 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Constraints for Reinforcement-Learned Content Generators
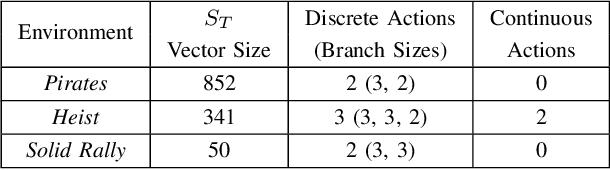
May 13, 2026Constraint-based game content generators that learn local constraints from existing content, such as Wave Function Collapse (WFC), can generate visually satisfying game levels but face challenges in guaranteeing global properties, such as playability. On the other hand, reinforcement-learning trained generators can guarantee global properties -- because such properties can easily be included in reward functions -- but the results can be visually dissatisfying. In this paper, we explore ways to combine these methods. Specifically, we constrain the action space of a PCGRL generator with constraints learned by WFC, effectively allowing the PCGRL generator to achieve global properties while forced to adhere to local constraints. To better analyze how this hybrid content generation method operates, we vary the number and type of inputs, and we test whether to randomly collapse the starting state and exclude rare patterns. While the method is sensitive to hyperparameter tuning, the best of our trained generators produce visually satisfying and playable puzzle-platform game levels -- such as Lode Runner levels -- with desired global properties.
Continuous Program Search
Feb 07, 2026Genetic Programming yields interpretable programs, but small syntactic mutations can induce large, unpredictable behavioral shifts, degrading locality and sample efficiency. We frame this as an operator-design problem: learn a continuous program space where latent distance has behavioral meaning, then design mutation operators that exploit this structure without changing the evolutionary optimizer. We make locality measurable by tracking action-level divergence under controlled latent perturbations, identifying an empirical trust region for behavior-local continuous variation. Using a compact trading-strategy DSL with four semantic components (long/short entry and exit), we learn a matching block-factorized embedding and compare isotropic Gaussian mutation over the full latent space to geometry-compiled mutation that restricts updates to semantically paired entry--exit subspaces and proposes directions using a learned flow-based model trained on logged mutation outcomes. Under identical $(μ+λ)$ evolution strategies and fixed evaluation budgets across five assets, the learned mutation operator discovers strong strategies using an order of magnitude fewer evaluations and achieves the highest median out-of-sample Sharpe ratio. Although isotropic mutation occasionally attains higher peak performance, geometry-compiled mutation yields faster, more reliable progress, demonstrating that semantically aligned mutation can substantially improve search efficiency without modifying the underlying evolutionary algorithm.
Evolutionary Level Repair
Jun 24, 2025We address the problem of game level repair, which consists of taking a designed but non-functional game level and making it functional. This might consist of ensuring the completeness of the level, reachability of objects, or other performance characteristics. The repair problem may also be constrained in that it can only make a small number of changes to the level. We investigate search-based solutions to the level repair problem, particularly using evolutionary and quality-diversity algorithms, with good results. This level repair method is applied to levels generated using a machine learning-based procedural content generation (PCGML) method that generates stylistically appropriate but frequently broken levels. This combination of PCGML for generation and search-based methods for repair shows great promise as a hybrid procedural content generation (PCG) method.
ScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search
Jun 06, 2025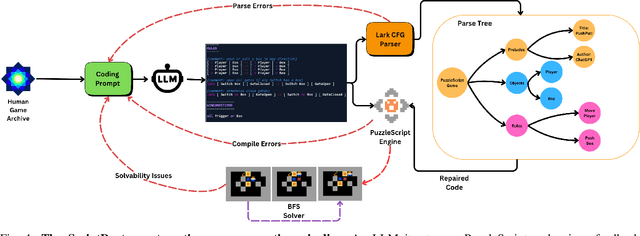


There is much interest in using large pre-trained models in Automatic Game Design (AGD), whether via the generation of code, assets, or more abstract conceptualization of design ideas. But so far this interest largely stems from the ad hoc use of such generative models under persistent human supervision. Much work remains to show how these tools can be integrated into longer-time-horizon AGD pipelines, in which systems interface with game engines to test generated content autonomously. To this end, we introduce ScriptDoctor, a Large Language Model (LLM)-driven system for automatically generating and testing games in PuzzleScript, an expressive but highly constrained description language for turn-based puzzle games over 2D gridworlds. ScriptDoctor generates and tests game design ideas in an iterative loop, where human-authored examples are used to ground the system's output, compilation errors from the PuzzleScript engine are used to elicit functional code, and search-based agents play-test generated games. ScriptDoctor serves as a concrete example of the potential of automated, open-ended LLM-based workflows in generating novel game content.
