 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Bots for Tactical Shooters Using Compute-Efficient Sensors
Dec 30, 2024



Artificial intelligence (AI) has enabled agents to master complex video games, from first-person shooters like Counter-Strike to real-time strategy games such as StarCraft II and racing games like Gran Turismo. While these achievements are notable, applying these AI methods in commercial video game production remains challenging due to computational constraints. In commercial scenarios, the majority of computational resources are allocated to 3D rendering, leaving limited capacity for AI methods, which often demand high computational power, particularly those relying on pixel-based sensors. Moreover, the gaming industry prioritizes creating human-like behavior in AI agents to enhance player experience, unlike academic models that focus on maximizing game performance. This paper introduces a novel methodology for training neural networks via imitation learning to play a complex, commercial-standard, VALORANT-like 2v2 tactical shooter game, requiring only modest CPU hardware during inference. Our approach leverages an innovative, pixel-free perception architecture using a small set of ray-cast sensors, which capture essential spatial information efficiently. These sensors allow AI to perform competently without the computational overhead of traditional methods. Models are trained to mimic human behavior using supervised learning on human trajectory data, resulting in realistic and engaging AI agents. Human evaluation tests confirm that our AI agents provide human-like gameplay experiences while operating efficiently under computational constraints. This offers a significant advancement in AI model development for tactical shooter games and possibly other genres.
Capturing Local and Global Patterns in Procedural Content Generation via Machine Learning
May 26, 2020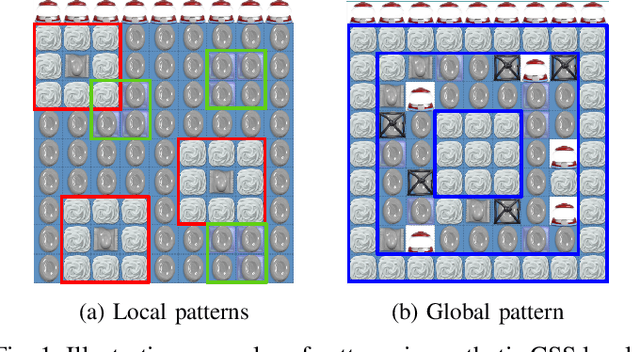
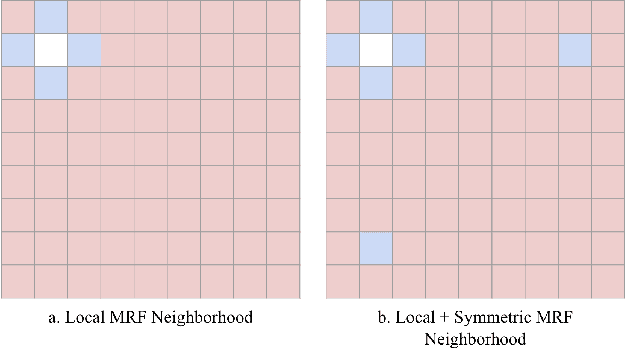

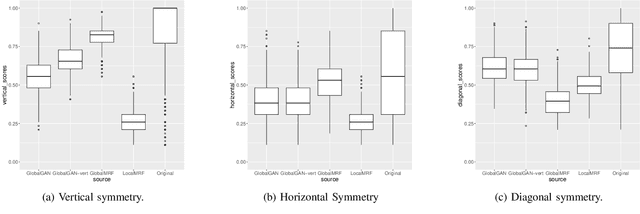
Recent procedural content generation via machine learning (PCGML) methods allow learning from existing content to produce similar content automatically. While these approaches are able to generate content for different games (e.g. Super Mario Bros., DOOM, Zelda, and Kid Icarus), it is an open questions how well these approaches can capture large-scale visual patterns such as symmetry. In this paper, we propose match-three games as a domain to test PCGML algorithms regarding their ability to generate suitable patterns. We demonstrate that popular algorithm such as Generative Adversarial Networks struggle in this domain and propose adaptations to improve their performance. In particular we augment the neighborhood of a Markov Random Fields approach to not only take local but also symmetric positional information into account. We conduct several empirical tests including a user study that show the improvements achieved by the proposed modifications, and obtain promising results.
