 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Metric Learning with Soft Orthogonal Proxies
Jun 22, 2023

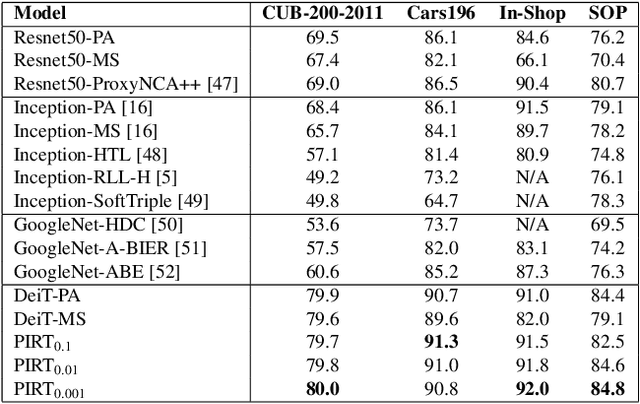

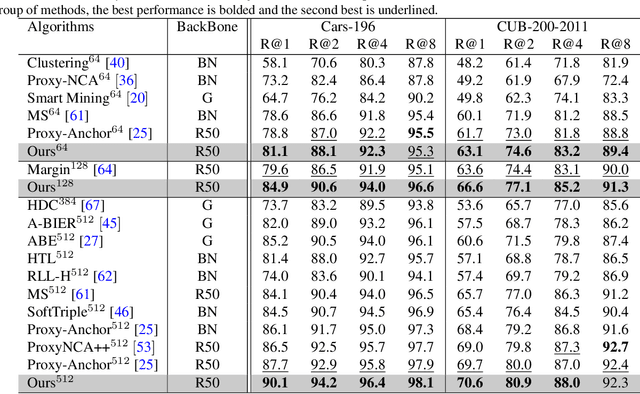
Deep Metric Learning (DML) models rely on strong representations and similarity-based measures with specific loss functions. Proxy-based losses have shown great performance compared to pair-based losses in terms of convergence speed. However, proxies that are assigned to different classes may end up being closely located in the embedding space and hence having a hard time to distinguish between positive and negative items. Alternatively, they may become highly correlated and hence provide redundant information with the model. To address these issues, we propose a novel approach that introduces Soft Orthogonality (SO) constraint on proxies. The constraint ensures the proxies to be as orthogonal as possible and hence control their positions in the embedding space. Our approach leverages Data-Efficient Image Transformer (DeiT) as an encoder to extract contextual features from images along with a DML objective. The objective is made of the Proxy Anchor loss along with the SO regularization. We evaluate our method on four public benchmarks for category-level image retrieval and demonstrate its effectiveness with comprehensive experimental results and ablation studies. Our evaluations demonstrate the superiority of our proposed approach over state-of-the-art methods by a significant margin.
Image-based eeg classification of brain responses to song recordings
Jan 31, 2022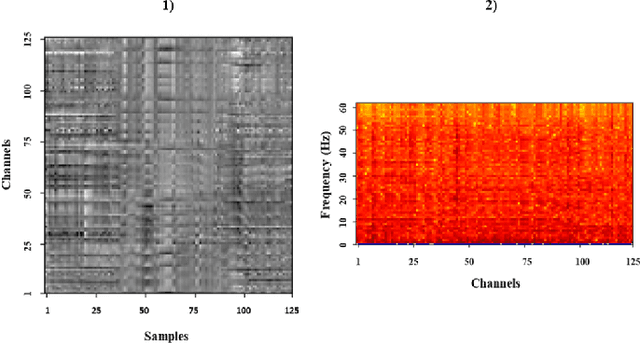
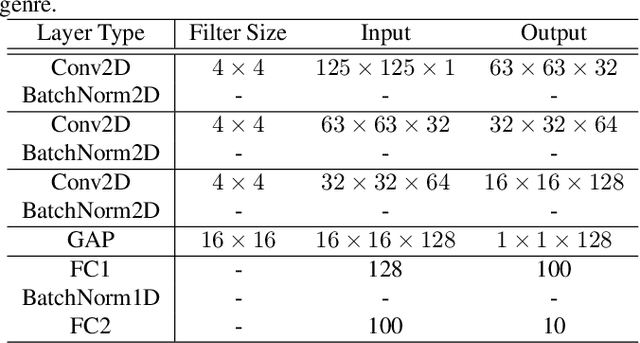
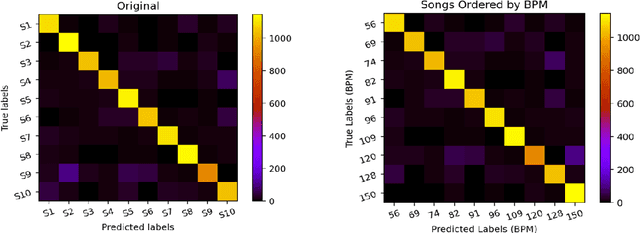
