 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of AI Data Transparency Policy: Three Disclosure Fallacies
Jan 26, 2026Data transparency has emerged as a rallying cry for addressing concerns about AI: data quality, privacy, and copyright chief among them. Yet while these calls are crucial for accountability, current transparency policies often fall short of their intended aims. Similar to nutrition facts for food, policies aimed at nutrition facts for AI currently suffer from a limited consideration of research on effective disclosures. We offer an institutional perspective and identify three common fallacies in policy implementations of data disclosures for AI. First, many data transparency proposals exhibit a specification gap between the stated goals of data transparency and the actual disclosures necessary to achieve such goals. Second, reform attempts exhibit an enforcement gap between required disclosures on paper and enforcement to ensure compliance in fact. Third, policy proposals manifest an impact gap between disclosed information and meaningful changes in developer practices and public understanding. Informed by the social science on transparency, our analysis identifies affirmative paths for transparency that are effective rather than merely symbolic.
RAGRank: Using PageRank to Counter Poisoning in CTI LLM Pipelines
Oct 23, 2025



Retrieval-Augmented Generation (RAG) has emerged as the dominant architectural pattern to operationalize Large Language Model (LLM) usage in Cyber Threat Intelligence (CTI) systems. However, this design is susceptible to poisoning attacks, and previously proposed defenses can fail for CTI contexts as cyber threat information is often completely new for emerging attacks, and sophisticated threat actors can mimic legitimate formats, terminology, and stylistic conventions. To address this issue, we propose that the robustness of modern RAG defenses can be accelerated by applying source credibility algorithms on corpora, using PageRank as an example. In our experiments, we demonstrate quantitatively that our algorithm applies a lower authority score to malicious documents while promoting trusted content, using the standardized MS MARCO dataset. We also demonstrate proof-of-concept performance of our algorithm on CTI documents and feeds.
An MPC framework for efficient navigation of mobile robots in cluttered environments
Sep 19, 2025We present a model predictive control (MPC) framework for efficient navigation of mobile robots in cluttered environments. The proposed approach integrates a finite-segment shortest path planner into the finite-horizon trajectory optimization of the MPC. This formulation ensures convergence to dynamically selected targets and guarantees collision avoidance, even under general nonlinear dynamics and cluttered environments. The approach is validated through hardware experiments on a small ground robot, where a human operator dynamically assigns target locations. The robot successfully navigated through complex environments and reached new targets within 2-3 seconds.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
CovarNav: Machine Unlearning via Model Inversion and Covariance Navigation
Nov 21, 2023



The rapid progress of AI, combined with its unprecedented public adoption and the propensity of large neural networks to memorize training data, has given rise to significant data privacy concerns. To address these concerns, machine unlearning has emerged as an essential technique to selectively remove the influence of specific training data points on trained models. In this paper, we approach the machine unlearning problem through the lens of continual learning. Given a trained model and a subset of training data designated to be forgotten (i.e., the "forget set"), we introduce a three-step process, named CovarNav, to facilitate this forgetting. Firstly, we derive a proxy for the model's training data using a model inversion attack. Secondly, we mislabel the forget set by selecting the most probable class that deviates from the actual ground truth. Lastly, we deploy a gradient projection method to minimize the cross-entropy loss on the modified forget set (i.e., learn incorrect labels for this set) while preventing forgetting of the inverted samples. We rigorously evaluate CovarNav on the CIFAR-10 and Vggface2 datasets, comparing our results with recent benchmarks in the field and demonstrating the efficacy of our proposed approach.
The Foundation Model Transparency Index
Oct 19, 2023Foundation models have rapidly permeated society, catalyzing a wave of generative AI applications spanning enterprise and consumer-facing contexts. While the societal impact of foundation models is growing, transparency is on the decline, mirroring the opacity that has plagued past digital technologies (e.g. social media). Reversing this trend is essential: transparency is a vital precondition for public accountability, scientific innovation, and effective governance. To assess the transparency of the foundation model ecosystem and help improve transparency over time, we introduce the Foundation Model Transparency Index. The Foundation Model Transparency Index specifies 100 fine-grained indicators that comprehensively codify transparency for foundation models, spanning the upstream resources used to build a foundation model (e.g data, labor, compute), details about the model itself (e.g. size, capabilities, risks), and the downstream use (e.g. distribution channels, usage policies, affected geographies). We score 10 major foundation model developers (e.g. OpenAI, Google, Meta) against the 100 indicators to assess their transparency. To facilitate and standardize assessment, we score developers in relation to their practices for their flagship foundation model (e.g. GPT-4 for OpenAI, PaLM 2 for Google, Llama 2 for Meta). We present 10 top-level findings about the foundation model ecosystem: for example, no developer currently discloses significant information about the downstream impact of its flagship model, such as the number of users, affected market sectors, or how users can seek redress for harm. Overall, the Foundation Model Transparency Index establishes the level of transparency today to drive progress on foundation model governance via industry standards and regulatory intervention.
