 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGDA: Hierarchical Graph of Nodes to Learn Local-to-Global Topology for Semi-Supervised Domain Adaptation
Dec 16, 2024The enhanced representational power and broad applicability of deep learning models have attracted significant interest from the research community in recent years. However, these models often struggle to perform effectively under domain shift conditions, where the training data (the source domain) is related to but exhibits different distributions from the testing data (the target domain). To address this challenge, previous studies have attempted to reduce the domain gap between source and target data by incorporating a few labeled target samples during training - a technique known as semi-supervised domain adaptation (SSDA). While this strategy has demonstrated notable improvements in classification performance, the network architectures used in these approaches primarily focus on exploiting the features of individual images, leaving room for improvement in capturing rich representations. In this study, we introduce a Hierarchical Graph of Nodes designed to simultaneously present representations at both feature and category levels. At the feature level, we introduce a local graph to identify the most relevant patches within an image, facilitating adaptability to defined main object representations. At the category level, we employ a global graph to aggregate the features from samples within the same category, thereby enriching overall representations. Extensive experiments on widely used SSDA benchmark datasets, including Office-Home, DomainNet, and VisDA2017, demonstrate that both quantitative and qualitative results substantiate the effectiveness of HiGDA, establishing it as a new state-of-the-art method.
Learning CNN on ViT: A Hybrid Model to Explicitly Class-specific Boundaries for Domain Adaptation
Apr 02, 2024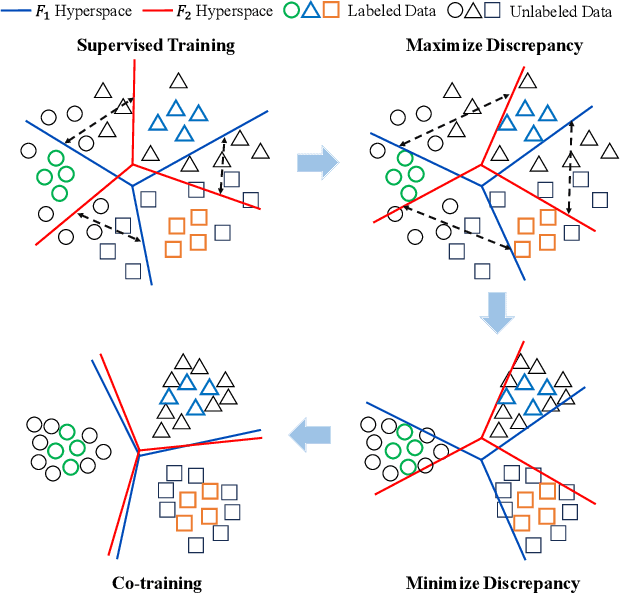
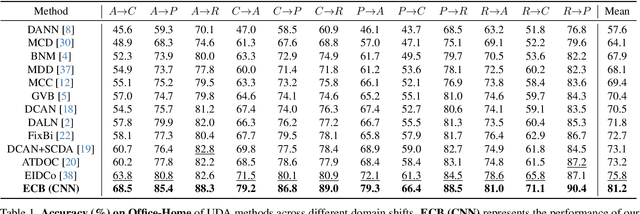
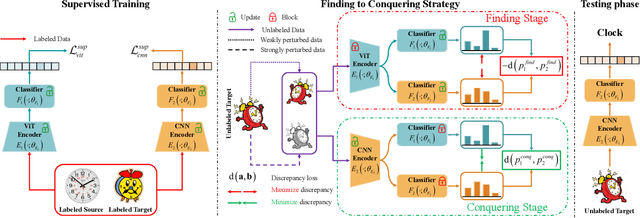
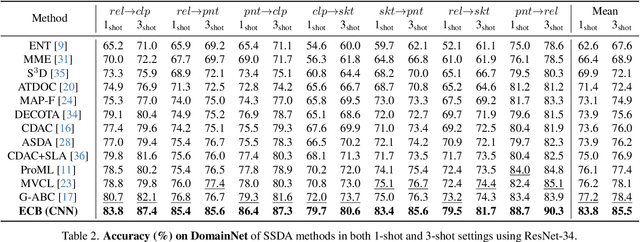
Most domain adaptation (DA) methods are based on either a convolutional neural networks (CNNs) or a vision transformers (ViTs). They align the distribution differences between domains as encoders without considering their unique characteristics. For instance, ViT excels in accuracy due to its superior ability to capture global representations, while CNN has an advantage in capturing local representations. This fact has led us to design a hybrid method to fully take advantage of both ViT and CNN, called Explicitly Class-specific Boundaries (ECB). ECB learns CNN on ViT to combine their distinct strengths. In particular, we leverage ViT's properties to explicitly find class-specific decision boundaries by maximizing the discrepancy between the outputs of the two classifiers to detect target samples far from the source support. In contrast, the CNN encoder clusters target features based on the previously defined class-specific boundaries by minimizing the discrepancy between the probabilities of the two classifiers. Finally, ViT and CNN mutually exchange knowledge to improve the quality of pseudo labels and reduce the knowledge discrepancies of these models. Compared to conventional DA methods, our ECB achieves superior performance, which verifies its effectiveness in this hybrid model. The project website can be found https://dotrannhattuong.github.io/ECB/website/.
CLEAR: Cross-Transformers with Pre-trained Language Model is All you need for Person Attribute Recognition and Retrieval
Mar 10, 2024



