 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2FAR: Coarse-to-Fine Autoregressive Networks for Precise Probabilistic Forecasting
Dec 22, 2023



We present coarse-to-fine autoregressive networks (C2FAR), a method for modeling the probability distribution of univariate, numeric random variables. C2FAR generates a hierarchical, coarse-to-fine discretization of a variable autoregressively; progressively finer intervals of support are generated from a sequence of binned distributions, where each distribution is conditioned on previously-generated coarser intervals. Unlike prior (flat) binned distributions, C2FAR can represent values with exponentially higher precision, for only a linear increase in complexity. We use C2FAR for probabilistic forecasting via a recurrent neural network, thus modeling time series autoregressively in both space and time. C2FAR is the first method to simultaneously handle discrete and continuous series of arbitrary scale and distribution shape. This flexibility enables a variety of time series use cases, including anomaly detection, interpolation, and compression. C2FAR achieves improvements over the state-of-the-art on several benchmark forecasting datasets.
A Deep Learning Approach to Tongue Detection for Pediatric Population
Sep 28, 2020


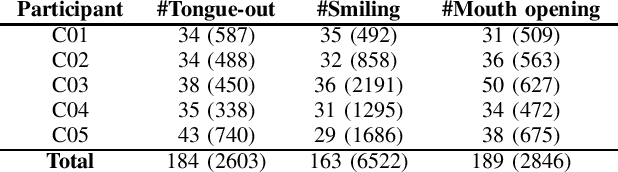
Children with severe disabilities and complex communication needs face limitations in the usage of access technology (AT) devices. Conventional ATs (e.g., mechanical switches) can be insufficient for nonverbal children and those with limited voluntary motion control. Automatic techniques for the detection of tongue gestures represent a promising pathway. Previous studies have shown the robustness of tongue detection algorithms on adult participants, but further research is needed to use these methods with children. In this study, a network architecture for tongue-out gesture recognition was implemented and evaluated on videos recorded in a naturalistic