 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVGAI-LLM: Evaluating Large Language Model Agents with Infinite Games
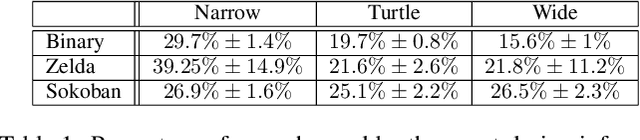
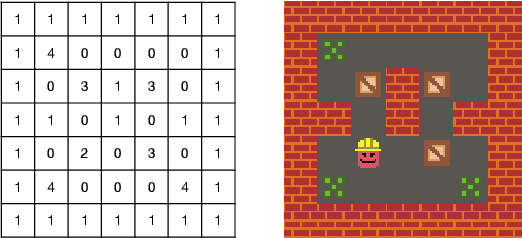
Aug 11, 2025We introduce GVGAI-LLM, a video game benchmark for evaluating the reasoning and problem-solving capabilities of large language models (LLMs). Built on the General Video Game AI framework, it features a diverse collection of arcade-style games designed to test a model's ability to handle tasks that differ from most existing LLM benchmarks. The benchmark leverages a game description language that enables rapid creation of new games and levels, helping to prevent overfitting over time. Each game scene is represented by a compact set of ASCII characters, allowing for efficient processing by language models. GVGAI-LLM defines interpretable metrics, including the meaningful step ratio, step efficiency, and overall score, to assess model behavior. Through zero-shot evaluations across a broad set of games and levels with diverse challenges and skill depth, we reveal persistent limitations of LLMs in spatial reasoning and basic planning. Current models consistently exhibit spatial and logical errors, motivating structured prompting and spatial grounding techniques. While these interventions lead to partial improvements, the benchmark remains very far from solved. GVGAI-LLM provides a reproducible testbed for advancing research on language model capabilities, with a particular emphasis on agentic behavior and contextual reasoning.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Learning Controllable Content Generators
