 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMortar: Evolving Mechanics for Automatic Game Design
Dec 31, 2025We present Mortar, a system for autonomously evolving game mechanics for automatic game design. Game mechanics define the rules and interactions that govern gameplay, and designing them manually is a time-consuming and expert-driven process. Mortar combines a quality-diversity algorithm with a large language model to explore a diverse set of mechanics, which are evaluated by synthesising complete games that incorporate both evolved mechanics and those drawn from an archive. The mechanics are evaluated by composing complete games through a tree search procedure, where the resulting games are evaluated by their ability to preserve a skill-based ordering over players -- that is, whether stronger players consistently outperform weaker ones. We assess the mechanics based on their contribution towards the skill-based ordering score in the game. We demonstrate that Mortar produces games that appear diverse and playable, and mechanics that contribute more towards the skill-based ordering score in the game. We perform ablation studies to assess the role of each system component and a user study to evaluate the games based on human feedback.
Video Game Level Design as a Multi-Agent Reinforcement Learning Problem
Oct 06, 2025Procedural Content Generation via Reinforcement Learning (PCGRL) offers a method for training controllable level designer agents without the need for human datasets, using metrics that serve as proxies for level quality as rewards. Existing PCGRL research focuses on single generator agents, but are bottlenecked by the need to frequently recalculate heuristics of level quality and the agent's need to navigate around potentially large maps. By framing level generation as a multi-agent problem, we mitigate the efficiency bottleneck of single-agent PCGRL by reducing the number of reward calculations relative to the number of agent actions. We also find that multi-agent level generators are better able to generalize to out-of-distribution map shapes, which we argue is due to the generators' learning more local, modular design policies. We conclude that treating content generation as a distributed, multi-agent task is beneficial for generating functional artifacts at scale.
GVGAI-LLM: Evaluating Large Language Model Agents with Infinite Games
Aug 11, 2025We introduce GVGAI-LLM, a video game benchmark for evaluating the reasoning and problem-solving capabilities of large language models (LLMs). Built on the General Video Game AI framework, it features a diverse collection of arcade-style games designed to test a model's ability to handle tasks that differ from most existing LLM benchmarks. The benchmark leverages a game description language that enables rapid creation of new games and levels, helping to prevent overfitting over time. Each game scene is represented by a compact set of ASCII characters, allowing for efficient processing by language models. GVGAI-LLM defines interpretable metrics, including the meaningful step ratio, step efficiency, and overall score, to assess model behavior. Through zero-shot evaluations across a broad set of games and levels with diverse challenges and skill depth, we reveal persistent limitations of LLMs in spatial reasoning and basic planning. Current models consistently exhibit spatial and logical errors, motivating structured prompting and spatial grounding techniques. While these interventions lead to partial improvements, the benchmark remains very far from solved. GVGAI-LLM provides a reproducible testbed for advancing research on language model capabilities, with a particular emphasis on agentic behavior and contextual reasoning.
Evolutionary Level Repair
Jun 24, 2025We address the problem of game level repair, which consists of taking a designed but non-functional game level and making it functional. This might consist of ensuring the completeness of the level, reachability of objects, or other performance characteristics. The repair problem may also be constrained in that it can only make a small number of changes to the level. We investigate search-based solutions to the level repair problem, particularly using evolutionary and quality-diversity algorithms, with good results. This level repair method is applied to levels generated using a machine learning-based procedural content generation (PCGML) method that generates stylistically appropriate but frequently broken levels. This combination of PCGML for generation and search-based methods for repair shows great promise as a hybrid procedural content generation (PCG) method.
ScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search
Jun 06, 2025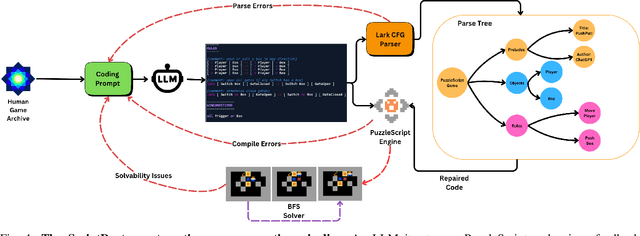


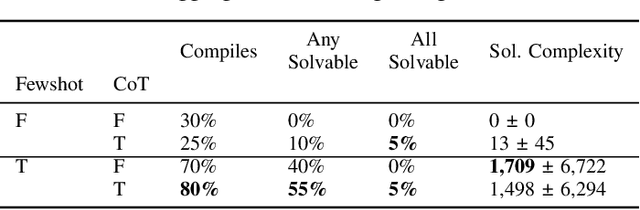
There is much interest in using large pre-trained models in Automatic Game Design (AGD), whether via the generation of code, assets, or more abstract conceptualization of design ideas. But so far this interest largely stems from the ad hoc use of such generative models under persistent human supervision. Much work remains to show how these tools can be integrated into longer-time-horizon AGD pipelines, in which systems interface with game engines to test generated content autonomously. To this end, we introduce ScriptDoctor, a Large Language Model (LLM)-driven system for automatically generating and testing games in PuzzleScript, an expressive but highly constrained description language for turn-based puzzle games over 2D gridworlds. ScriptDoctor generates and tests game design ideas in an iterative loop, where human-authored examples are used to ground the system's output, compilation errors from the PuzzleScript engine are used to elicit functional code, and search-based agents play-test generated games. ScriptDoctor serves as a concrete example of the potential of automated, open-ended LLM-based workflows in generating novel game content.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
Enhancing Player Enjoyment with a Two-Tier DRL and LLM-Based Agent System for Fighting Games
Apr 10, 2025Deep reinforcement learning (DRL) has effectively enhanced gameplay experiences and game design across various game genres. However, few studies on fighting game agents have focused explicitly on enhancing player enjoyment, a critical factor for both developers and players. To address this gap and establish a practical baseline for designing enjoyability-focused agents, we propose a two-tier agent (TTA) system and conducted experiments in the classic fighting game Street Fighter II. The first tier of TTA employs a task-oriented network architecture, modularized reward functions, and hybrid training to produce diverse and skilled DRL agents. In the second tier of TTA, a Large Language Model Hyper-Agent, leveraging players' playing data and feedback, dynamically selects suitable DRL opponents. In addition, we investigate and model several key factors that affect the enjoyability of the opponent. The experiments demonstrate improvements from 64. 36% to 156. 36% in the execution of advanced skills over baseline methods. The trained agents also exhibit distinct game-playing styles. Additionally, we conducted a small-scale user study, and the overall enjoyment in the player's feedback validates the effectiveness of our TTA system.
The Procedural Content Generation Benchmark: An Open-source Testbed for Generative Challenges in Games
Mar 27, 2025This paper introduces the Procedural Content Generation Benchmark for evaluating generative algorithms on different game content creation tasks. The benchmark comes with 12 game-related problems with multiple variants on each problem. Problems vary from creating levels of different kinds to creating rule sets for simple arcade games. Each problem has its own content representation, control parameters, and evaluation metrics for quality, diversity, and controllability. This benchmark is intended as a first step towards a standardized way of comparing generative algorithms. We use the benchmark to score three baseline algorithms: a random generator, an evolution strategy, and a genetic algorithm. Results show that some problems are easier to solve than others, as well as the impact the chosen objective has on quality, diversity, and controllability of the generated artifacts.
Word2Minecraft: Generating 3D Game Levels through Large Language Models
Mar 18, 2025We present Word2Minecraft, a system that leverages large language models to generate playable game levels in Minecraft based on structured stories. The system transforms narrative elements-such as protagonist goals, antagonist challenges, and environmental settings-into game levels with both spatial and gameplay constraints. We introduce a flexible framework that allows for the customization of story complexity, enabling dynamic level generation. The system employs a scaling algorithm to maintain spatial consistency while adapting key game elements. We evaluate Word2Minecraft using both metric-based and human-based methods. Our results show that GPT-4-Turbo outperforms GPT-4o-Mini in most areas, including story coherence and objective enjoyment, while the latter excels in aesthetic appeal. We also demonstrate the system' s ability to generate levels with high map enjoyment, offering a promising step forward in the intersection of story generation and game design. We open-source the code at https://github.com/JMZ-kk/Word2Minecraft/tree/word2mc_v0
Amorphous Fortress Online: Collaboratively Designing Open-Ended Multi-Agent AI and Game Environments
Feb 08, 2025



This work introduces Amorphous Fortress Online -- a web-based platform where users can design petri-dish-like environments and games consisting of multi-agent AI characters. Users can play, create, and share artificial life and game environments made up of microscopic but transparent finite-state machine agents that interact with each other. The website features multiple interactive editors and accessible settings to view the multi-agent interactions directly from the browser. This system serves to provide a database of thematically diverse AI and game environments that use the emergent behaviors of simple AI agents.