Person attribute recognition and attribute-based retrieval are two core human-centric tasks. In the recognition task, the challenge is specifying attributes depending on a person's appearance, while the retrieval task involves searching for matching persons based on attribute queries. There is a significant relationship between recognition and retrieval tasks. In this study, we demonstrate that if there is a sufficiently robust network to solve person attribute recognition, it can be adapted to facilitate better performance for the retrieval task. Another issue that needs addressing in the retrieval task is the modality gap between attribute queries and persons' images. Therefore, in this paper, we present CLEAR, a unified network designed to address both tasks. We introduce a robust cross-transformers network to handle person attribute recognition. Additionally, leveraging a pre-trained language model, we construct pseudo-descriptions for attribute queries and introduce an effective training strategy to train only a few additional parameters for adapters, facilitating the handling of the retrieval task. Finally, the unified CLEAR model is evaluated on five benchmarks: PETA, PA100K, Market-1501, RAPv2, and UPAR-2024. Without bells and whistles, CLEAR achieves state-of-the-art performance or competitive results for both tasks, significantly outperforming other competitors in terms of person retrieval performance on the widely-used Market-1501 dataset.
Self-Referential Quality Diversity Through Differential Map-Elites
Jul 11, 2021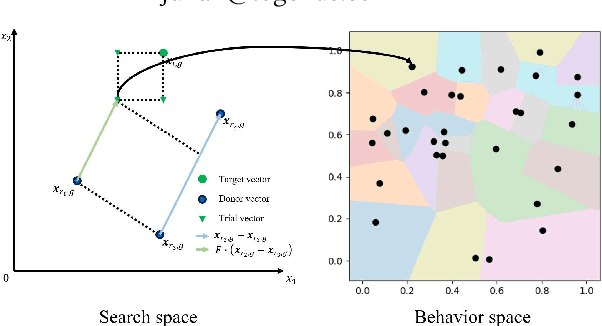
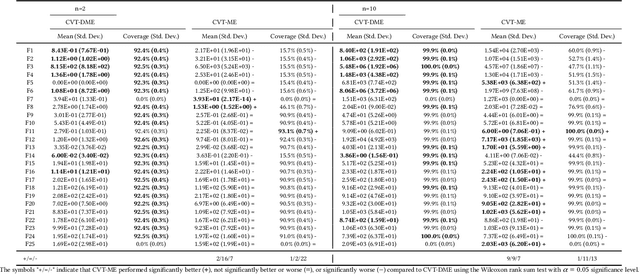
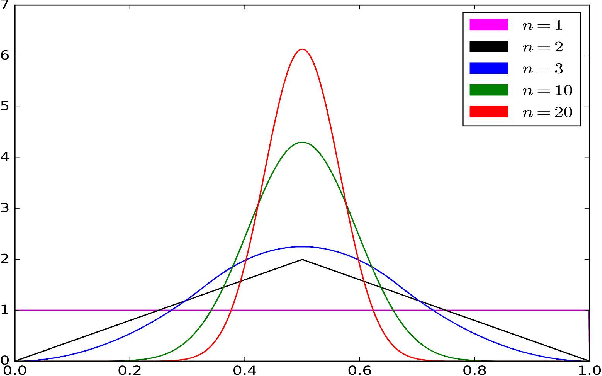
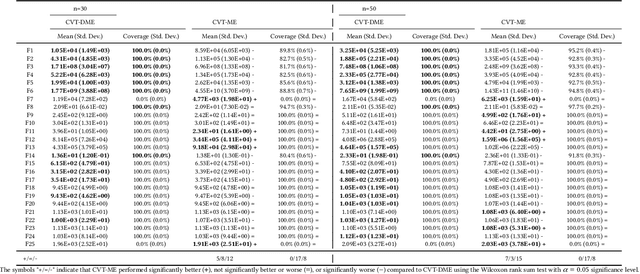