May 06, 2021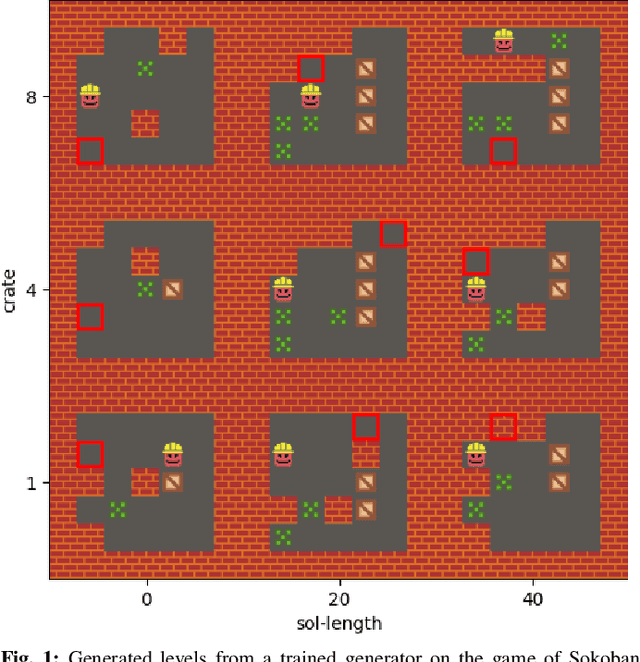

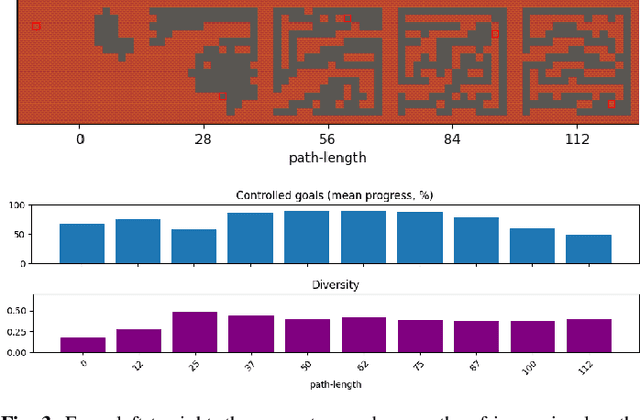
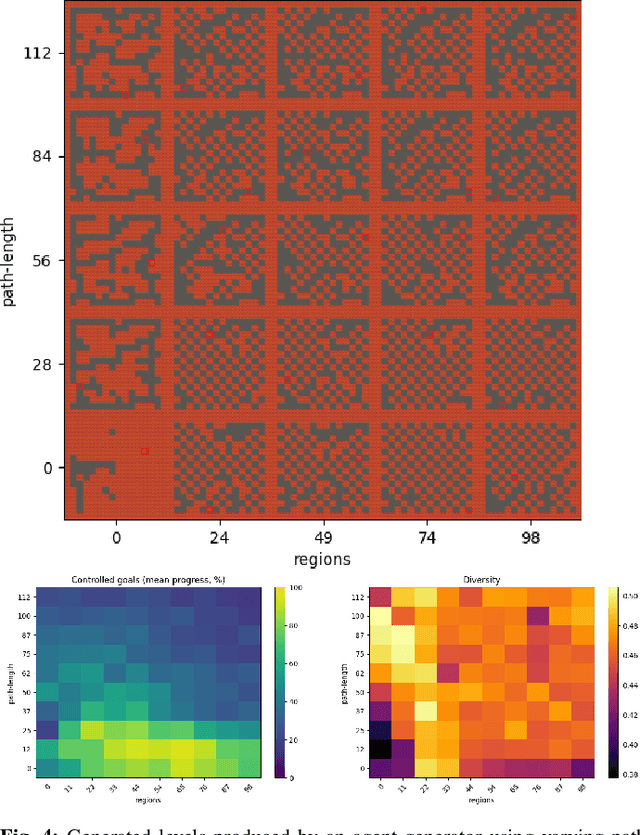
It has recently been shown that reinforcement learning can be used to train generators capable of producing high-quality game levels, with quality defined in terms of some user-specified heuristic. To ensure that these generators' output is sufficiently diverse (that is, not amounting to the reproduction of a single optimal level configuration), the generation process is constrained such that the initial seed results in some variance in the generator's output. However, this results in a loss of control over the generated content for the human user. We propose to train generators capable of producing controllably diverse output, by making them "goal-aware." To this end, we add conditional inputs representing how close a generator is to some heuristic, and also modify the reward mechanism to incorporate that value. Testing on multiple domains, we show that the resulting level generators are capable of exploring the space of possible levels in a targeted, controllable manner, producing levels of comparable quality as their goal-unaware counterparts, that are diverse along designer-specified dimensions.
Game Mechanic Alignment Theory and Discovery
Feb 20, 2021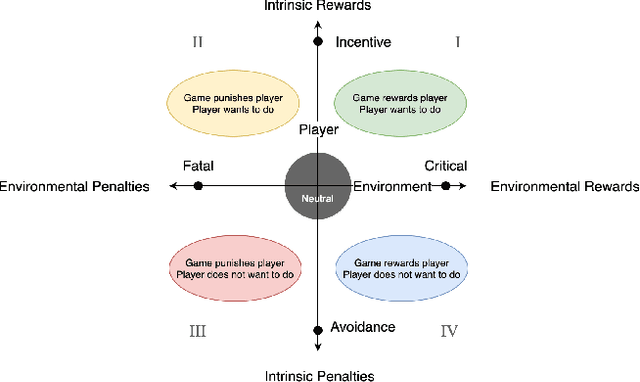
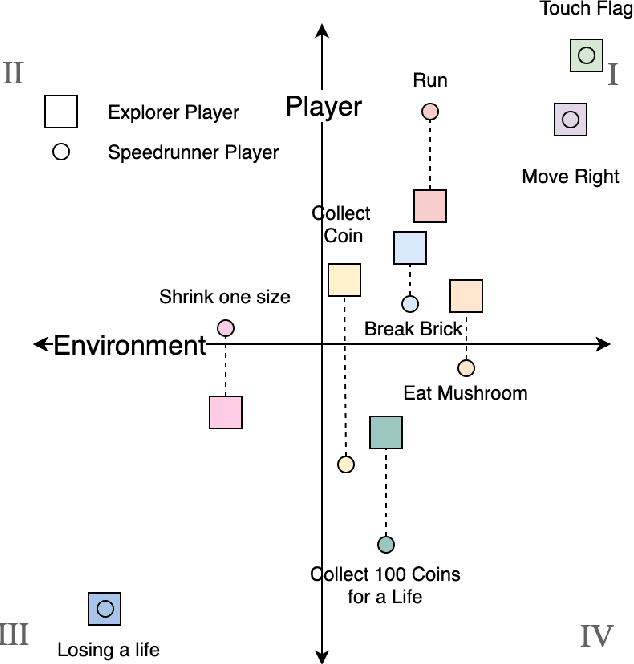
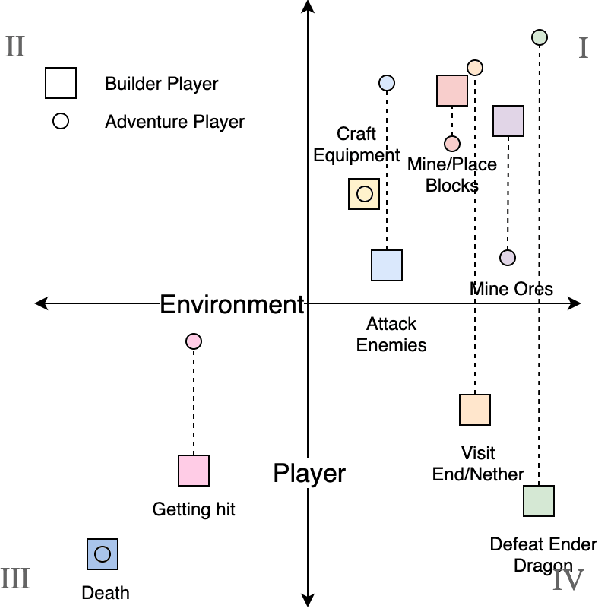
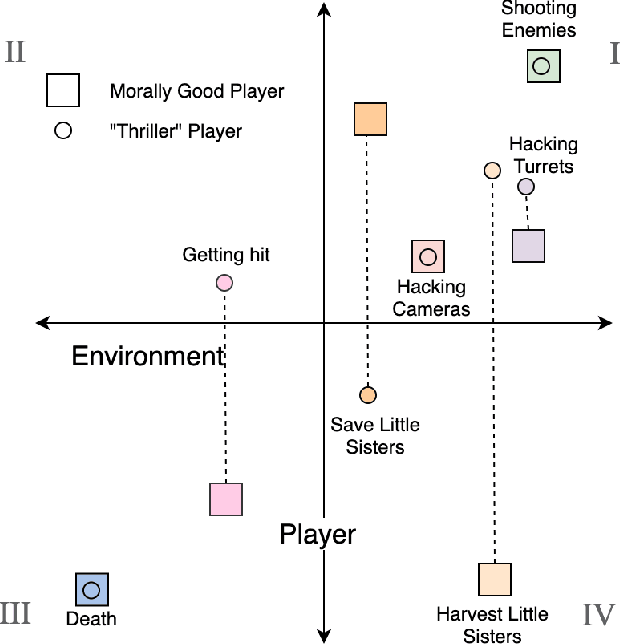