Development of a Neural Network-based Method for Improved Imputation of Missing Values in Time Series Data by Repurposing DataWig
Aug 18, 2023
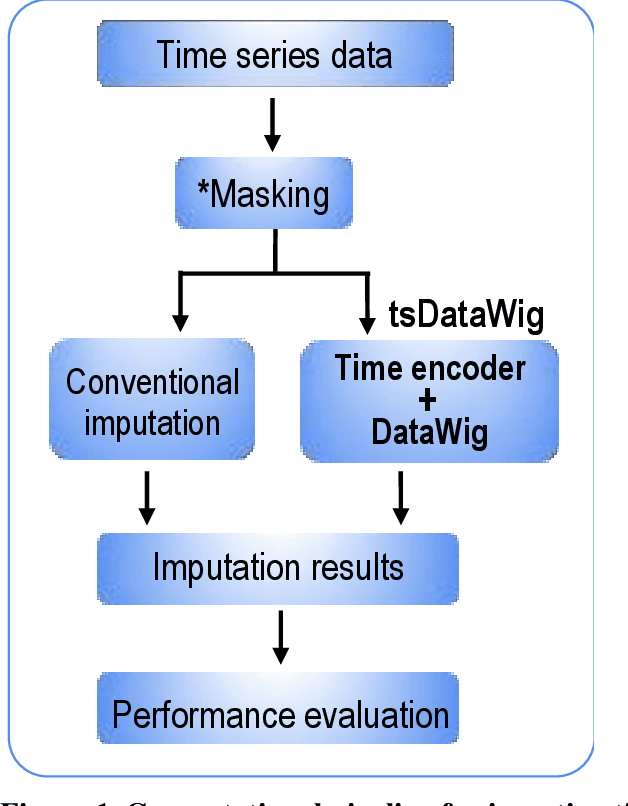


Time series data are observations collected over time intervals. Successful analysis of time series data captures patterns such as trends, cyclicity and irregularity, which are crucial for decision making in research, business, and governance. However, missing values in time series data occur often and present obstacles to successful analysis, thus they need to be filled with alternative values, a process called imputation. Although various approaches have been attempted for robust imputation of time series data, even the most advanced methods still face challenges including limited scalability, poor capacity to handle heterogeneous data types and inflexibility due to requiring strong assumptions of data missing mechanisms. Moreover, the imputation accuracy of these methods still has room for improvement. In this study, I developed tsDataWig (time-series DataWig) by modifying DataWig, a neural network-based method that possesses the capacity to process large datasets and heterogeneous data types but was designed for non-time series data imputation. Unlike the original DataWig, tsDataWig can directly handle values of time variables and impute missing values in complex time series datasets. Using one simulated and three different complex real-world time series datasets, I demonstrated that tsDataWig outperforms the original DataWig and the current state-of-the-art methods for time series data imputation and potentially has broad application due to not requiring strong assumptions of data missing mechanisms. This study provides a valuable solution for robustly imputing missing values in challenging time series datasets, which often contain millions of samples, high dimensional variables, and heterogeneous data types.
A Preliminary Study on a Conceptual Game Feature Generation and Recommendation System
Aug 16, 2023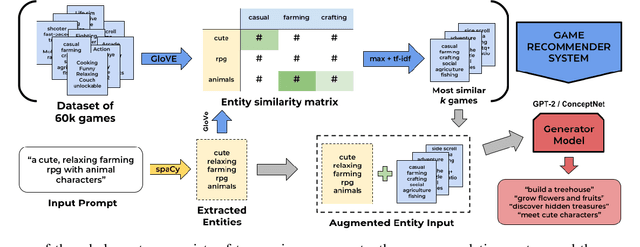
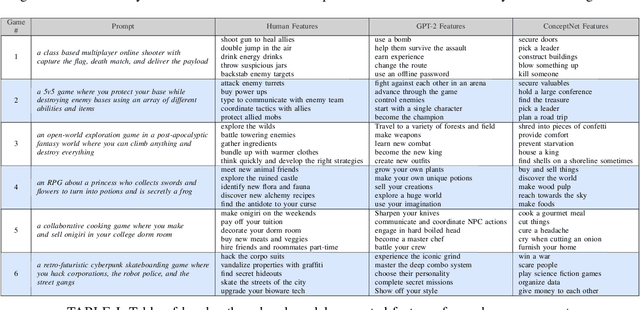
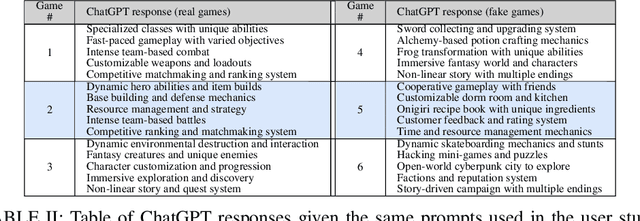
This paper introduces a system used to generate game feature suggestions based on a text prompt. Trained on the game descriptions of almost 60k games, it uses the word embeddings of a small GLoVe model to extract features and entities found in thematically similar games which are then passed through a generator model to generate new features for a user's prompt. We perform a short user study comparing the features generated from a fine-tuned GPT-2 model, a model using the ConceptNet, and human-authored game features. Although human suggestions won the overall majority of votes, the GPT-2 model outperformed the human suggestions in certain games. This system is part of a larger game design assistant tool that is able to collaborate with users at a conceptual level.
