emotional connections with people. A lot of family stories are reserved in historical photos and albums. Recent development on image captioning models makes it feasible to "tell stories" for photos automatically. The attention mechanism has been widely adopted in many state-of-the-art encoder-decoder based image captioning models, since it can bridge the gap between the visual part and the language part. Most existing captioning models implicitly trained attention modules with word-likelihood loss. Meanwhile, lots of studies have investigated intrinsic attentions for visual models using gradient-based approaches. Ideally, attention maps predicted by captioning models should be consistent with intrinsic attentions from visual models for any given visual concept. However, no work has been done to align implicitly learned attention maps with intrinsic visual attentions. In this paper, we proposed a novel model that measured consistency between captioning predicted attentions and intrinsic visual attentions. This alignment loss allows explicit attention correction without using any expensive bounding box annotations. We developed and evaluated our model on COCO dataset as well as a genealogical dataset from Ancestry.com Operations Inc., which contains billions of historical photos. The proposed model achieved better performances on all commonly used language evaluation metrics for both datasets.
Ranking in Genealogy: Search Results Fusion at Ancestry
Feb 27, 2019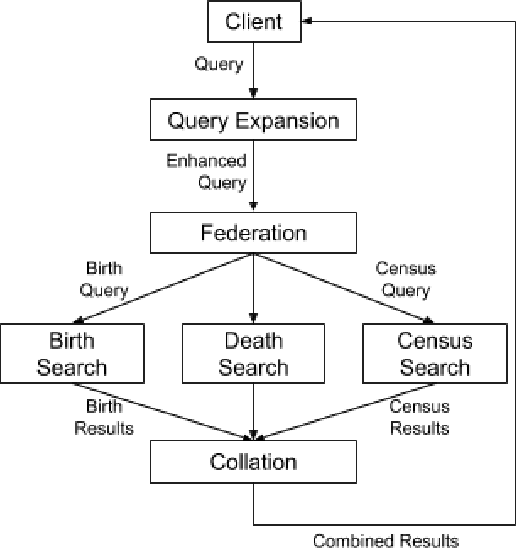
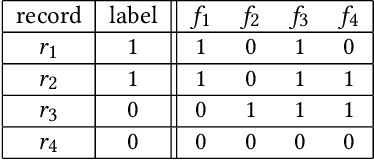
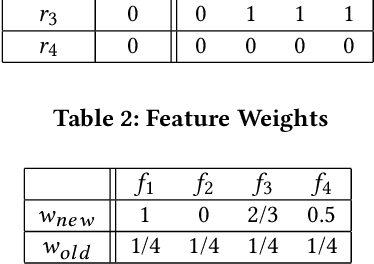
Genealogy research is the study of family history using available resources such as historical records. Ancestry provides its customers with one of the world's largest online genealogical index with billions of records from a wide range of sources, including vital records such as birth and death certificates, census records, court and probate records among many others. Search at Ancestry aims to return relevant records from various record types, allowing our subscribers to build their family trees, research their family history, and make meaningful discoveries about their ancestors from diverse perspectives. In a modern search engine designed for genealogical study, the appropriate ranking of search results to provide highly relevant information represents a daunting challenge. In particular, the disparity in historical records makes it inherently difficult to score records in an equitable fashion. Herein, we provide an overview of our solutions to overcome such record disparity problems in the Ancestry search engine. Specifically, we introduce customized coordinate ascent (customized CA) to speed up ranking within a specific record type. We then propose stochastic search (SS) that linearly combines ranked results federated across contents from various record types. Furthermore, we propose a novel information retrieval metric, normalized cumulative entropy (NCE), to measure the diversity of results. We demonstrate the effectiveness of these two algorithms in terms of relevance (by NDCG) and diversity (by NCE) if applicable in the offline experiments using real customer data at Ancestry.