The Procedural Content Generation Benchmark: An Open-source Testbed for Generative Challenges in Games
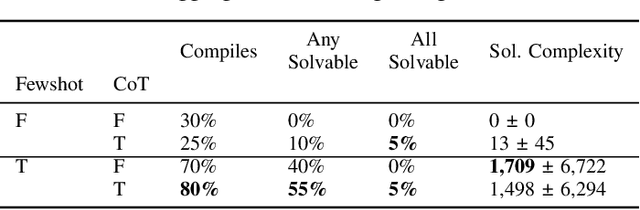
Mar 27, 2025


This paper introduces the Procedural Content Generation Benchmark for evaluating generative algorithms on different game content creation tasks. The benchmark comes with 12 game-related problems with multiple variants on each problem. Problems vary from creating levels of different kinds to creating rule sets for simple arcade games. Each problem has its own content representation, control parameters, and evaluation metrics for quality, diversity, and controllability. This benchmark is intended as a first step towards a standardized way of comparing generative algorithms. We use the benchmark to score three baseline algorithms: a random generator, an evolution strategy, and a genetic algorithm. Results show that some problems are easier to solve than others, as well as the impact the chosen objective has on quality, diversity, and controllability of the generated artifacts.
Affectively Framework: Towards Human-like Affect-Based Agents
Jul 25, 2024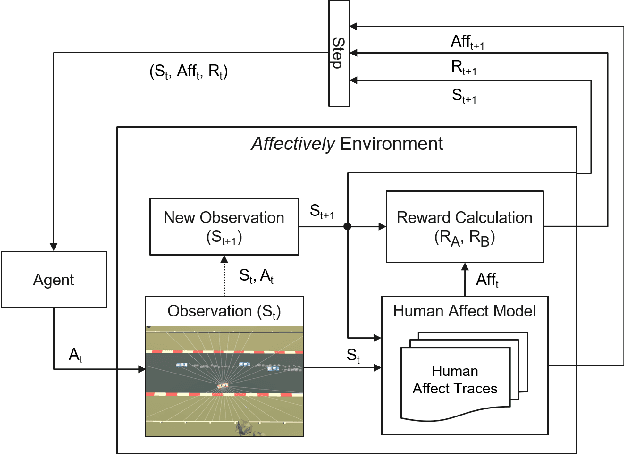


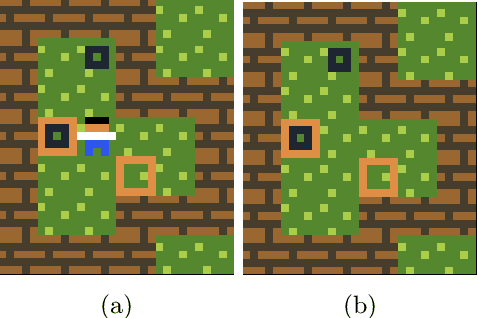
Game environments offer a unique opportunity for training virtual agents due to their interactive nature, which provides diverse play traces and affect labels. Despite their potential, no reinforcement learning framework incorporates human affect models as part of their observation space or reward mechanism. To address this, we present the \emph{Affectively Framework}, a set of Open-AI Gym environments that integrate affect as part of the observation space. This paper introduces the framework and its three game environments and provides baseline experiments to validate its effectiveness and potential.
Evolutionary Machine Learning and Games
Nov 20, 2023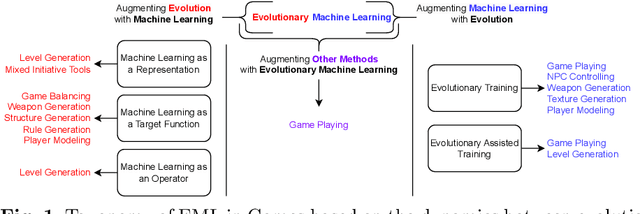
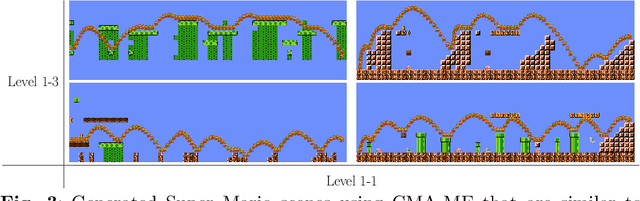

Evolutionary machine learning (EML) has been applied to games in multiple ways, and for multiple different purposes. Importantly, AI research in games is not only about playing games; it is also about generating game content, modeling players, and many other applications. Many of these applications pose interesting problems for EML. We will structure this chapter on EML for games based on whether evolution is used to augment machine learning (ML) or ML is used to augment evolution. For completeness, we also briefly discuss the usage of ML and evolution separately in games.
