 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Modern Persian Carpet Map by Style-transfer
Aug 08, 2023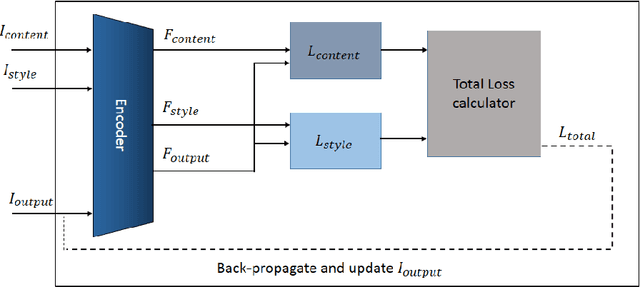



Today, the great performance of Deep Neural Networks(DNN) has been proven in various fields. One of its most attractive applications is to produce artistic designs. A carpet that is known as a piece of art is one of the most important items in a house, which has many enthusiasts all over the world. The first stage of producing a carpet is to prepare its map, which is a difficult, time-consuming, and expensive task. In this research work, our purpose is to use DNN for generating a Modern Persian Carpet Map. To reach this aim, three different DNN style transfer methods are proposed and compared against each other. In the proposed methods, the Style-Swap method is utilized to create the initial carpet map, and in the following, to generate more diverse designs, methods Clip-Styler, Gatys, and Style-Swap are used separately. In addition, some methods are examined and introduced for coloring the produced carpet maps. The designed maps are evaluated via the results of filled questionnaires where the outcomes of user evaluations confirm the popularity of generated carpet maps. Eventually, for the first time, intelligent methods are used in producing carpet maps, and it reduces human intervention. The proposed methods can successfully produce diverse carpet designs, and at a higher speed than traditional ways.
DINO-CXR: A self supervised method based on vision transformer for chest X-ray classification
Aug 01, 2023The limited availability of labeled chest X-ray datasets is a significant bottleneck in the development of medical imaging methods. Self-supervised learning (SSL) can mitigate this problem by training models on unlabeled data. Furthermore, self-supervised pretraining has yielded promising results in visual recognition of natural images but has not been given much consideration in medical image analysis. In this work, we propose a self-supervised method, DINO-CXR, which is a novel adaptation of a self-supervised method, DINO, based on a vision transformer for chest X-ray classification. A comparative analysis is performed to show the effectiveness of the proposed method for both pneumonia and COVID-19 detection. Through a quantitative analysis, it is also shown that the proposed method outperforms state-of-the-art methods in terms of accuracy and achieves comparable results in terms of AUC and F-1 score while requiring significantly less labeled data.
Deep Metric Learning with Soft Orthogonal Proxies
Jun 22, 2023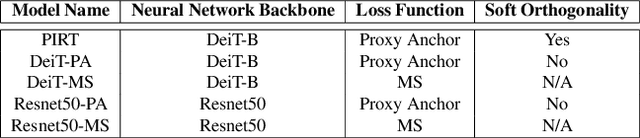

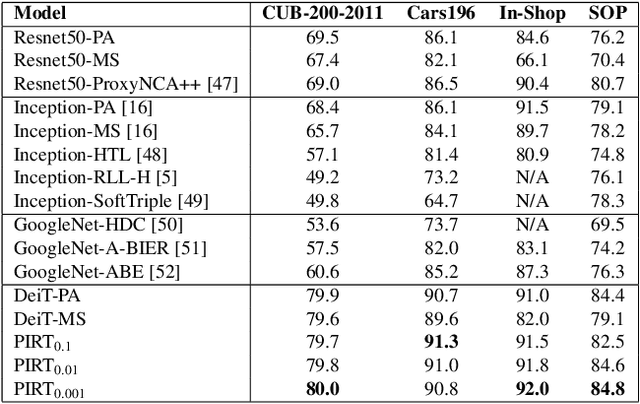

Deep Metric Learning (DML) models rely on strong representations and similarity-based measures with specific loss functions. Proxy-based losses have shown great performance compared to pair-based losses in terms of convergence speed. However, proxies that are assigned to different classes may end up being closely located in the embedding space and hence having a hard time to distinguish between positive and negative items. Alternatively, they may become highly correlated and hence provide redundant information with the model. To address these issues, we propose a novel approach that introduces Soft Orthogonality (SO) constraint on proxies. The constraint ensures the proxies to be as orthogonal as possible and hence control their positions in the embedding space. Our approach leverages Data-Efficient Image Transformer (DeiT) as an encoder to extract contextual features from images along with a DML objective. The objective is made of the Proxy Anchor loss along with the SO regularization. We evaluate our method on four public benchmarks for category-level image retrieval and demonstrate its effectiveness with comprehensive experimental results and ablation studies. Our evaluations demonstrate the superiority of our proposed approach over state-of-the-art methods by a significant margin.