Bootstrapping Conditional GANs for Video Game Level Generation
Oct 03, 2019
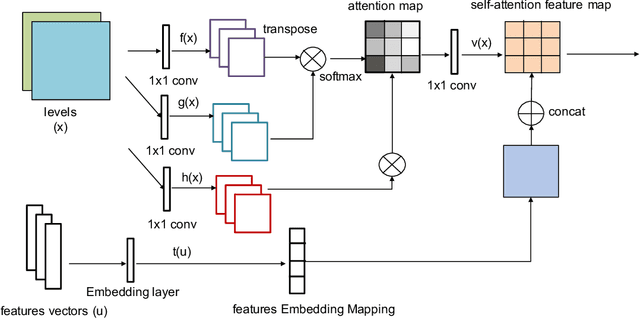
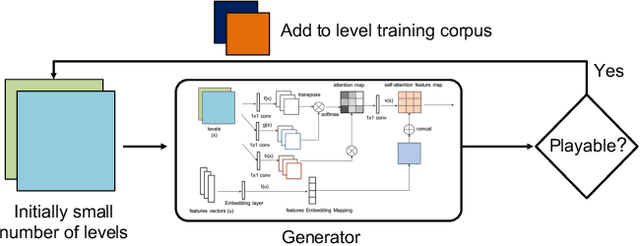
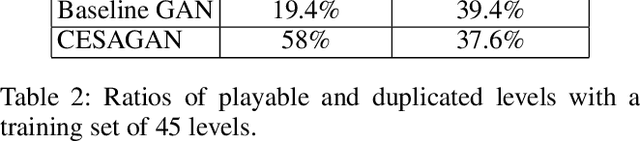
Generative Adversarial Networks (GANs) have shown im-pressive results for image generation. However, GANs facechallenges in generating contents with certain types of con-straints, such as game levels. Specifically, it is difficult togenerate levels that have aesthetic appeal and are playable atthe same time. Additionally, because training data usually islimited, it is challenging to generate unique levels with cur-rent GANs. In this paper, we propose a new GAN architec-ture namedConditional Embedding Self-Attention Genera-tive Adversarial Network(CESAGAN) and a new bootstrap-ping training procedure. The CESAGAN is a modification ofthe self-attention GAN that incorporates an embedding fea-ture vector input to condition the training of the discriminatorand generator. This allows the network to model non-localdependency between game objects, and to count objects. Ad-ditionally, to reduce the number of levels necessary to trainthe GAN, we propose a bootstrapping mechanism in whichplayable generated levels are added to the training set. Theresults demonstrate that the new approach does not only gen-erate a larger number of levels that are playable but also gen-erates fewer duplicate levels compared to a standard GAN.
Learning a Behavioral Repertoire from Demonstrations
Jul 05, 2019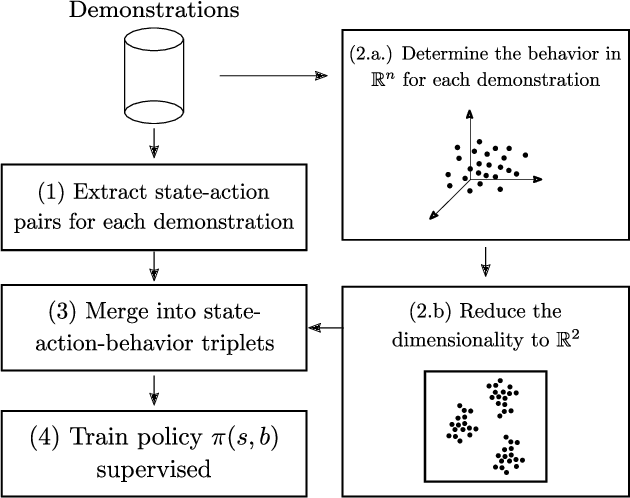
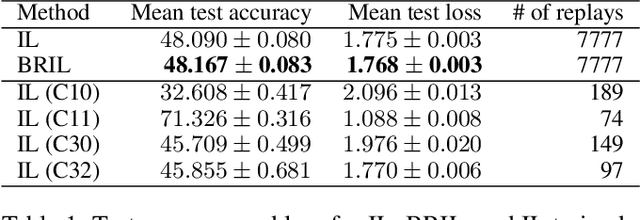
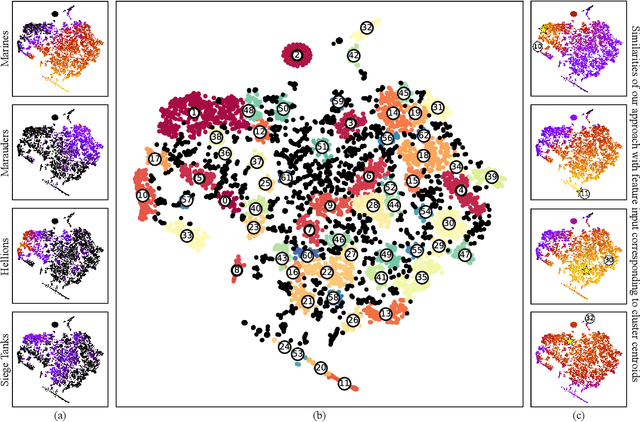
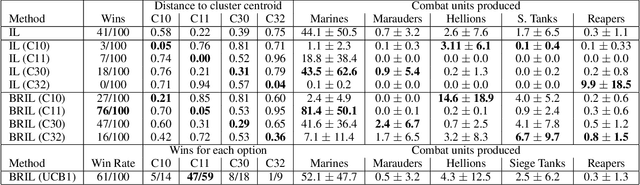
Imitation Learning (IL) is a machine learning approach to learn a policy from a dataset of demonstrations. IL can be useful to kick-start learning before applying reinforcement learning (RL) but it can also be useful on its own, e.g. to learn to imitate human players in video games. However, a major limitation of current IL approaches is that they learn only a single "average" policy based on a dataset that possibly contains demonstrations of numerous different types of behaviors. In this paper, we propose a new approach called Behavioral Repertoire Imitation Learning (BRIL) that instead learns a repertoire of behaviors from a set