Classifying EEG responses to naturalistic acoustic stimuli is of theoretical and practical importance, but standard approaches are limited by processing individual channels separately on very short sound segments (a few seconds or less). Recent developments have shown classification for music stimuli (~2 mins) by extracting spectral components from EEG and using convolutional neural networks (CNNs). This paper proposes an efficient method to map raw EEG signals to individual songs listened for end-to-end classification. EEG channels are treated as a dimension of a [Channel x Sample] image tile, and images are classified using CNNs. Our experimental results (88.7%) compete with state-of-the-art methods (85.0%), yet our classification task is more challenging by processing longer stimuli that were similar to each other in perceptual quality, and were unfamiliar to participants. We also adopt a transfer learning scheme using a pre-trained ResNet-50, confirming the effectiveness of transfer learning despite image domains unrelated from each other.
Multi-Head Deep Metric Learning Using Global and Local Representations
Dec 28, 2021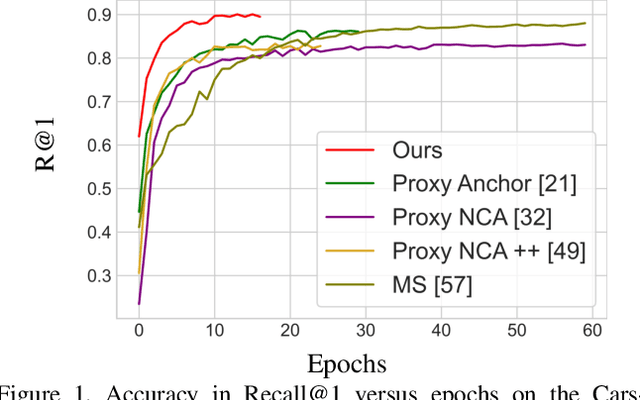
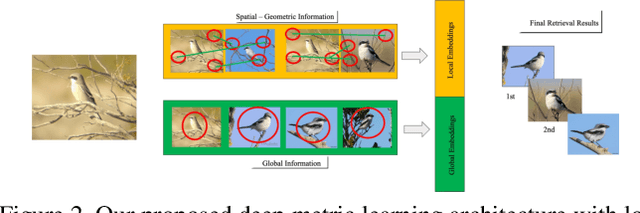
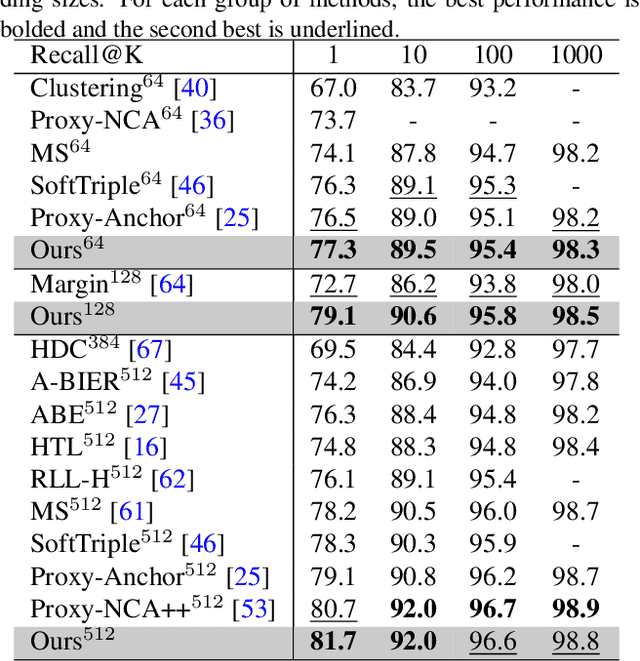
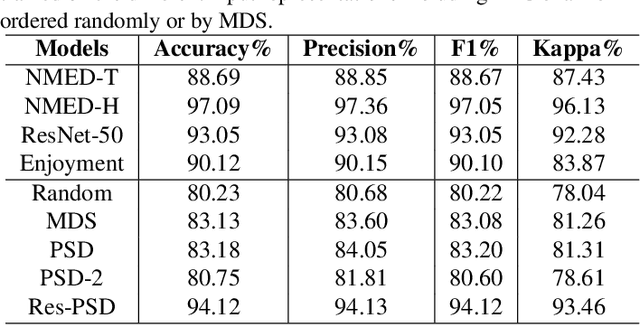
Deep Metric Learning (DML) models often require strong local and global representations, however, effective integration of local and global features in DML model training is a challenge. DML models are often trained with specific loss functions, including pairwise-based and proxy-based losses. The pairwise-based loss functions leverage rich semantic relations among data points, however, they often suffer from slow convergence during DML model training. On the other hand, the proxy-based loss functions often lead to significant speedups in convergence during training, while the rich relations among data points are often not fully explored by the proxy-based losses. In this paper, we propose