SELF-VS: Self-supervised Encoding Learning For Video Summarization
Mar 28, 2023Despite its wide range of applications, video summarization is still held back by the scarcity of extensive datasets, largely due to the labor-intensive and costly nature of frame-level annotations. As a result, existing video summarization methods are prone to overfitting. To mitigate this challenge, we propose a novel self-supervised video representation learning method using knowledge distillation to pre-train a transformer encoder. Our method matches its semantic video representation, which is constructed with respect to frame importance scores, to a representation derived from a CNN trained on video classification. Empirical evaluations on correlation-based metrics, such as Kendall's $\tau$ and Spearman's $\rho$ demonstrate the superiority of our approach compared to existing state-of-the-art methods in assigning relative scores to the input frames.
A New Scheme for Image Compression and Encryption Using ECIES, Henon Map, and AEGAN
Aug 24, 2022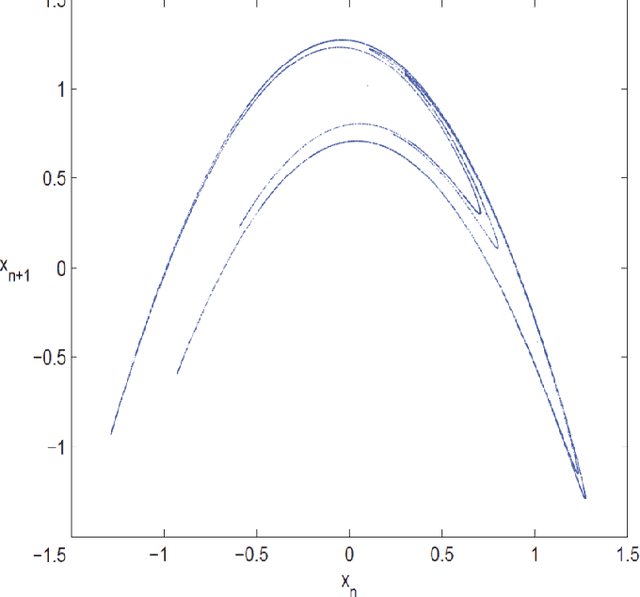
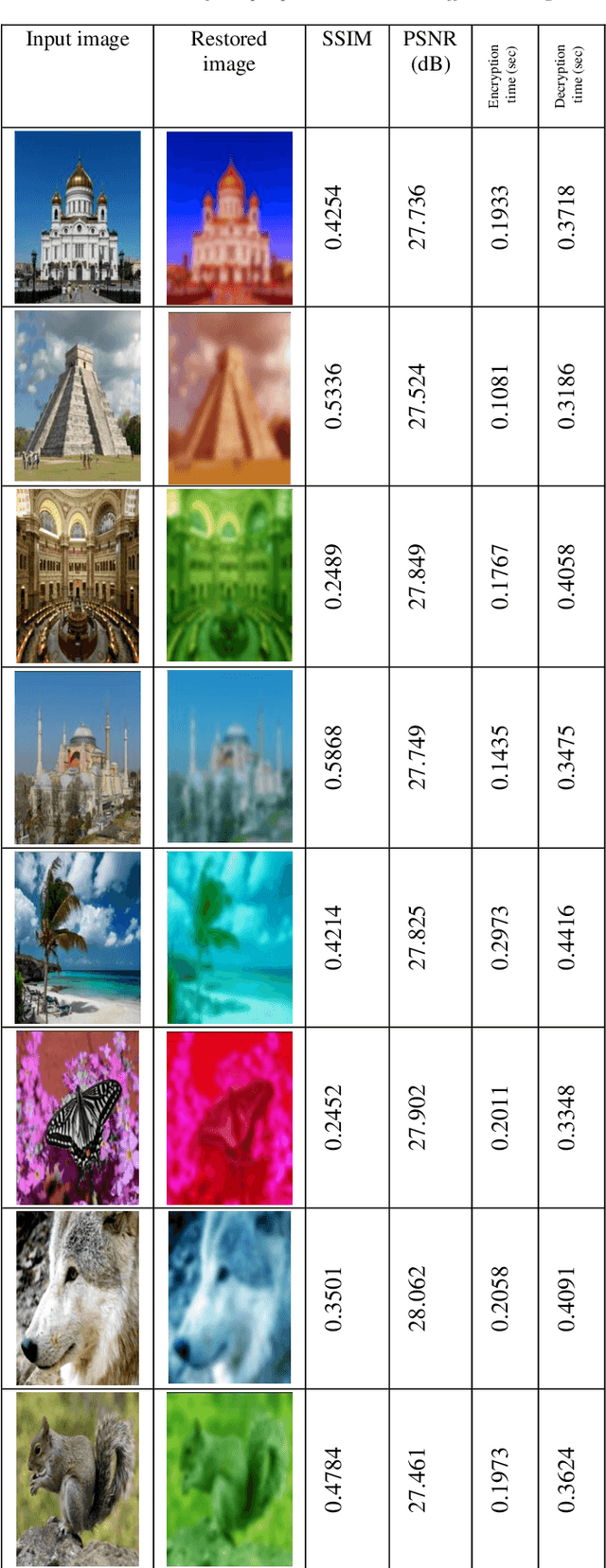
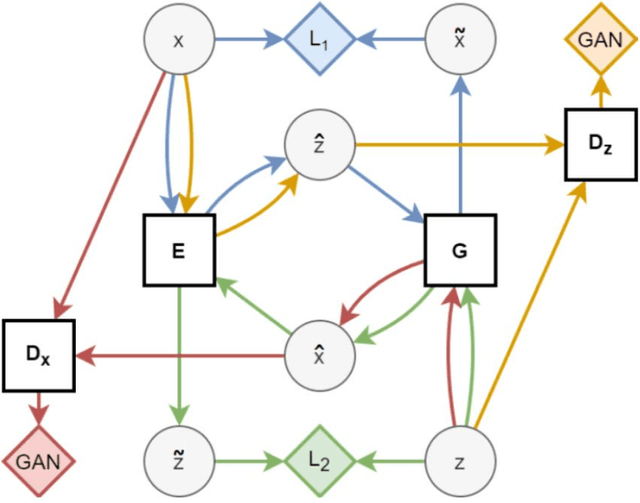
Providing security in the transmission of images and other multimedia data has become one of the most important scientific and practical issues. In this paper, a method for compressing and encryption images is proposed, which can safely transmit images in low-bandwidth data transmission channels. At first, using the autoencoding generative adversarial network (AEGAN) model, the images are mapped to a vector in the latent space with low dimensions. In the next step, the obtained vector is encrypted using public key encryption methods. In the proposed method, Henon chaotic map is used for permutation, which makes information transfer more secure. To evaluate the results of the proposed scheme, three criteria SSIM, PSNR, and execution time have been used.