of demonstrations by augmenting the state-action pairs with behavioral descriptions. The outcome of this approach is a single neural network policy conditioned on a behavior description that can be precisely modulated. We apply this approach to train a policy on 7,777 human replays to perform build-order planning in StarCraft II. Principal Component Analysis (PCA) is applied to construct a low-dimensional behavioral space from the high-dimensional army unit composition of each demonstration. The results demonstrate that the learned policy can be effectively manipulated to express distinct behaviors. Additionally, by applying the UCB1 algorithm, we are able to adapt the behavior of the policy - in-between games - to reach a performance beyond that of the traditional IL baseline approach.
Illuminating Generalization in Deep Reinforcement Learning through Procedural Level Generation
Sep 07, 2018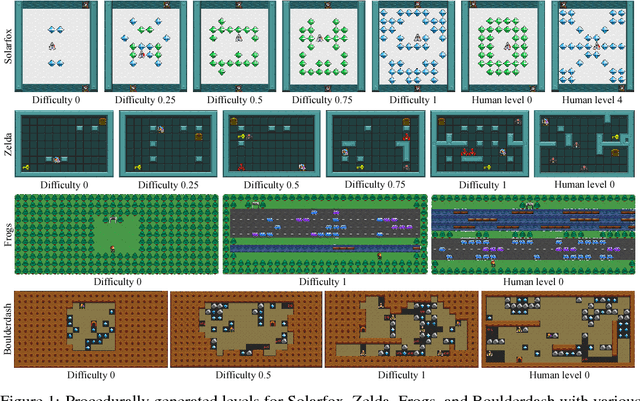
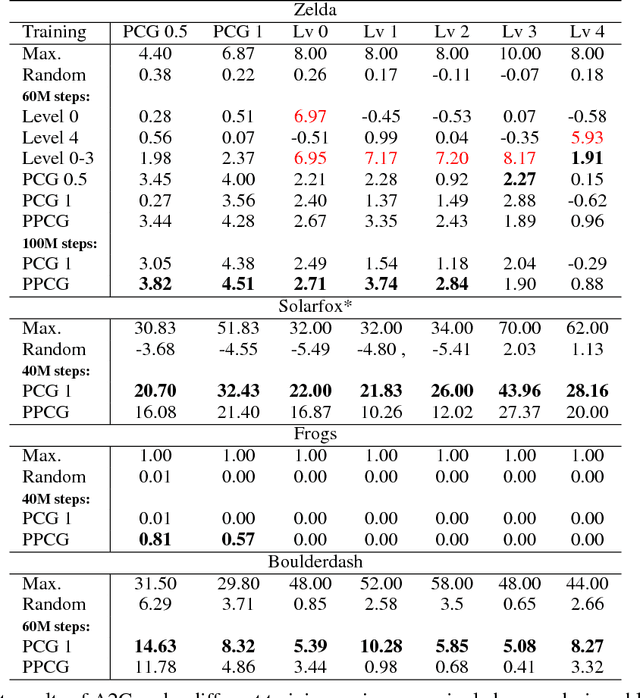
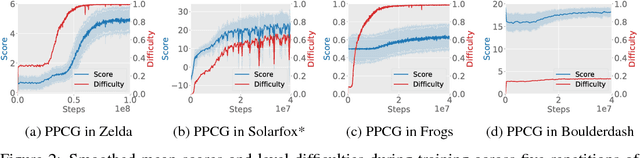
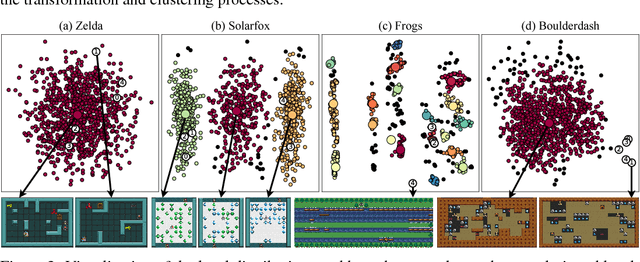
Deep reinforcement learning (RL) has shown impressive results in a variety of domains, learning directly from high-dimensional sensory streams. However, when neural networks are trained in a fixed environment, such as a single level in a video game, they will usually overfit and fail to generalize to new levels. When RL models overfit, even slight modifications to the environment can result in poor agent performance. In this paper, we explore how procedurally generated levels during training increase generality. We show that for some games procedural level generation enables generalization to new levels within the same distribution. Additionally, it is possible to achieve better performance with less data by manipulating the difficulty of the levels in response to the performance of the agent. The generality of the learned behaviors is also evaluated on a set of human-designed levels. Our results show that the ability to generalize to human-designed levels highly depends on the design of the level generators. We apply dimensionality reduction and clustering techniques to visualize the generators' distributions of levels and analyze to what degree they can produce levels similar to those designed by a human.