We present a new concept called Game Mechanic Alignment theory as a way to organize game mechanics through the lens of environmental rewards and intrinsic player motivations. By disentangling player and environmental influences, mechanics may be better identified for use in an automated tutorial generation system, which could tailor tutorials for a particular playstyle or player. Within, we apply this theory to several well-known games to demonstrate how designers can benefit from it, we describe a methodology for how to estimate mechanic alignment, and we apply this methodology on multiple games in the GVGAI framework. We discuss how effectively this estimation captures intrinsic/extrinsic rewards and how our theory could be used as an alternative to critical mechanic discovery methods for tutorial generation.
PCGRL: Procedural Content Generation via Reinforcement Learning
Feb 18, 2020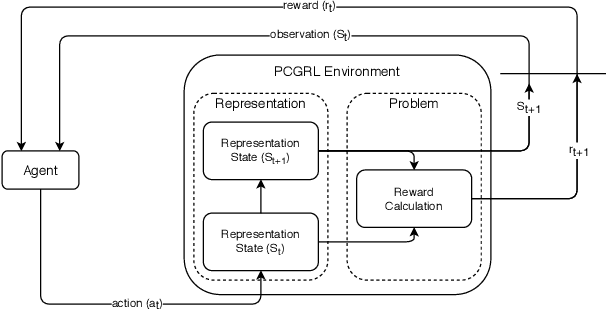

We investigate how reinforcement learning can be used to train level-designing agents. This represents a new approach to procedural content generation in games, where level design is framed as a game, and the content generator itself is learned. By seeing the design problem as a sequential task, we can use reinforcement learning to learn how to take the next action so that the expected final level quality is maximized. This approach can be used when few or no examples exist to train from, and the trained generator is very fast. We investigate three different ways of transforming two-dimensional level design problems into Markov decision processes and apply these to three game environments.