DISCERN: Diversity-based Selection of Centroids for k-Estimation and Rapid Non-stochastic Clustering
Oct 14, 2019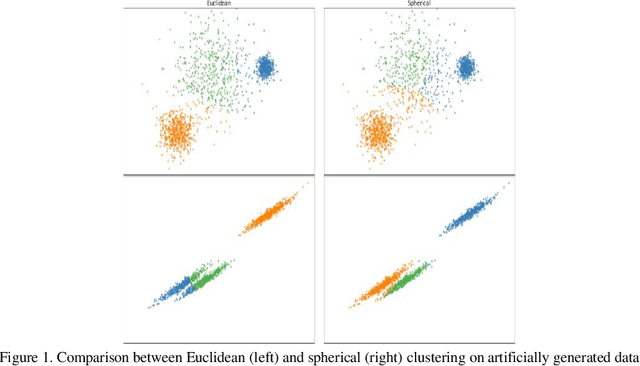
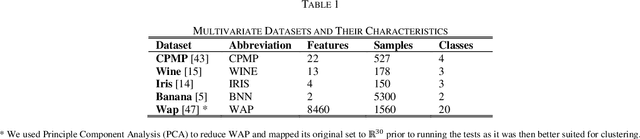
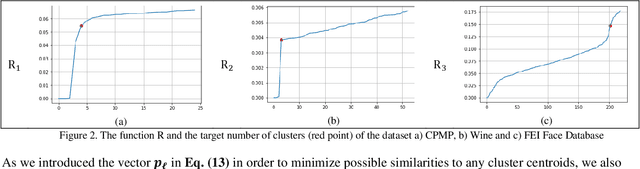

As one of the most ubiquitously applied unsupervised learning methods, clustering has also been known to have a few disadvantages. More specifically, parameters such as the number of clusters and neighborhood radius are what call the `unsupervised` nature of these algorithms into question. Moreover, the stochastic nature of a great number of these algorithms is also a considerable point of weakness. In order to address these issues, we propose DISCERN which can serve as an initialization algorithm for K-Means, finding suitable centroids that increase the performance of K-Means. Following that, the algorithm can estimate the number of clusters if need be. The algorithm does all of that, while maintaining complete robustness and returning the same results at each separate run. We ran experiments on the proposed method processing multiple datasets and the results show its undeniable superiority in terms of results, computational time and robustness when compared to the randomized K-Means and K-Means++ initialization. In addition, the superiority in estimating the number of clusters is also discussed and we prove the lower complexity when compared to methods such as the elbow and silhouette methods in estimating the number of clusters.
Towards Shape Biased Unsupervised Representation Learning for Domain Generalization
Sep 18, 2019
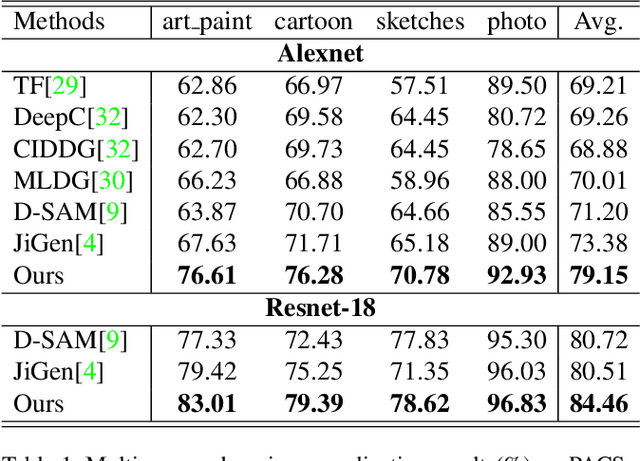
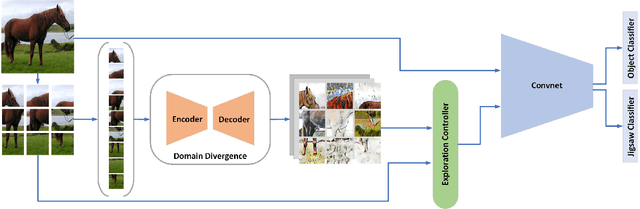
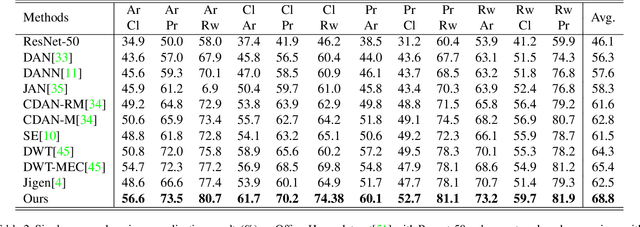
It is known that, without awareness of the process, our brain appears to focus on the general shape of objects rather than superficial statistics of context. On the other hand, learning autonomously allows discovering invariant regularities which help generalization. In this work, we propose a learning framework to improve the shape bias property of self-supervised methods. Our method learns semantic and shape biased representations by integrating domain diversification and jigsaw puzzles. The first module enables the model to create a dynamic environment across arbitrary domains and provides a domain exploration vs. exploitation trade-off, while the second module allows the model to explore this environment autonomously. This universal framework does not require prior knowledge of the domain of interest. Extensive experiments are conducted on several domain generalization datasets, namely, PACS, Office-Home, VLCS, and Digits. We show that our framework outperforms state-of-the-art domain generalization methods by a large margin.