Automated Curriculum Learning by Rewarding Temporally Rare Events
Jun 08, 2018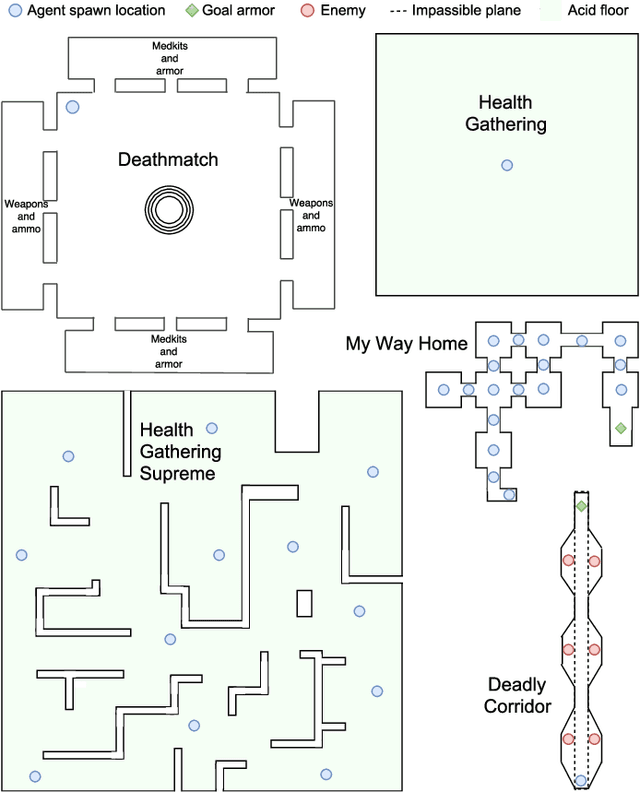
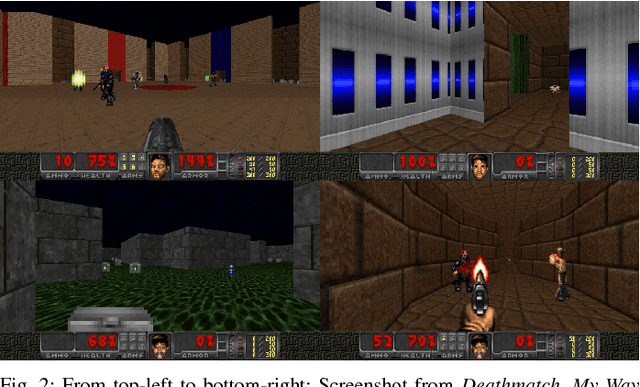
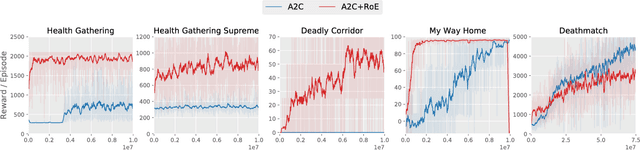
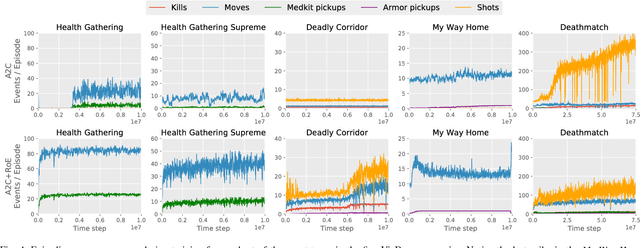
Reward shaping allows reinforcement learning (RL) agents to accelerate learning by receiving additional reward signals. However, these signals can be difficult to design manually, especially for complex RL tasks. We propose a simple and general approach that determines the reward of pre-defined events by their rarity alone. Here events become less rewarding as they are experienced more often, which encourages the agent to continually explore new types of events as it learns. The adaptiveness of this reward function results in a form of automated curriculum learning that does not have to be specified by the experimenter. We demonstrate that this \emph{Rarity of Events} (RoE) approach enables the agent to succeed in challenging VizDoom scenarios without access to the extrinsic reward from the environment. Furthermore, the results demonstrate that RoE learns a more versatile policy that adapts well to critical changes in the environment. Rewarding events based on their rarity could help in many unsolved RL environments that are characterized by sparse extrinsic rewards but a plethora of known event types.