Fully Differentiable Procedural Content Generation through Generative Playing Networks
Feb 12, 2020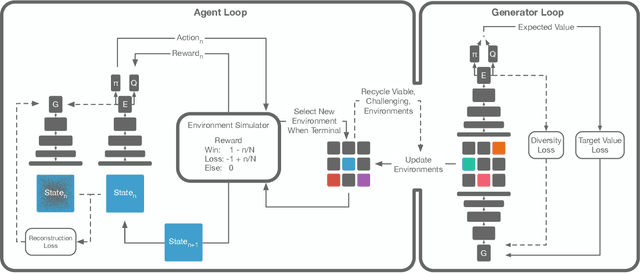



To procedurally create interactive content such as environments or game levels, we need agents that can evaluate the content; but to train such agents, we need content they can train on. Generative Playing Networks is a framework that learns agent policies and generates environments in tandem through a symbiotic process. Policies are learned using an actor-critic reinforcement learning algorithm so as to master the environment, and environments are created by a generator network which tries to provide an appropriate level of challenge for the agent. This is accomplished by the generator learning to make content based on estimates by the critic. Thus, this process provides an implicit curriculum for the agent, creating more complex environments over time. Unlike previous approaches to procedural content generation, Generative Playing Networks is end-to-end differentiable and does not require human-designed examples or domain knowledge. We demonstrate the capability of this framework by training an agent and level generator for a 2D dungeon crawler game.
Rotation, Translation, and Cropping for Zero-Shot Generalization
Jan 27, 2020
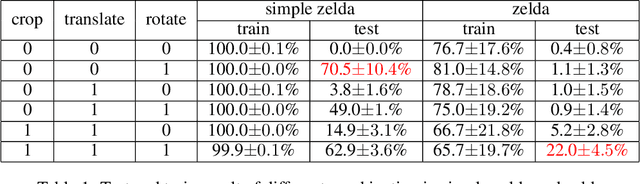


Deep Reinforcement Learning (DRL) has shown impressive performance on domains with visual inputs, in particular various games. However, the agent is usually trained on a fixed environment, e.g. a fixed number of levels. A growing mass of evidence suggests that these trained models fail to generalize to even slight variations of the environments they were trained on. This paper advances the hypothesis that the lack of generalization is partly due to the input representation, and explores how rotation, cropping and translation could increase generality. We show that a cropped, translated and rotated observation can get better generalization on unseen levels of a two-dimensional arcade game. The generality of the agent is evaluated on a set of human-designed levels.
Superstition in the Network: Deep Reinforcement Learning Plays Deceptive Games
Aug 12, 2019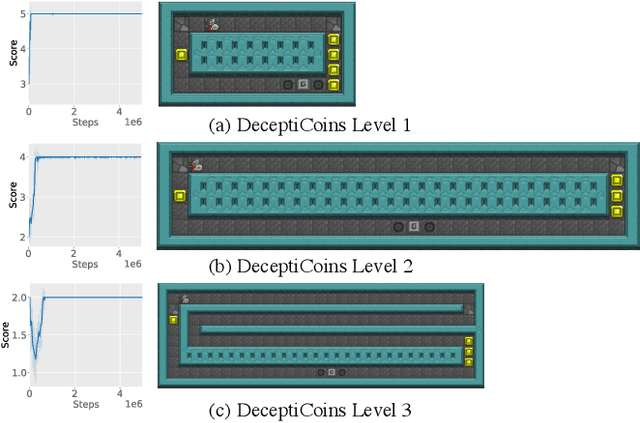
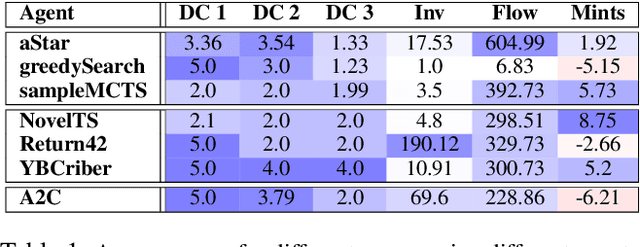
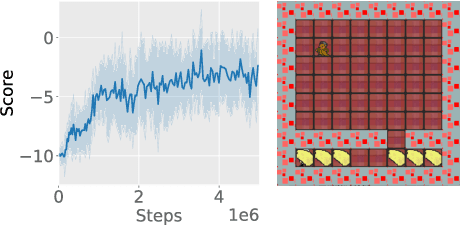
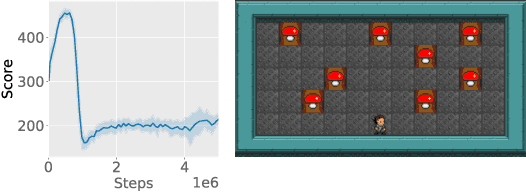