setting when children were playing a video-game. A cascade object detector algorithm was used to detect the participants' faces, and an automated classification scheme for tongue gesture detection was developed using a convolutional neural network (CNN). In evaluation experiments conducted, the network was trained using adults and children's images. The network classification accuracy was evaluated using leave-one-subject-out cross-validation. Preliminary classification results obtained from the analysis of videos of five typically developing children showed an accuracy of up to 99% in predicting tongue-out gestures. Moreover, we demonstrated that using only children data for training the classifier yielded better performance than adult's one supporting the need for pediatric tongue gesture datasets.
Privacy-preserving feature selection: A survey and proposing a new set of protocols
Aug 17, 2020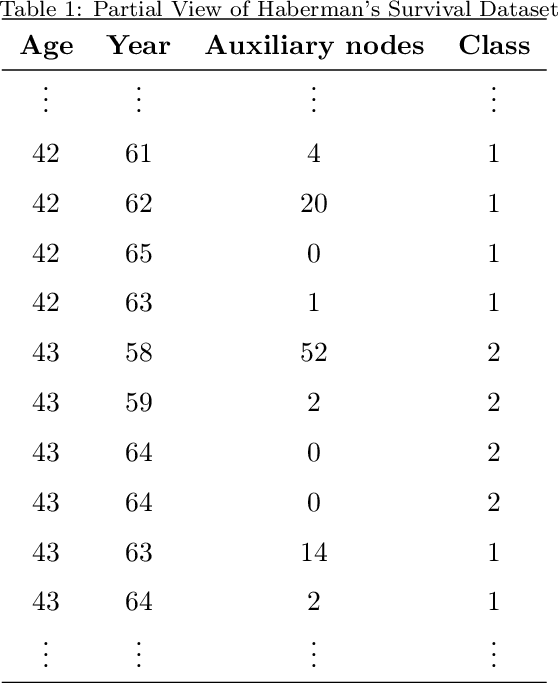
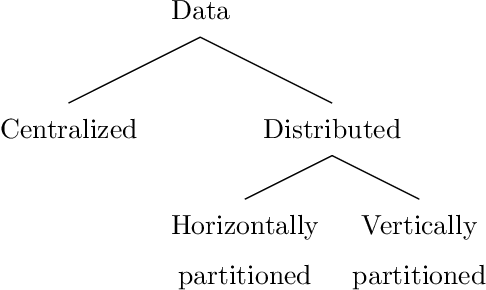
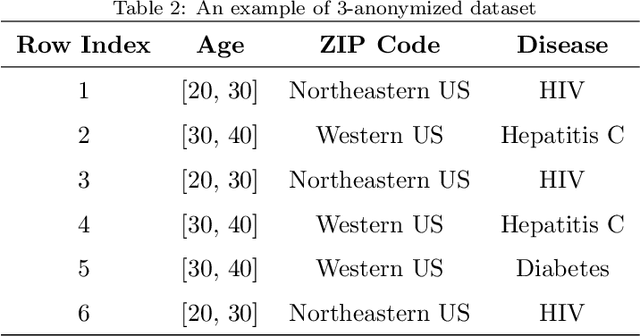
Feature selection is the process of sieving features, in which informative features are separated from the redundant and irrelevant ones. This process plays an important role in machine learning, data mining and bioinformatics. However, traditional feature selection methods are only capable of processing centralized datasets and are not able to satisfy today's distributed data processing needs. These needs require a new category of data processing algorithms called privacy-preserving feature selection, which protects users' data by not revealing any part of the data neither in the intermediate processing nor in the final results. This is vital for the datasets which contain individuals' data, such as medical datasets. Therefore, it is rational to either modify the existing algorithms or propose new ones to not only introduce the capability of being applied to distributed datasets, but also act responsibly in handling users' data by protecting