a novel DML approach to address these challenges. The proposed DML approach makes use of a hybrid loss by integrating the pairwise-based and the proxy-based loss functions to leverage rich data-to-data relations as well as fast convergence. Furthermore, the proposed DML approach utilizes both global and local features to obtain rich representations in DML model training. Finally, we also use the second-order attention for feature enhancement to improve accurate and efficient retrieval. In our experiments, we extensively evaluated the proposed DML approach on four public benchmarks, and the experimental results demonstrate that the proposed method achieved state-of-the-art performance on all benchmarks.
End-to-End Auditory Object Recognition via Inception Nucleus
May 25, 2020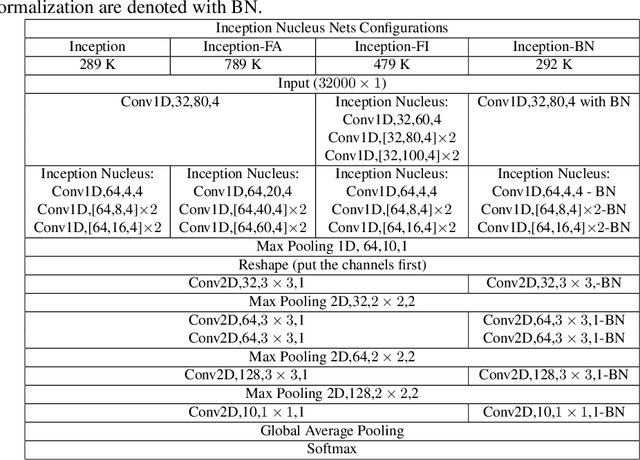
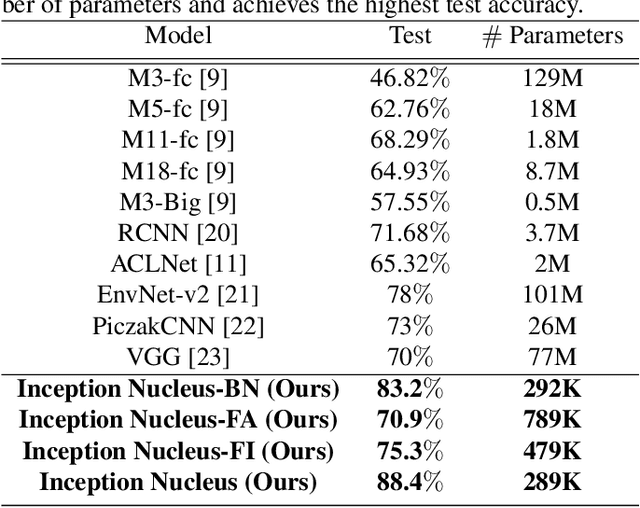


Machine learning approaches to auditory object recognition are traditionally based on engineered features such as those derived from the spectrum or cepstrum. More recently, end-to-end classification systems in image and auditory recognition systems have been developed to learn features jointly with classification and result in improved classification accuracy. In this paper, we propose a novel end-to-end deep neural network to map the raw waveform inputs to sound class labels. Our network includes an "inception nucleus" that optimizes the size of convolutional filters on the fly that results in reducing engineering efforts dramatically. Classification results compared favorably against current state-of-the-art approaches, besting them by 10.4 percentage points on the Urbansound8k dataset. Analyses of learned representations revealed that filters in the earlier hidden layers learned wavelet-like transforms to extract features that were informative for classification.
