 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved LSHADE-RSP Algorithm with the Cauchy Perturbation: iLSHADE-RSP
Jun 04, 2020
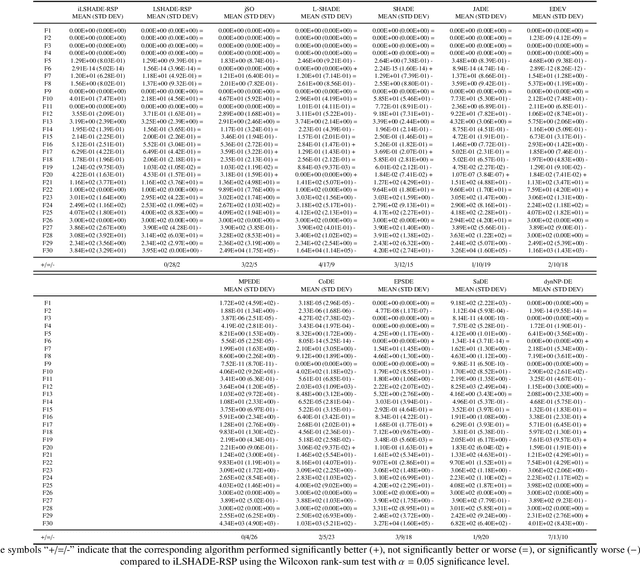
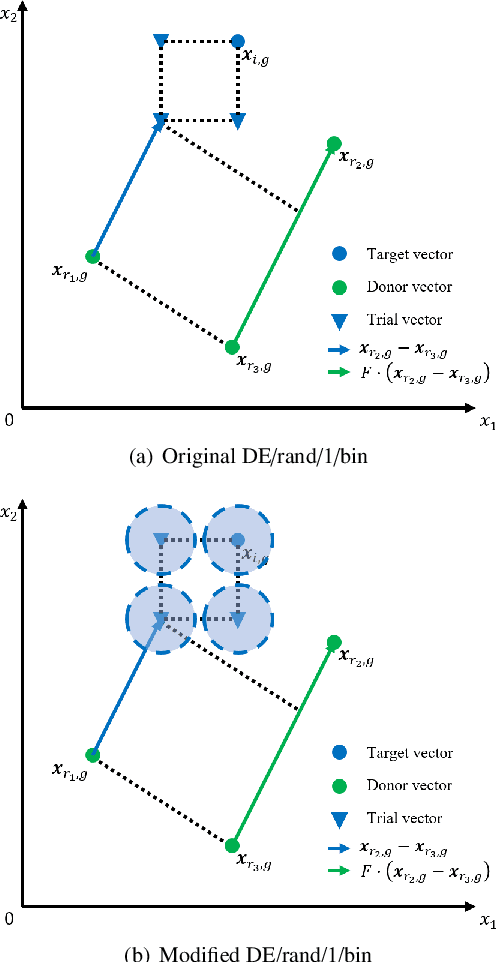

A new method for improving the optimization performance of a state-of-the-art differential evolution (DE) variant is proposed in this paper. The technique can increase the exploration by adopting the long-tailed property of the Cauchy distribution, which helps the algorithm to generate a trial vector with great diversity. Compared to the previous approaches, the proposed approach perturbs a target vector instead of a mutant vector based on a jumping rate. We applied the proposed approach to LSHADE-RSP ranked second place in the CEC 2018 competition on single objective real-valued optimization. A set of 30 different and difficult optimization problems is used to evaluate the optimization performance of the improved LSHADE-RSP. Our experimental results verify that the improved LSHADE-RSP significantly outperformed not only its predecessor LSHADE-RSP but also several cutting-edge DE variants in terms of convergence speed and solution accuracy.
A Fuzzy-Rough based Binary Shuffled Frog Leaping Algorithm for Feature Selection
Jul 31, 2018

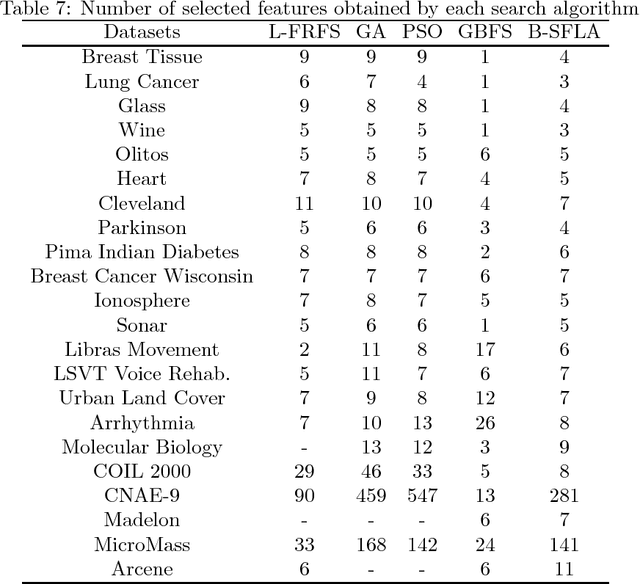

Feature selection and attribute reduction are crucial problems, and widely used techniques in the field of machine learning, data mining and pattern recognition to overcome the well-known phenomenon of the Curse of Dimensionality, by either selecting a subset of features or removing unrelated ones. This paper presents a new feature selection method that efficiently carries out attribute reduction, thereby selecting the most informative features of a dataset. It consists of two components: 1) a measure for feature subset evaluation, and 2) a search strategy. For the evaluation measure, we have employed the fuzzy-rough dependency degree (FRFDD) in the lower approximation-based fuzzy-rough feature selection (L-FRFS) due to its effectiveness in feature selection. As for the search strategy, a new version of a binary shuffled frog leaping algorithm is proposed (B-SFLA). The new feature selection method is obtained by hybridizing the B-SFLA with the FRDD. Non-parametric statistical tests are conducted to compare the proposed approach with several existing methods over twenty two datasets, including nine high dimensional and large ones, from the UCI repository. The experimental results demonstrate that the B-SFLA approach significantly outperforms other metaheuristic methods in terms of the number of selected features and the classification accuracy.