Deep reinforcement learning has learned to play many games well, but failed on others. To better characterize the modes and reasons of failure of deep reinforcement learners, we test the widely used Asynchronous Actor-Critic (A2C) algorithm on four deceptive games, which are specially designed to provide challenges to game-playing agents. These games are implemented in the General Video Game AI framework, which allows us to compare the behavior of reinforcement learning-based agents with planning agents based on tree search. We find that several of these games reliably deceive deep reinforcement learners, and that the resulting behavior highlights the shortcomings of the learning algorithm. The particular ways in which agents fail differ from how planning-based agents fail, further illuminating the character of these algorithms. We propose an initial typology of deceptions which could help us better understand pitfalls and failure modes of (deep) reinforcement learning.
DeepMasterPrints: Generating MasterPrints for Dictionary Attacks via Latent Variable Evolution
Oct 18, 2018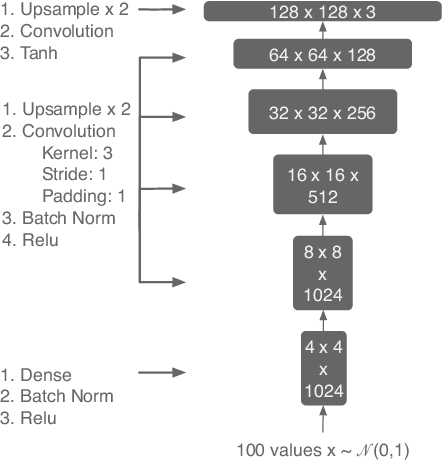

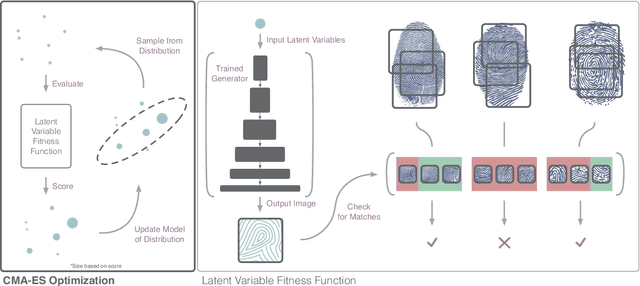
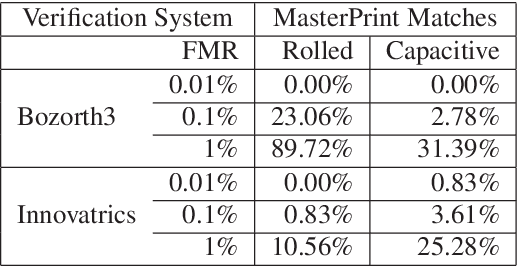
Recent research has demonstrated the vulnerability of fingerprint recognition systems to dictionary attacks based on MasterPrints. MasterPrints are real or synthetic fingerprints that can fortuitously match with a large number of fingerprints thereby undermining the security afforded by fingerprint systems. Previous work by Roy et al. generated synthetic MasterPrints at the feature-level. In this work we generate complete image-level MasterPrints known as DeepMasterPrints, whose attack accuracy is found to be much superior than that of previous methods. The proposed method, referred to as Latent Variable Evolution, is based on training a Generative Adversarial Network on a set of real fingerprint images. Stochastic search in the form of the Covariance Matrix Adaptation Evolution Strategy is then used to search for latent input variables to the generator network that can maximize the number of impostor matches as assessed by a fingerprint recognizer. Experiments convey the efficacy of the proposed method in generating DeepMasterPrints. The underlying method is likely to have broad applications in fingerprint security as well as fingerprint synthesis.