Differential MAP-Elites is a novel algorithm that combines the illumination capacity of CVT-MAP-Elites with the continuous-space optimization capacity of Differential Evolution. The algorithm is motivated by observations that illumination algorithms, and quality-diversity algorithms in general, offer qualitatively new capabilities and applications for evolutionary computation yet are in their original versions relatively unsophisticated optimizers. The basic Differential MAP-Elites algorithm, introduced for the first time here, is relatively simple in that it simply combines the operators from Differential Evolution with the map structure of CVT-MAP-Elites. Experiments based on 25 numerical optimization problems suggest that Differential MAP-Elites clearly outperforms CVT-MAP-Elites, finding better-quality and more diverse solutions.
An Improved LSHADE-RSP Algorithm with the Cauchy Perturbation: iLSHADE-RSP
Jun 04, 2020
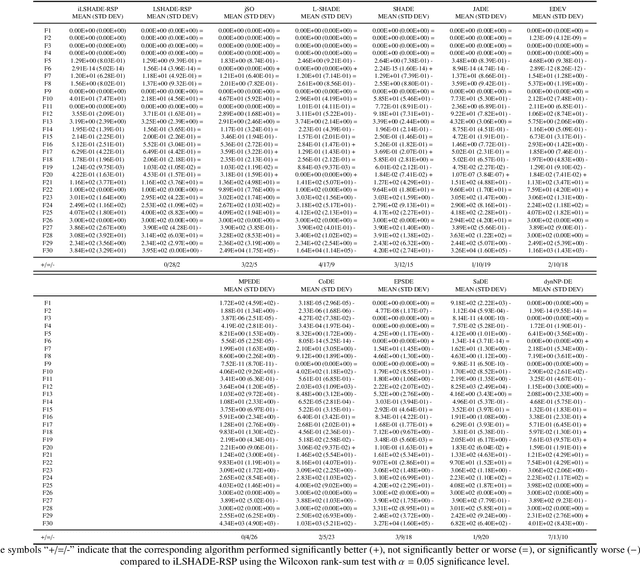
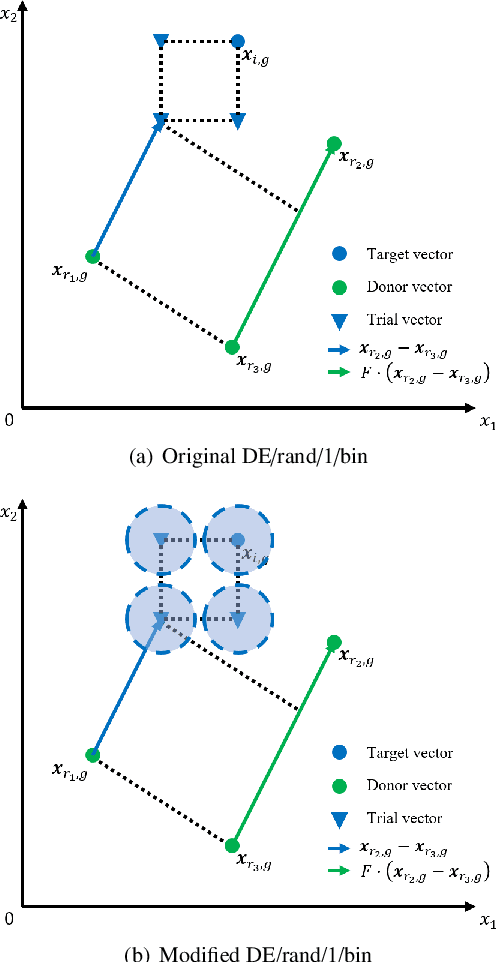

A new method for improving the optimization performance of a state-of-the-art differential evolution (DE) variant is proposed in this paper. The technique can increase the exploration by adopting the long-tailed property of the Cauchy distribution, which helps the algorithm to generate a trial vector with great diversity. Compared to the previous approaches, the proposed approach perturbs a target vector instead of a mutant vector based on a jumping rate. We applied the proposed approach to LSHADE-RSP ranked second place in the CEC 2018 competition on single objective real-valued optimization. A set of 30 different and difficult optimization problems is used to evaluate the optimization performance of the improved LSHADE-RSP. Our experimental results verify that the improved LSHADE-RSP significantly outperformed not only its predecessor LSHADE-RSP but also several cutting-edge DE variants in terms of convergence speed and solution accuracy.
A Fast and Efficient Stochastic Opposition-Based Learning for Differential Evolution in Numerical Optimization