Diminishing the Effect of Adversarial Perturbations via Refining Feature Representation
Jul 01, 2019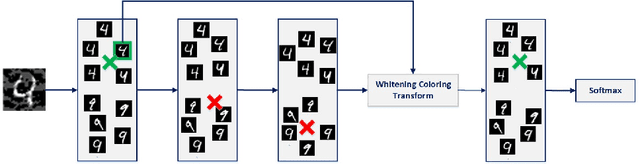

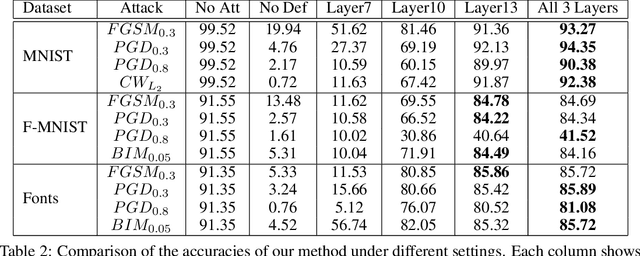

Deep neural networks are highly vulnerable to adversarial examples, which imposes severe security issues for these state-of-the-art models. Many defense methods have been proposed to mitigate this problem. However, a lot of them depend on modification or additional training of the target model. In this work, we analytically investigate each layer representation of non-perturbed and perturbed images and show the effect of perturbations on each of these representations. Accordingly, a method based on whitening coloring transform is proposed in order to diminish the misrepresentation of any desirable layer caused by adversaries. Our method can be applied to any layer of any arbitrary model without the need of any modification or additional training. Due to the fact that full whitening of the layer representation is not easily differentiable, our proposed method is superbly robust against white-box attacks. Furthermore, we demonstrate the strength of our method against some state-of-the-art black-box attacks such as Carlini-Wagner L2 attack and we show that our method is able to defend against some non-constrained attacks.