Illuminating Generalization in Deep Reinforcement Learning through Procedural Level Generation
Sep 07, 2018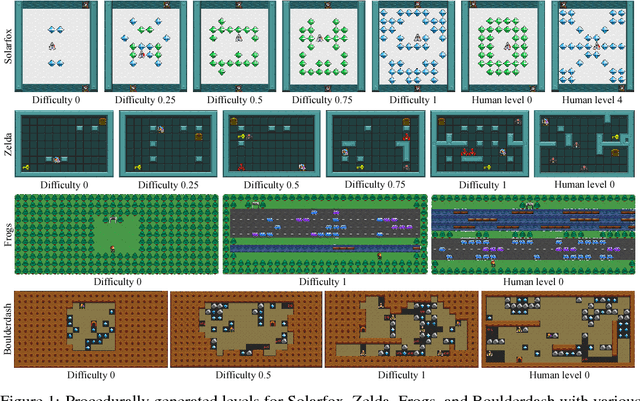
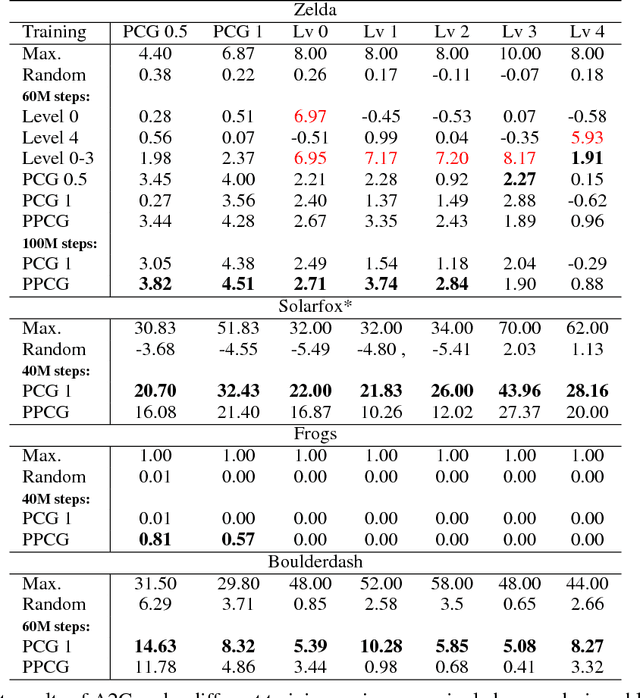
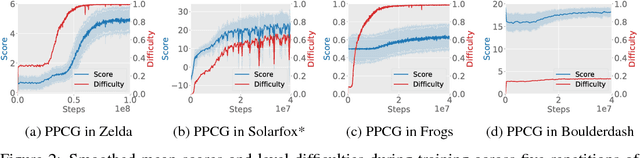
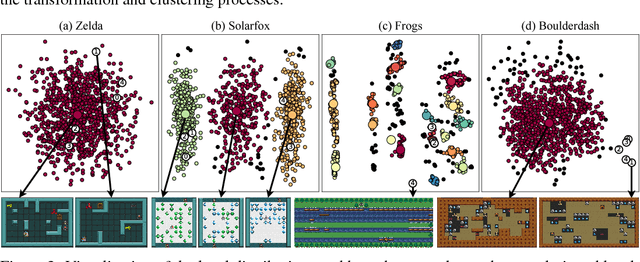
Deep reinforcement learning (RL) has shown impressive results in a variety of domains, learning directly from high-dimensional sensory streams. However, when neural networks are trained in a fixed environment, such as a single level in a video game, they will usually overfit and fail to generalize to new levels. When RL models overfit, even slight modifications to the environment can result in poor agent performance. In this paper, we explore how procedurally generated levels during training increase generality. We show that for some games procedural level generation enables generalization to new levels within the same distribution. Additionally, it is possible to achieve better performance with less data by manipulating the difficulty of the levels in response to the performance of the agent. The generality of the learned behaviors is also evaluated on a set of human-designed levels. Our results show that the ability to generalize to human-designed levels highly depends on the design of the level generators. We apply dimensionality reduction and clustering techniques to visualize the generators' distributions of levels and analyze to what degree they can produce levels similar to those designed by a human.