Aug 09, 2019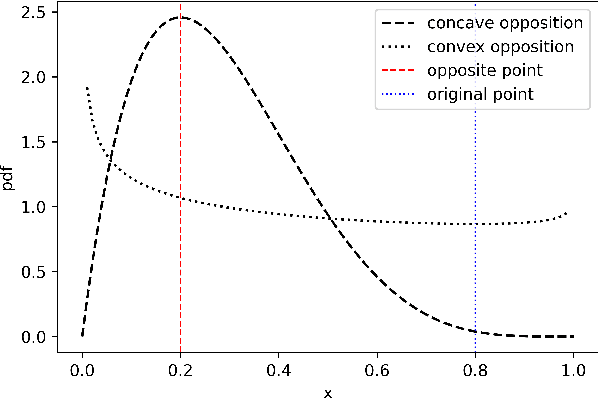
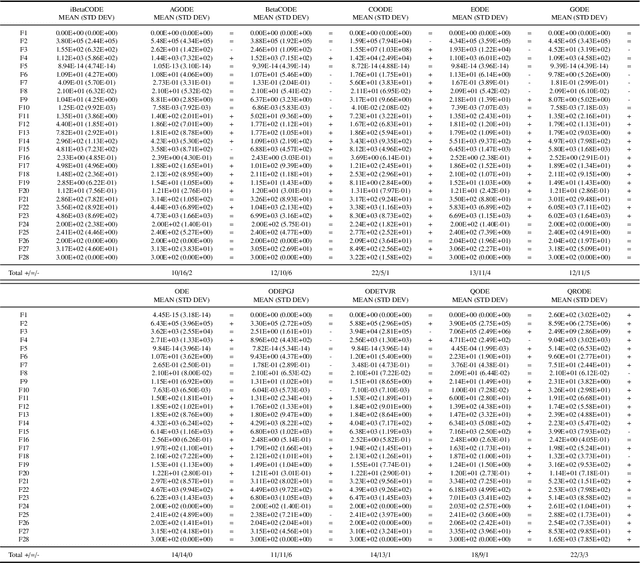
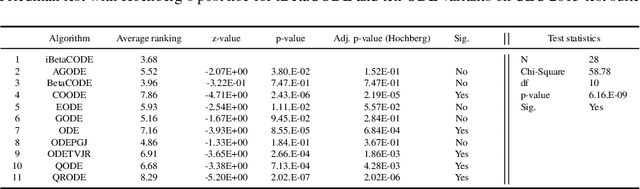
A new variant of stochastic opposition-based learning (OBL) is proposed in this paper. OBL is a relatively new machine learning concept, which consists of simultaneously calculating an original solution and its opposite to accelerate the convergence of soft computing algorithms. Recently a new opposition-based differential evolution (ODE) variant called BetaCODE was proposed as a combination of differential evolution and a new stochastic OBL variant called BetaCOBL. BetaCOBL is capable of flexibly adjusting the probability density functions used to calculate opposite solutions, generating more diverse opposite solutions, and preventing the waste of fitness evaluations. While it has shown outstanding performance compared to several state-of-the-art OBL variants, BetaCOBL is challenging with more complex problems because of its high computational cost. Besides, as it assumes that the decision variables are independent, there is a limitation in the search for decent opposite solutions on inseparable problems. In this paper, we propose an improved stochastic OBL variant that mitigates all the limitations of BetaCOBL. The proposed algorithm called iBetaCOBL reduces the computational cost from $O(NP^{2} \cdot D)$ to $O(NP \cdot D)$ ($NP$ and $D$ stand for population size and dimension, respectively) using a linear time diversity measure. In addition, iBetaCOBL preserves the strongly dependent decision variables that are adjacent to each other using the multiple exponential crossover. The results of the performance evaluations on a set of 58 test functions show that iBetaCODE finds more accurate solutions than ten state-of-the-art ODE variants including BetaCODE. Additionally, we applied iBetaCOBL to two state-of-the-art DE variants, and as in the previous results, iBetaCOBL based variants exhibit significantly improved performance.
