Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle Avoidance and Navigation Utilizing Reinforcement Learning with Reward Shaping
Paper and Code
Apr 10, 2020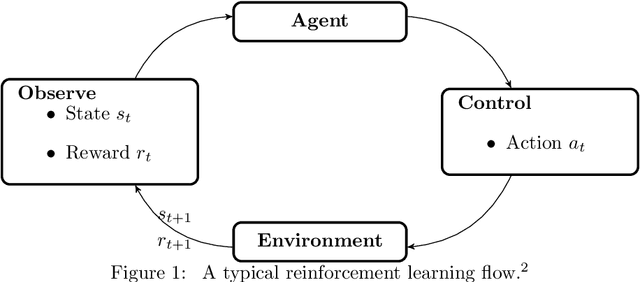



In this paper, we investigate the obstacle avoidance and navigation problem in the robotic control area. For solving such a problem, we propose revised Deep Deterministic Policy Gradient (DDPG) and Proximal Policy Optimization algorithms with an improved reward shaping technique. We compare the performances between the original DDPG and PPO with the revised version of both on simulations with a real mobile robot and demonstrate that the proposed algorithms achieve better results.
View paper on