 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach to Tongue Detection for Pediatric Population
Sep 28, 2020


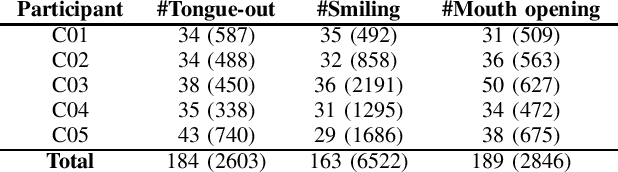
Children with severe disabilities and complex communication needs face limitations in the usage of access technology (AT) devices. Conventional ATs (e.g., mechanical switches) can be insufficient for nonverbal children and those with limited voluntary motion control. Automatic techniques for the detection of tongue gestures represent a promising pathway. Previous studies have shown the robustness of tongue detection algorithms on adult participants, but further research is needed to use these methods with children. In this study, a network architecture for tongue-out gesture recognition was implemented and evaluated on videos recorded in a naturalistic setting when children were playing a video-game. A cascade object detector algorithm was used to detect the participants' faces, and an automated classification scheme for tongue gesture detection was developed using a convolutional neural network (CNN). In evaluation experiments conducted, the network was trained using adults and children's images. The network classification accuracy was evaluated using leave-one-subject-out cross-validation. Preliminary classification results obtained from the analysis of videos of five typically developing children showed an accuracy of up to 99% in predicting tongue-out gestures. Moreover, we demonstrated that using only children data for training the classifier yielded better performance than adult's one supporting the need for pediatric tongue gesture datasets.
Revisiting the Application of Feature Selection Methods to Speech Imagery BCI Datasets
Aug 17, 2020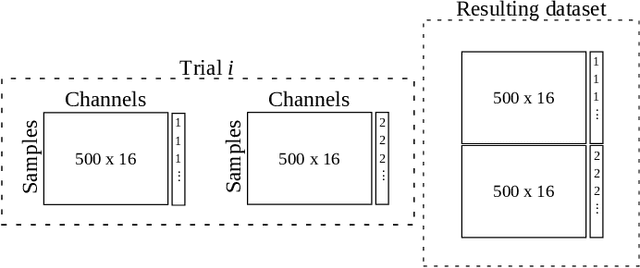
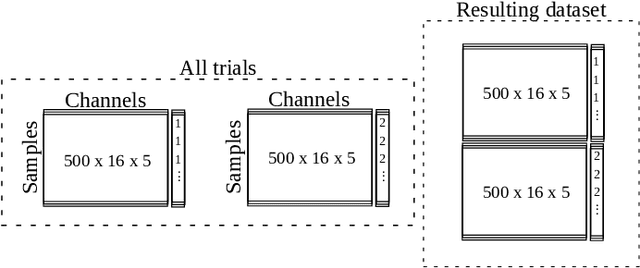
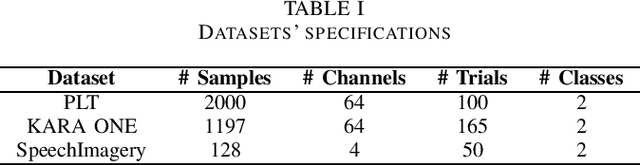
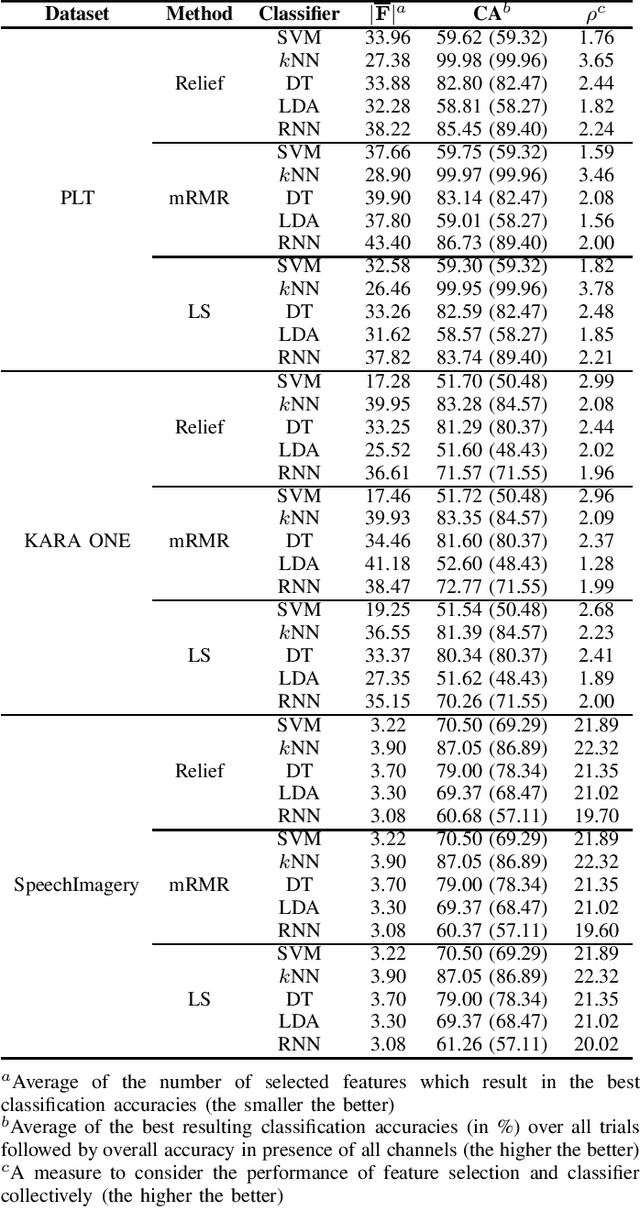
Brain-computer interface (BCI) aims to establish and improve human and computer interactions. There has been an increasing interest in designing new hardware devices to facilitate the collection of brain signals through various technologies, such as wet and dry electroencephalogram (EEG) and functional near-infrared spectroscopy (fNIRS) devices. The promising results of machine learning methods have attracted researchers to apply these methods to their data. However, some methods can be overlooked simply due to their inferior performance against a particular dataset. This paper shows how relatively simple yet powerful feature selection/ranking methods can be applied to speech imagery datasets and generate significant results. To do so, we introduce two approaches, horizontal and vertical settings, to use any feature selection and ranking methods to speech imagery BCI datasets. Our primary goal is to improve the resulting classification accuracies from support vector machines, $k$-nearest neighbour, decision tree, linear discriminant analysis and long short-term memory recurrent neural network classifiers. Our experimental results show that using a small subset of channels, we can retain and, in most cases, improve the resulting classification accuracies regardless of the classifier.