their privacy. In this paper, we will review three privacy-preserving feature selection methods and provide suggestions to improve their performance when any gap is identified. We will also propose a privacy-preserving feature selection method based on the rough set feature selection. The proposed method is capable of processing both horizontally and vertically partitioned datasets in two- and multi-parties scenarios.
Revisiting the Application of Feature Selection Methods to Speech Imagery BCI Datasets
Aug 17, 2020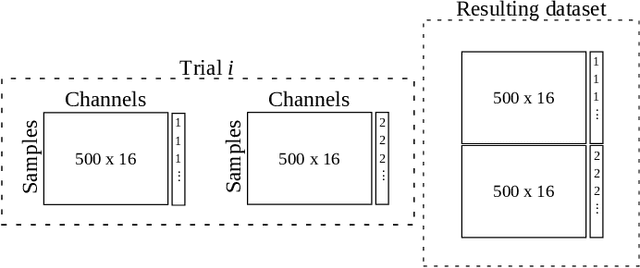
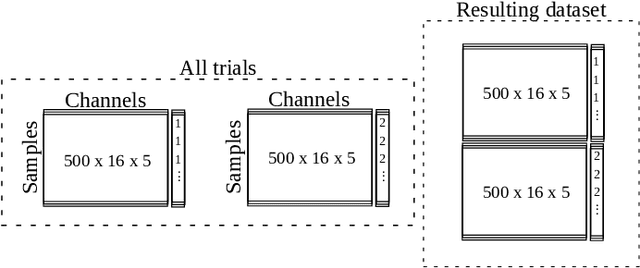
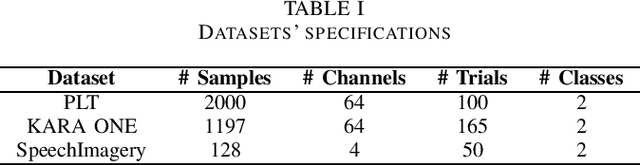
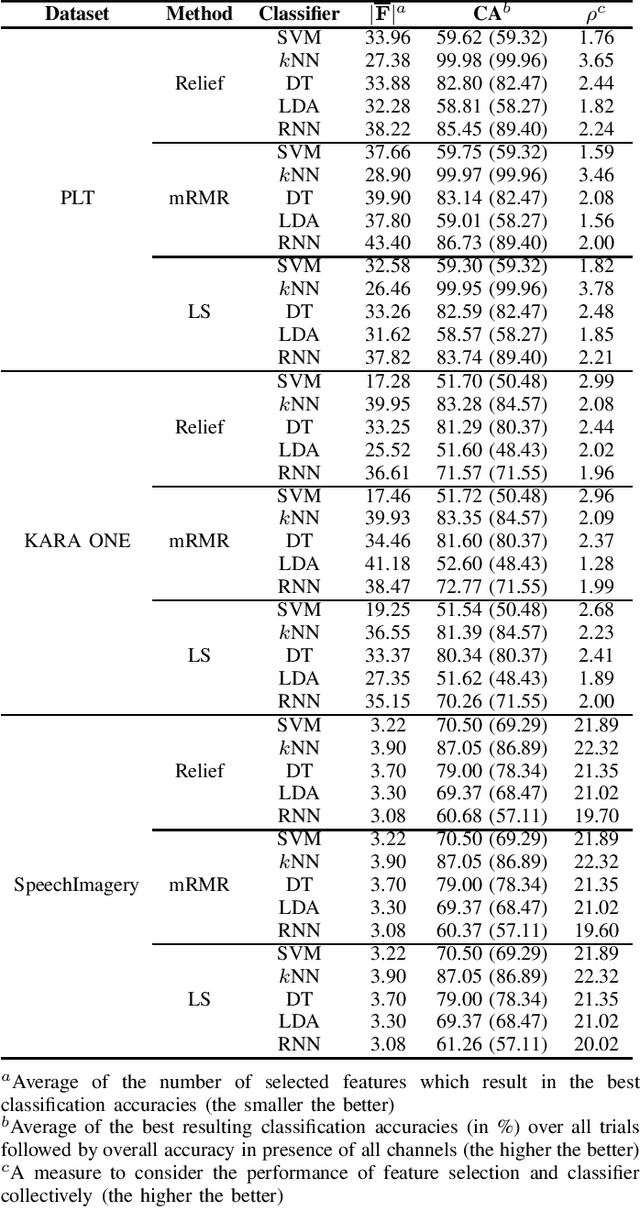
Brain-computer interface (BCI) aims to establish and improve human and computer interactions. There has been an increasing interest in designing new hardware devices to facilitate the collection of brain signals through various technologies, such as wet and dry electroencephalogram (EEG) and functional near-infrared spectroscopy (fNIRS) devices. The promising results of machine learning methods have attracted researchers to apply these methods to their data. However, some methods can be overlooked simply due to their inferior performance against a particular dataset. This paper shows how relatively simple yet powerful feature selection/ranking methods can be applied to speech imagery datasets and generate significant results. To do so, we introduce two approaches, horizontal and vertical settings, to use any feature selection and ranking methods to speech imagery BCI datasets. Our primary goal is to improve the resulting classification accuracies from support vector machines, $k$-nearest neighbour, decision tree, linear discriminant analysis and long short-term memory recurrent neural network classifiers. Our experimental results show that using a small subset of channels, we can retain and, in most cases, improve the resulting classification accuracies regardless of the classifier.
