 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feature Selection Based on Perturbation Theory
Paper and Code

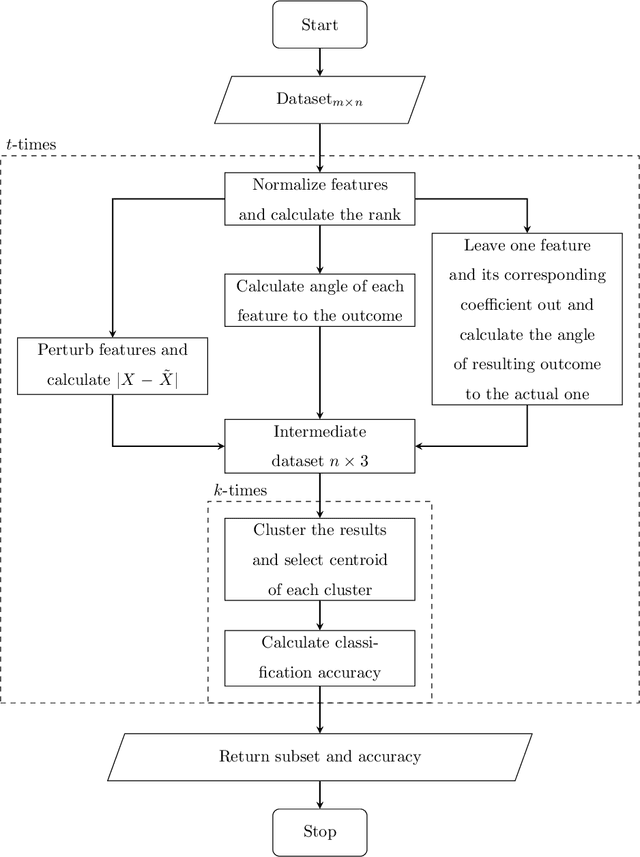


Consider a supervised dataset $D=[A\mid \textbf{b}]$, where $\textbf{b}$ is the outcome column, rows of $D$ correspond to observations, and columns of $A$ are the features of the dataset. A central problem in machine learning and pattern recognition is to select the most important features from $D$ to be able to predict the outcome. In this paper, we provide a new feature selection method where we use perturbation theory to detect correlations between features. We solve $AX=\textbf{b}$ using the method of least squares and singular value decomposition of $A$. In practical applications, such as in bioinformatics, the number of rows of $A$ (observations) are much less than the number of columns of $A$ (features). So we are dealing with singular matrices with big condition numbers. Although it is known that the solutions of least square problems in singular case are very sensitive to perturbations in $A$, our novel approach in this paper is to prove that the correlations between features can be detected by applying perturbations to $A$. The effectiveness of our method is verified by performing a series of comparisons with conventional and novel feature selection methods in the literature. It is demonstrated that in most situations, our method chooses considerably less number of features while attaining or exceeding the accuracy of the other methods.