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020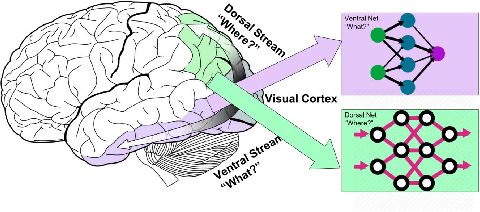
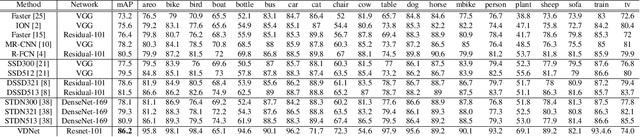
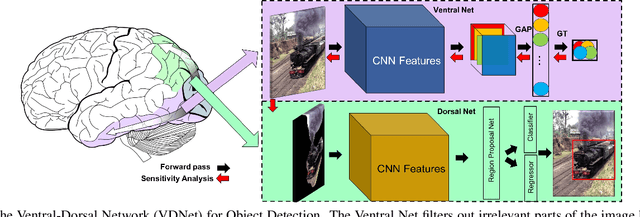

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
WW-Nets: Dual Neural Networks for Object Detection
May 15, 2020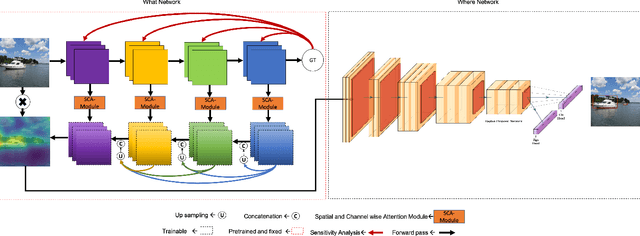

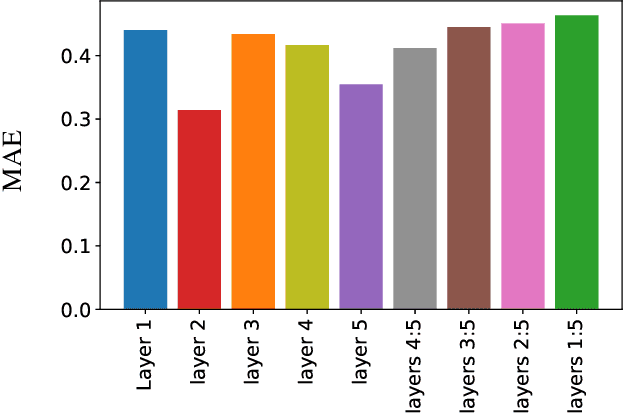
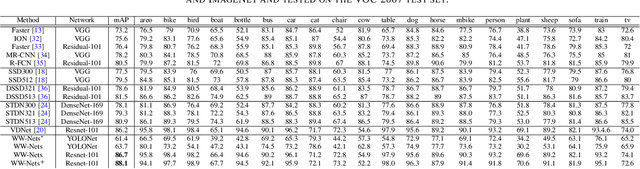
We propose a new deep convolutional neural network framework that uses object location knowledge implicit in network connection weights to guide selective attention in object detection tasks. Our approach is called What-Where Nets (WW-Nets), and it is inspired by the structure of human visual pathways. In the brain, vision incorporates two separate streams, one in the temporal lobe and the other in the parietal lobe, called the ventral stream and the dorsal stream, respectively. The ventral pathway from primary visual cortex is dominated by "what" information, while the dorsal pathway is dominated by "where" information. Inspired by this structure, we have proposed an object detection framework involving the integration of a "What Network" and a "Where Network". The aim of the What Network is to provide selective attention to the relevant parts of the input image. The Where Network uses this information to locate and classify objects of interest. In this paper, we compare this approach to state-of-the-art algorithms on the PASCAL VOC 2007 and 2012 and COCO object detection challenge datasets. Also, we compare out approach to human "ground-truth" attention. We report the results of an eye-tracking experiment on human subjects using images from PASCAL VOC 2007, and we demonstrate interesting relationships between human overt attention and information processing in our WW-Nets. Finally, we provide evidence that our proposed method performs favorably in comparison to other object detection approaches, often by a large margin. The code and the eye-tracking ground-truth dataset can be found at: https://github.com/mkebrahimpour.