Deep Learning for Video Game Playing
Oct 30, 2017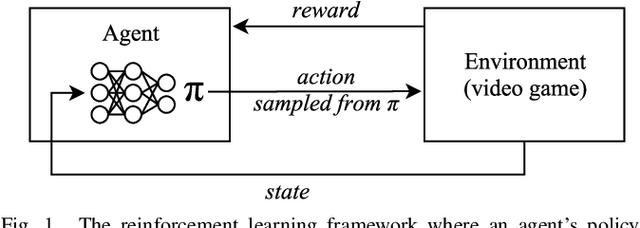


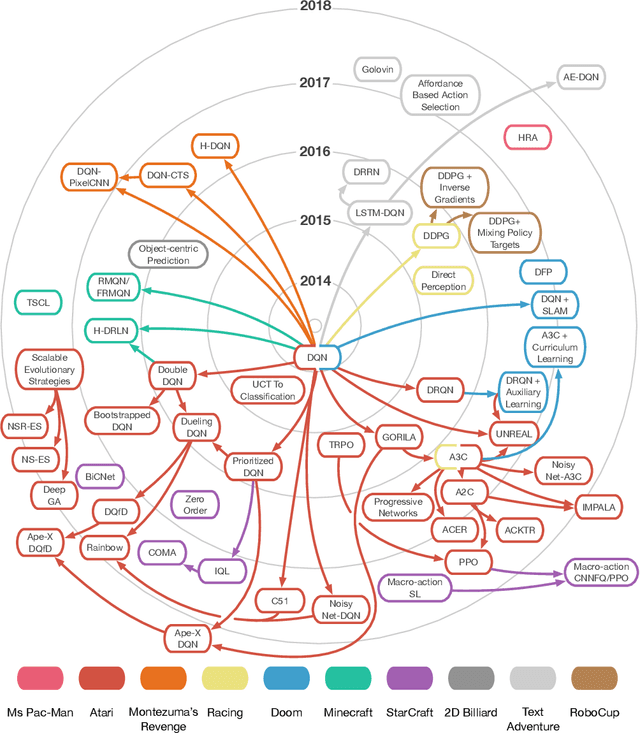
In this article, we review recent Deep Learning advances in the context of how they have been applied to play different types of video games such as first-person shooters, arcade games, and real-time strategy games. We analyze the unique requirements that different game genres pose to a deep learning system and highlight important open challenges in the context of applying these machine learning methods to video games, such as general game playing, dealing with extremely large decision spaces and sparse rewards.
Learning Macromanagement in StarCraft from Replays using Deep Learning
Jul 12, 2017



The real-time strategy game StarCraft has proven to be a challenging environment for artificial intelligence techniques, and as a result, current state-of-the-art solutions consist of numerous hand-crafted modules. In this paper, we show how macromanagement decisions in StarCraft can be learned directly from game replays using deep learning. Neural networks are trained on 789,571 state-action pairs extracted from 2,005 replays of highly skilled players, achieving top-1 and top-3 error rates of 54.6% and 22.9% in predicting the next build action. By integrating the trained network into UAlbertaBot, an open source StarCraft bot, the system can significantly outperform the game's built-in Terran bot, and play competitively against UAlbertaBot with a fixed rush strategy. To our knowledge, this is the first time macromanagement tasks are learned directly from replays in StarCraft. While the best hand-crafted strategies are still the state-of-the-art, the deep network approach is able to express a wide range of different strategies and thus improving the network's performance further with deep reinforcement learning is an immediately promising avenue for future research. Ultimately this approach could lead to strong StarCraft bots that are less reliant on hard-coded strategies.