A Preliminary Study on a Conceptual Game Feature Generation and Recommendation System
Aug 16, 2023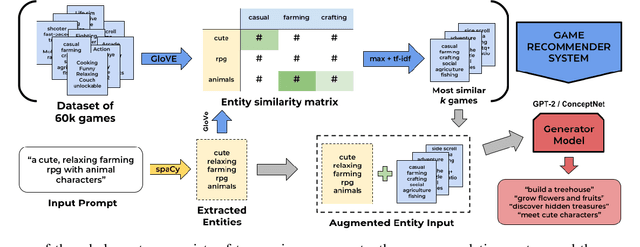
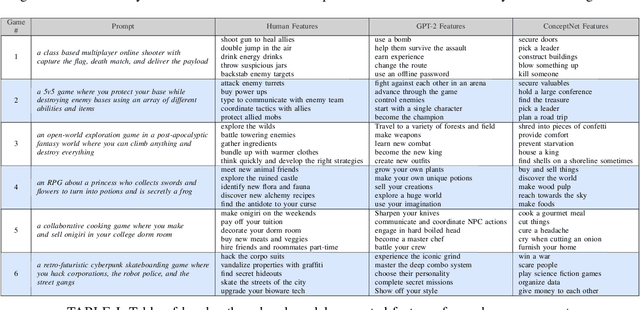
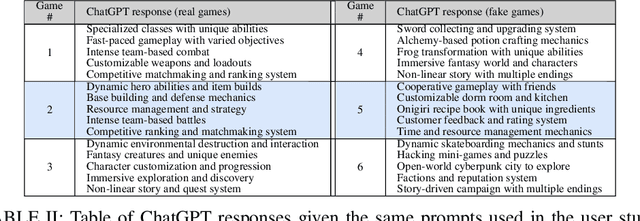
This paper introduces a system used to generate game feature suggestions based on a text prompt. Trained on the game descriptions of almost 60k games, it uses the word embeddings of a small GLoVe model to extract features and entities found in thematically similar games which are then passed through a generator model to generate new features for a user's prompt. We perform a short user study comparing the features generated from a fine-tuned GPT-2 model, a model using the ConceptNet, and human-authored game features. Although human suggestions won the overall majority of votes, the GPT-2 model outperformed the human suggestions in certain games. This system is part of a larger game design assistant tool that is able to collaborate with users at a conceptual level.
Lode Enhancer: Level Co-creation Through Scaling
Aug 03, 2023We explore AI-powered upscaling as a design assistance tool in the context of creating 2D game levels. Deep neural networks are used to upscale artificially downscaled patches of levels from the puzzle platformer game Lode Runner. The trained networks are incorporated into a web-based editor, where the user can create and edit levels at three different levels of resolution: 4x4, 8x8, and 16x16. An edit at any resolution instantly transfers to the other resolutions. As upscaling requires inventing features that might not be present at lower resolutions, we train neural networks to reproduce these features. We introduce a neural network architecture that is capable of not only learning upscaling but also giving higher priority to less frequent tiles. To investigate the potential of this tool and guide further development, we conduct a qualitative study with 3 designers to understand how they use it. Designers enjoyed co-designing with the tool, liked its underlying concept, and provided feedback for further improvement.
Lode Encoder: AI-constrained co-creativity
Aug 02, 2023
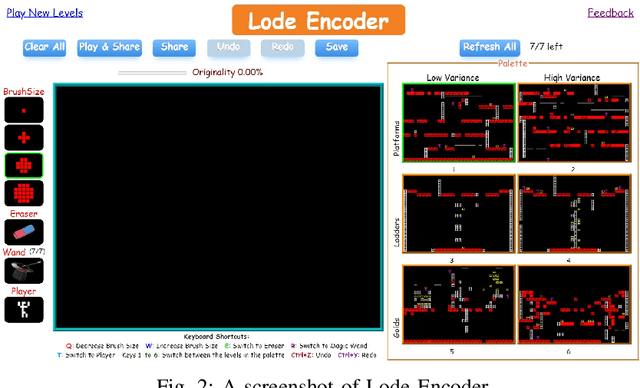
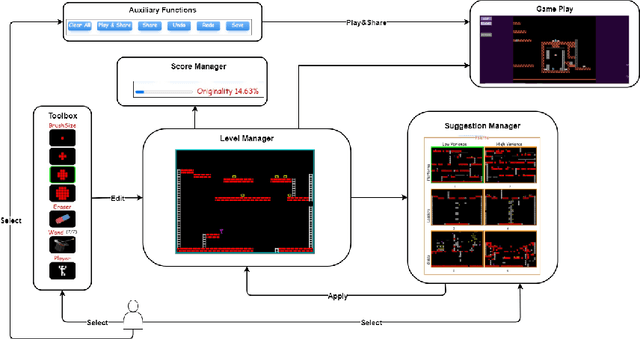
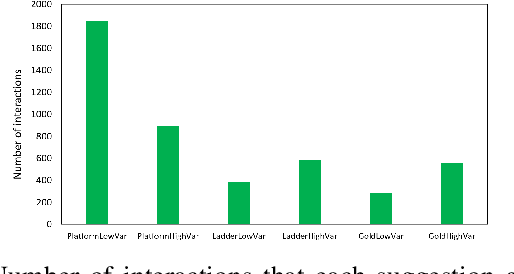
We present Lode Encoder, a gamified mixed-initiative level creation system for the classic platform-puzzle game Lode Runner. The system is built around several autoencoders which are trained on sets of Lode Runner levels. When fed with the user's design, each autoencoder produces a version of that design which is closer in style to the levels that it was trained on. The Lode Encoder interface allows the user to build and edit levels through 'painting' from the suggestions provided by the autoencoders. Crucially, in order to encourage designers to explore new possibilities, the system does not include more traditional editing tools. We report on the system design and training procedure, as well as on the evolution of the system itself and user tests.