Image captioning with weakly-supervised attention penalty
Mar 06, 2019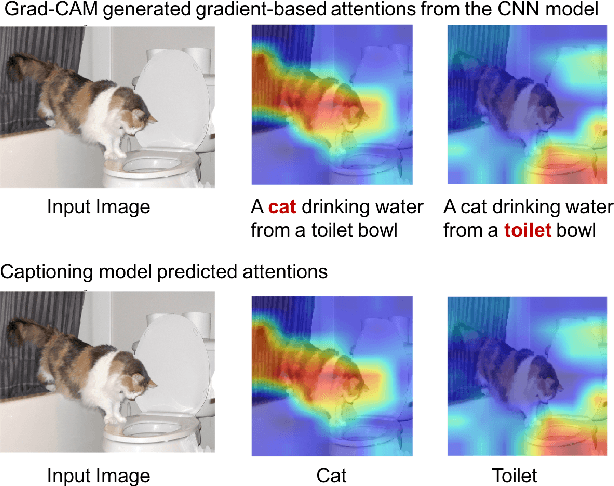
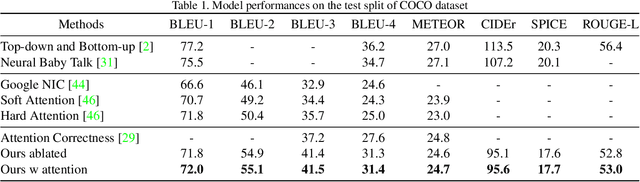
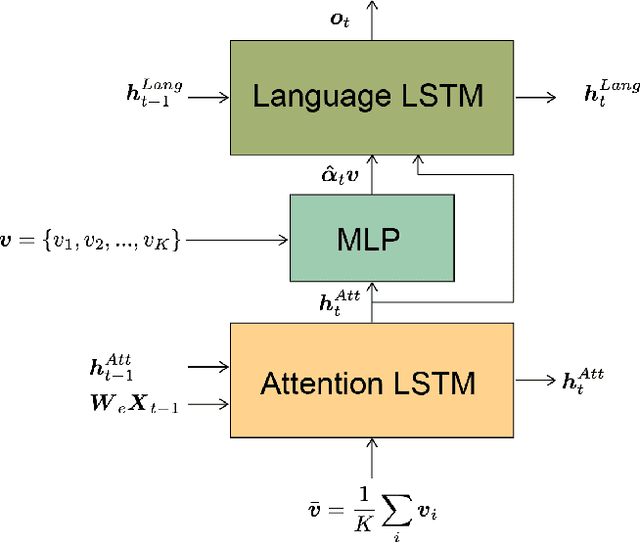

Stories are essential for genealogy research since they can help build emotional connections with people. A lot of family stories are reserved in historical photos and albums. Recent development on image captioning models makes it feasible to "tell stories" for photos automatically. The attention mechanism has been widely adopted in many state-of-the-art encoder-decoder based image captioning models, since it can bridge the gap between the visual part and the language part. Most existing captioning models implicitly trained attention modules with word-likelihood loss. Meanwhile, lots of studies have investigated intrinsic attentions for visual models using gradient-based approaches. Ideally, attention maps predicted by captioning models should be consistent with intrinsic attentions from visual models for any given visual concept. However, no work has been done to align implicitly learned attention maps with intrinsic visual attentions. In this paper, we proposed a novel model that measured consistency between captioning predicted attentions and intrinsic visual attentions. This alignment loss allows explicit attention correction without using any expensive bounding box annotations. We developed and evaluated our model on COCO dataset as well as a genealogical dataset from Ancestry.com Operations Inc., which contains billions of historical photos. The proposed model achieved better performances on all commonly used language evaluation metrics for both datasets.