A Fuzzy-Rough based Binary Shuffled Frog Leaping Algorithm for Feature Selection
Jul 31, 2018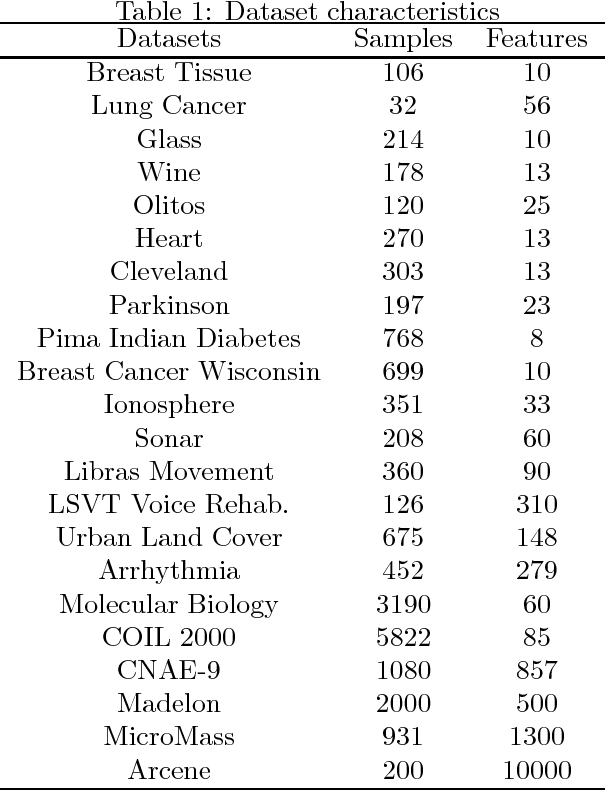

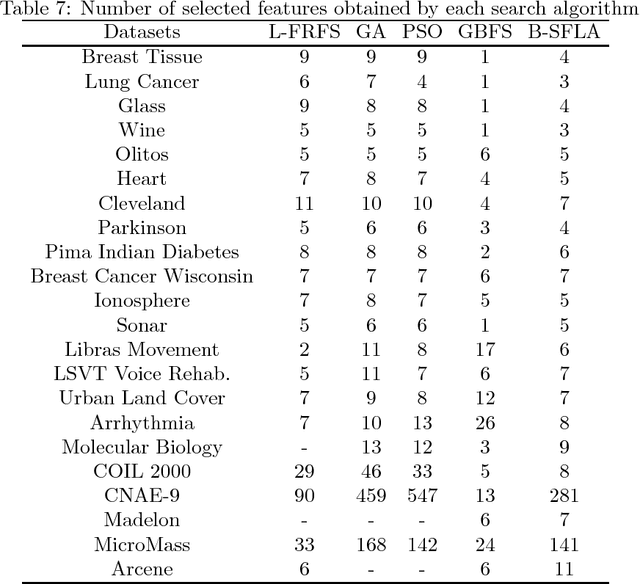

Feature selection and attribute reduction are crucial problems, and widely used techniques in the field of machine learning, data mining and pattern recognition to overcome the well-known phenomenon of the Curse of Dimensionality, by either selecting a subset of features or removing unrelated ones. This paper presents a new feature selection method that efficiently carries out attribute reduction, thereby selecting the most informative features of a dataset. It consists of two components: 1) a measure for feature subset evaluation, and 2) a search strategy. For the evaluation measure, we have employed the fuzzy-rough dependency degree (FRFDD) in the lower approximation-based fuzzy-rough feature selection (L-FRFS) due to its effectiveness in feature selection. As for the search strategy, a new version of a binary shuffled frog leaping algorithm is proposed (B-SFLA). The new feature selection method is obtained by hybridizing the B-SFLA with the FRDD. Non-parametric statistical tests are conducted to compare the proposed approach with several existing methods over twenty two datasets, including nine high dimensional and large ones, from the UCI repository. The experimental results demonstrate that the B-SFLA approach significantly outperforms other metaheuristic methods in terms of the number of selected features and the classification accuracy.
Comparison of different T-norm operators in classification problems
Aug 09, 2012



Fuzzy rule based classification systems are one of the most popular fuzzy modeling systems used in pattern classification problems. This paper investigates the effect of applying nine different T-norms in fuzzy rule based classification systems. In the recent researches, fuzzy versions of confidence and support merits from the field of data mining have been widely used for both rules selecting and weighting in the construction of fuzzy rule based classification systems. For calculating these merits the product has been usually used as a T-norm. In this paper different T-norms have been used for calculating the confidence and support measures. Therefore, the calculations in rule selection and rule weighting steps (in the process of constructing the fuzzy rule based classification systems) are modified by employing these T-norms. Consequently, these changes in calculation results in altering the overall accuracy of rule based classification systems. Experimental results obtained on some well-known data sets show that the best performance is produced by employing the Aczel-Alsina operator in terms of the classification accuracy, the second best operator is Dubois-Prade and the third best operator is Dombi. In experiments, we have used 12 data sets with numerical attributes from the University of California, Irvine machine learning repository (UCI).