 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preliminary Study on a Conceptual Game Feature Generation and Recommendation System
Aug 16, 2023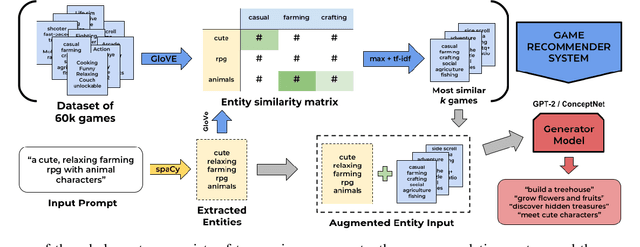
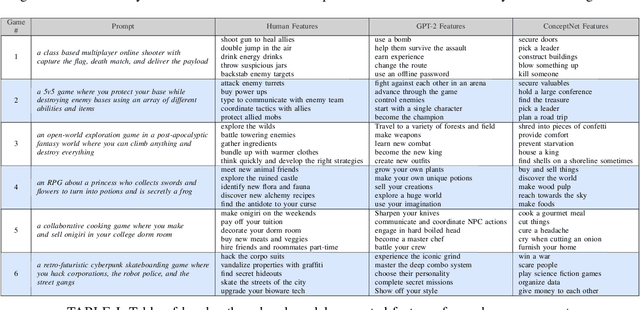
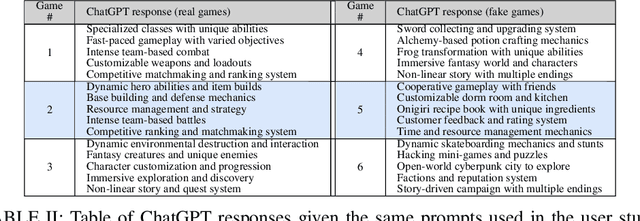
This paper introduces a system used to generate game feature suggestions based on a text prompt. Trained on the game descriptions of almost 60k games, it uses the word embeddings of a small GLoVe model to extract features and entities found in thematically similar games which are then passed through a generator model to generate new features for a user's prompt. We perform a short user study comparing the features generated from a fine-tuned GPT-2 model, a model using the ConceptNet, and human-authored game features. Although human suggestions won the overall majority of votes, the GPT-2 model outperformed the human suggestions in certain games. This system is part of a larger game design assistant tool that is able to collaborate with users at a conceptual level.
LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmentation, Linguistic Features and Voting
Feb 24, 2021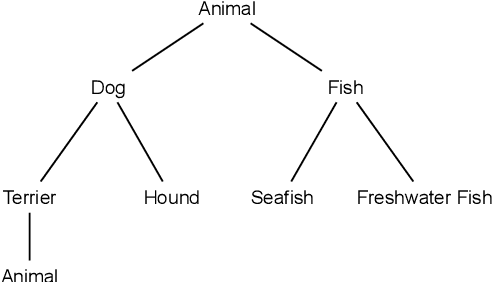
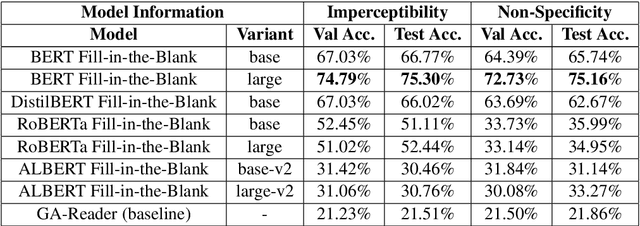
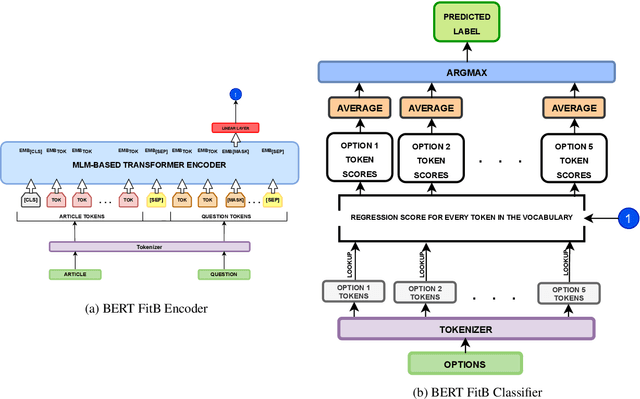
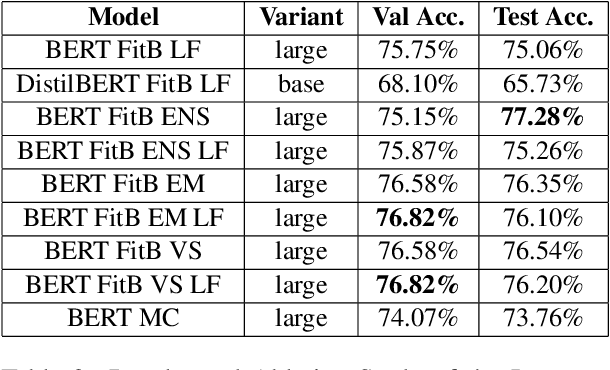
In this article, we present our methodologies for SemEval-2021 Task-4: Reading Comprehension of Abstract Meaning. Given a fill-in-the-blank-type question and a corresponding context, the task is to predict the most suitable word from a list of 5 options. There are three sub-tasks within this task: Imperceptibility (subtask-I), Non-Specificity (subtask-II), and Intersection (subtask-III). We use encoders of transformers-based models pre-trained on the masked language modelling (MLM) task to build our Fill-in-the-blank (FitB) models. Moreover, to model imperceptibility, we define certain linguistic features, and to model non-specificity, we leverage information from hypernyms and hyponyms