ACM-DE: Adaptive p-best Cauchy Mutation with linear failure threshold reduction for Differential Evolution in numerical optimization
Jul 01, 2019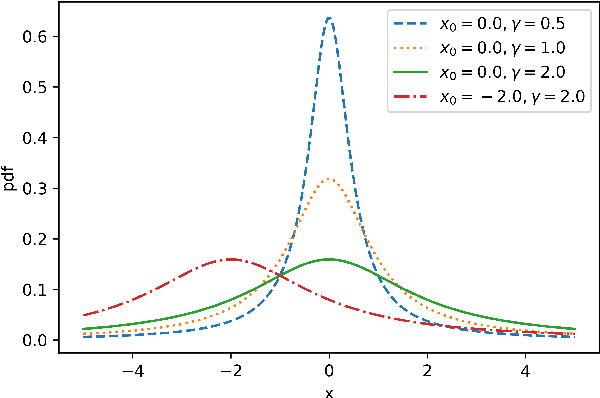
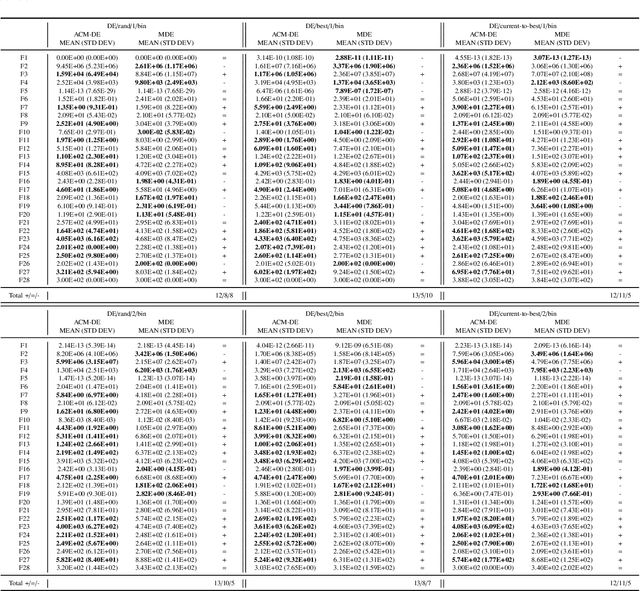
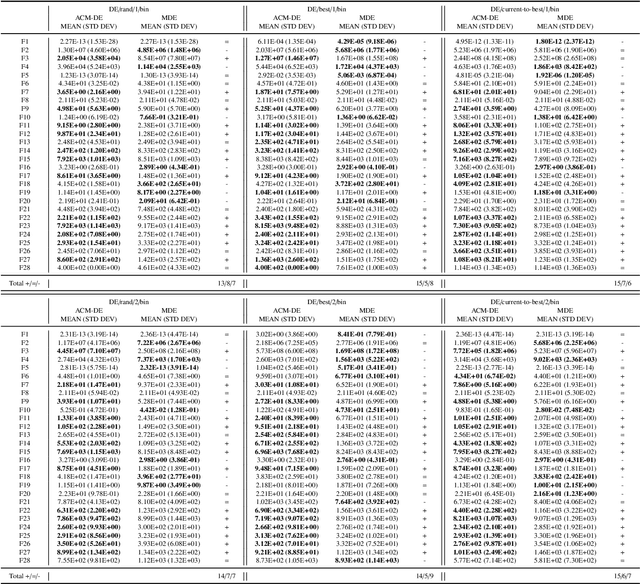
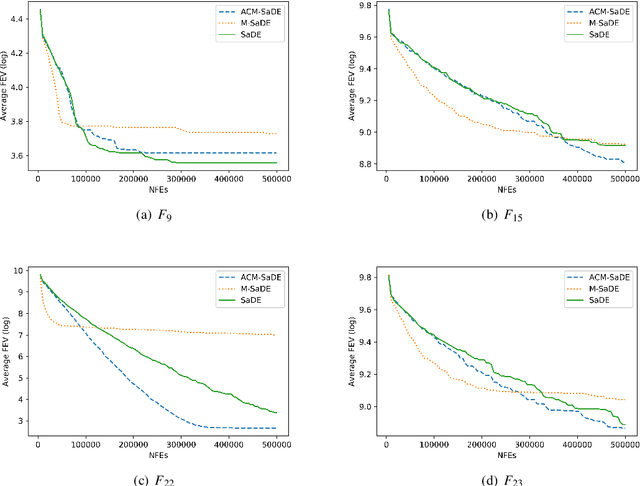
Differential evolution (DE) is an efficient evolutionary algorithm for optimizing continuous optimization problems. Although DE has been successfully applied to various real-world problems, it suffers from premature convergence where all individuals converge to a suboptimal solution too early. To address this problem, modified DE that uses the Cauchy mutation was proposed, but it has serious limitations of 1) controlling the balance between exploration and exploitation; 2) adjusting the algorithm to a given problem; 3) having less reliable performance on multimodal problems. In this paper, we propose a new adaptive Cauchy mutation based DE variant called ACM-DE (Adaptive Cauchy Mutation Differential Evolution), which removes all of these limitations. Specifically, two popular parameter controls are employed for the exploration and exploitation scheme and robust performance. Also, a less greedy approach is employed, which uses any of the top p% individuals in the phase of the Cauchy mutation. Experimental results on a set of 58 benchmark problems show that ACM-DE is capable of finding more accurate solutions than modified DE, especially for multimodal problems. In addition, we applied ACM to two state-of-the-art DE variants, and similar to the previous results, ACM based variants exhibit significantly improved performance.