A Feature Selection Based on Perturbation Theory
Feb 26, 2019
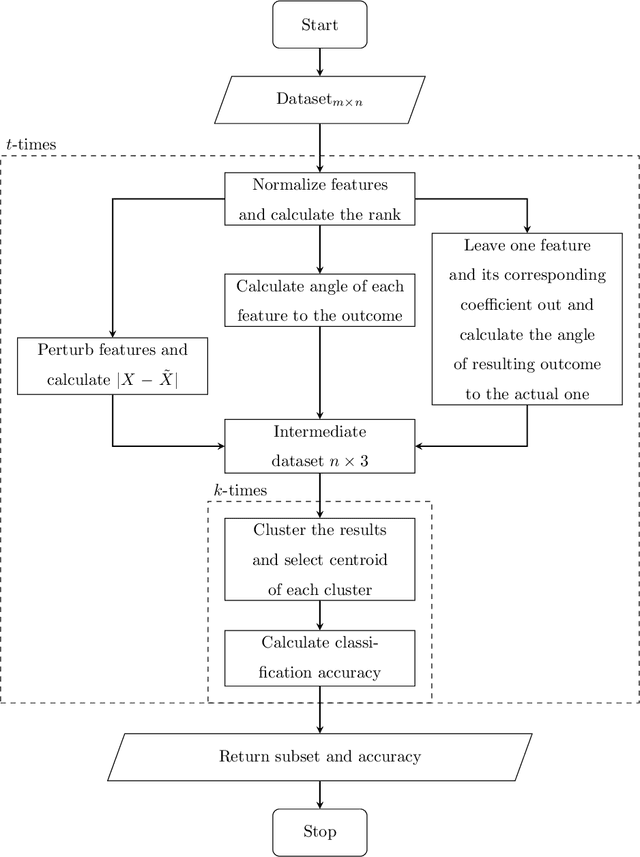


Consider a supervised dataset $D=[A\mid \textbf{b}]$, where $\textbf{b}$ is the outcome column, rows of $D$ correspond to observations, and columns of $A$ are the features of the dataset. A central problem in machine learning and pattern recognition is to select the most important features from $D$ to be able to predict the outcome. In this paper, we provide a new feature selection method where we use perturbation theory to detect correlations between features. We solve $AX=\textbf{b}$ using the method of least squares and singular value decomposition of $A$. In practical applications, such as in bioinformatics, the number of rows of $A$ (observations) are much less than the number of columns of $A$ (features). So we are dealing with singular matrices with big condition numbers. Although it is known that the solutions of least square problems in singular case are very sensitive to perturbations in $A$, our novel approach in this paper is to prove that the correlations between features can be detected by applying perturbations to $A$. The effectiveness of our method is verified by performing a series of comparisons with conventional and novel feature selection methods in the literature. It is demonstrated that in most situations, our method chooses considerably less number of features while attaining or exceeding the accuracy of the other methods.
A Fuzzy-Rough based Binary Shuffled Frog Leaping Algorithm for Feature Selection
Jul 31, 2018

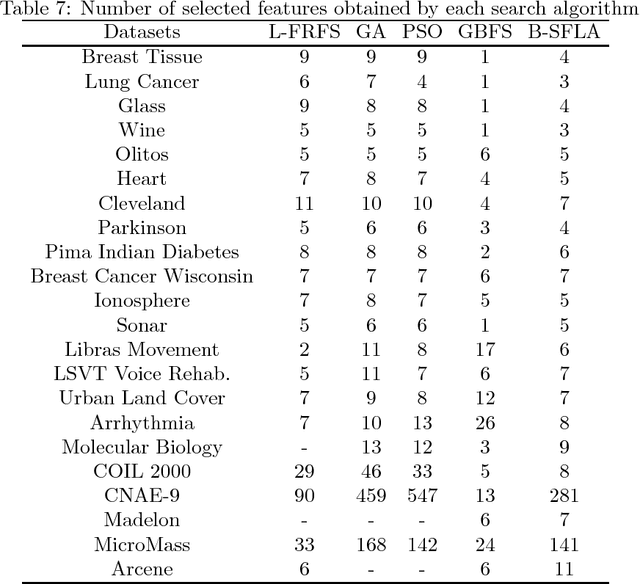

Feature selection and attribute reduction are crucial problems, and widely used techniques in the field of machine learning, data mining and pattern recognition to overcome the well-known phenomenon of the Curse of Dimensionality, by either selecting a subset of features or removing unrelated ones. This paper presents a new feature selection method that efficiently carries out attribute reduction, thereby selecting the most informative features of a dataset. It consists of two components: 1) a measure for feature subset evaluation, and 2) a search strategy. For the evaluation measure, we have employed the fuzzy-rough dependency degree (FRFDD) in the lower approximation-based fuzzy-rough feature selection (L-FRFS) due to its effectiveness in feature selection. As for the search strategy, a new version of a binary shuffled frog leaping algorithm is proposed (B-SFLA). The new feature selection method is obtained by hybridizing the B-SFLA with the FRDD. Non-parametric statistical tests are conducted to compare the proposed approach with several existing methods over twenty two datasets, including nine high dimensional and large ones, from the UCI repository. The experimental results demonstrate that the B-SFLA approach significantly outperforms other metaheuristic methods in terms of the number of selected features and the classification accuracy.