provided by a lexical database. Specifically, for non-specificity, we try out augmentation techniques, and other statistical techniques. We also propose variants, namely Chunk Voting and Max Context, to take care of input length restrictions for BERT, etc. Additionally, we perform a thorough ablation study, and use Integrated Gradients to explain our predictions on a few samples. Our best submissions achieve accuracies of 75.31% and 77.84%, on the test sets for subtask-I and subtask-II, respectively. For subtask-III, we achieve accuracies of 65.64% and 62.27%.
NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Feb 24, 2021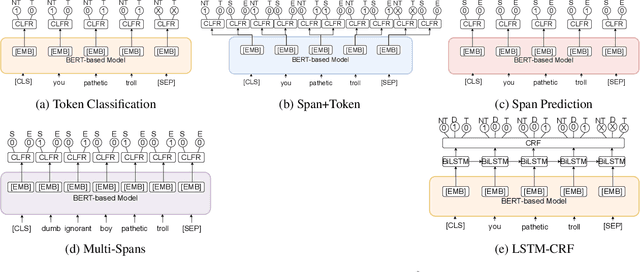
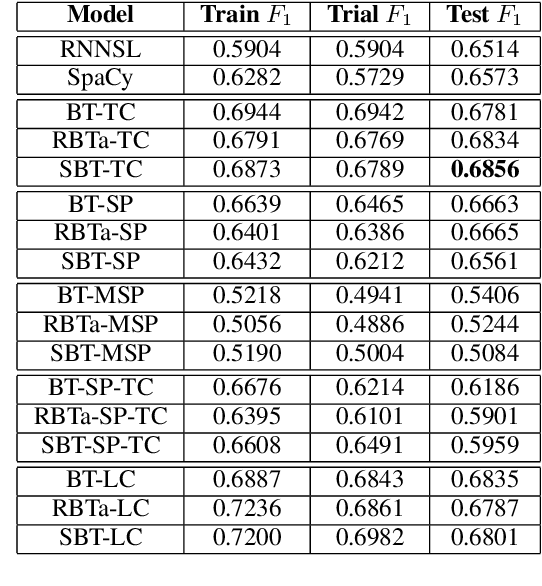


Toxicity detection of text has been a popular NLP task in the recent years. In SemEval-2021 Task-5 Toxic Spans Detection, the focus is on detecting toxic spans within passages. Most state-of-the-art span detection approaches employ various techniques, each of which can be broadly classified into Token Classification or Span Prediction approaches. In our paper, we explore simple versions of both of these approaches and their performance on the task. Specifically, we use BERT-based models -- BERT, RoBERTa, and SpanBERT for both approaches. We also combine these approaches and modify them to bring improvements for Toxic Spans prediction. To this end, we investigate results on four hybrid approaches -- Multi-Span, Span+Token, LSTM-CRF, and a combination of predicted offsets using union/intersection. Additionally, we perform a thorough ablative analysis and analyze our observed results. Our best submission -- a combination of SpanBERT Span Predictor and RoBERTa Token Classifier predictions -- achieves an F1 score of 0.6753 on the test set. Our best post-eval F1 score is 0.6895 on intersection of predicted offsets from top-3 RoBERTa Token Classification checkpoints. These approaches improve the performance by 3% on average than those of the shared baseline models -- RNNSL and SpaCy NER.