Plankton-FL: Exploration of Federated Learning for Privacy-Preserving Training of Deep Neural Networks for Phytoplankton Classification
Dec 18, 2022



Creating high-performance generalizable deep neural networks for phytoplankton monitoring requires utilizing large-scale data coming from diverse global water sources. A major challenge to training such networks lies in data privacy, where data collected at different facilities are often restricted from being transferred to a centralized location. A promising approach to overcome this challenge is federated learning, where training is done at site level on local data, and only the model parameters are exchanged over the network to generate a global model. In this study, we explore the feasibility of leveraging federated learning for privacy-preserving training of deep neural networks for phytoplankton classification. More specifically, we simulate two different federated learning frameworks, federated learning (FL) and mutually exclusive FL (ME-FL), and compare their performance to a traditional centralized learning (CL) framework. Experimental results from this study demonstrate the feasibility and potential of federated learning for phytoplankton monitoring.
Measuring and Clustering Network Attackers using Medium-Interaction Honeypots
Jun 27, 2022
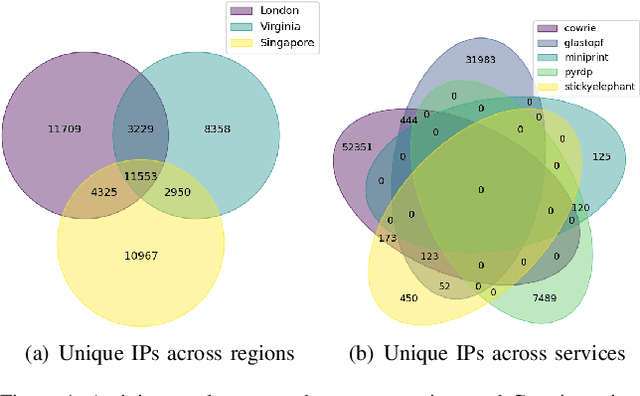
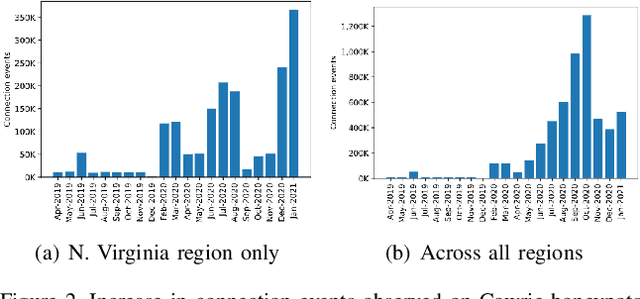
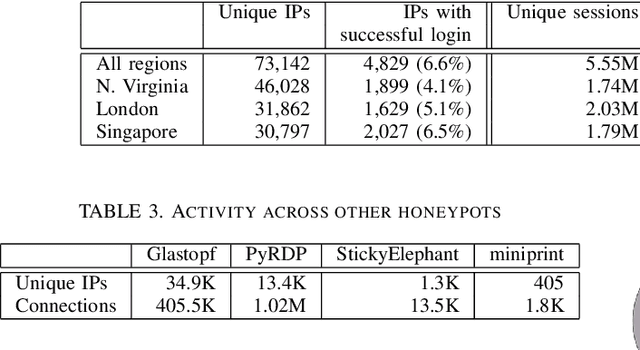
Network honeypots are often used by information security teams to measure the threat landscape in order to secure their networks. With the advancement of honeypot development, today's medium-interaction honeypots provide a way for security teams and researchers to deploy these active defense tools that require little maintenance on a variety of protocols. In this work, we deploy such honeypots on five different protocols on the public Internet and study the intent and sophistication of the attacks we observe. We then use the information gained to develop a clustering approach that identifies correlations in attacker behavior to discover IPs that are highly likely to be controlled by a single operator, illustrating the advantage of using these honeypots for data collection.