 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
Towards Fairness in Personalized Ads Using Impression Variance Aware Reinforcement Learning
Jun 08, 2023



Variances in ad impression outcomes across demographic groups are increasingly considered to be potentially indicative of algorithmic bias in personalized ads systems. While there are many definitions of fairness that could be applicable in the context of personalized systems, we present a framework which we call the Variance Reduction System (VRS) for achieving more equitable outcomes in Meta's ads systems. VRS seeks to achieve a distribution of impressions with respect to selected protected class (PC) attributes that more closely aligns the demographics of an ad's eligible audience (a function of advertiser targeting criteria) with the audience who sees that ad, in a privacy-preserving manner. We first define metrics to quantify fairness gaps in terms of ad impression variances with respect to PC attributes including gender and estimated race. We then present the VRS for re-ranking ads in an impression variance-aware manner. We evaluate VRS via extensive simulations over different parameter choices and study the effect of the VRS on the chosen fairness metric. We finally present online A/B testing results from applying VRS to Meta's ads systems, concluding with a discussion of future work. We have deployed the VRS to all users in the US for housing ads, resulting in significant improvement in our fairness metric. VRS is the first large-scale deployed framework for pursuing fairness for multiple PC attributes in online advertising.
Casual Conversations v2: Designing a large consent-driven dataset to measure algorithmic bias and robustness
Nov 10, 2022



Developing robust and fair AI systems require datasets with comprehensive set of labels that can help ensure the validity and legitimacy of relevant measurements. Recent efforts, therefore, focus on collecting person-related datasets that have carefully selected labels, including sensitive characteristics, and consent forms in place to use those attributes for model testing and development. Responsible data collection involves several stages, including but not limited to determining use-case scenarios, selecting categories (annotations) such that the data are fit for the purpose of measuring algorithmic bias for subgroups and most importantly ensure that the selected categories/subcategories are robust to regional diversities and inclusive of as many subgroups as possible. Meta, in a continuation of our efforts to measure AI algorithmic bias and robustness (https://ai.facebook.com/blog/shedding-light-on-fairness-in-ai-with-a-new-data-set), is working on collecting a large consent-driven dataset with a comprehensive list of categories. This paper describes our proposed design of such categories and subcategories for Casual Conversations v2.
Adaptive Sampling Strategies to Construct Equitable Training Datasets
Jan 31, 2022
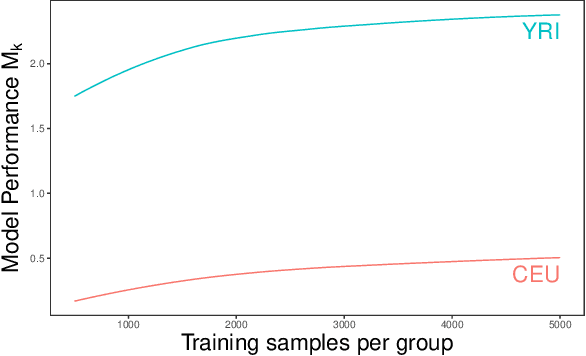
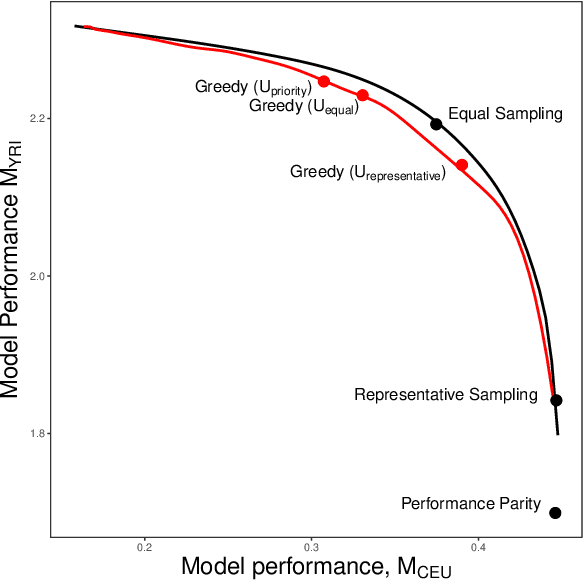
In domains ranging from computer vision to natural language processing, machine learning models have been shown to exhibit stark disparities, often performing worse for members of traditionally underserved groups. One factor contributing to these performance gaps is a lack of representation in the data the models are trained on. It is often unclear, however, how to operationalize representativeness in specific applications. Here we formalize the problem of creating equitable training datasets, and propose a statistical framework for addressing this problem. We consider a setting where a model builder must decide how to allocate a fixed data collection budget to gather training data from different subgroups. We then frame dataset creation as a constrained optimization problem, in which one maximizes a function of group-specific performance metrics based on (estimated) group-specific learning rates and costs per sample. This flexible approach incorporates preferences of model-builders and other stakeholders, as well as the statistical properties of the learning task. When data collection decisions are made sequentially, we show that under certain conditions this optimization problem can be efficiently solved even without prior knowledge of the learning rates. To illustrate our approach, we conduct a simulation study of polygenic risk scores on synthetic genomic data -- an application domain that often suffers from non-representative data collection. We find that our adaptive sampling strategy outperforms several common data collection heuristics, including equal and proportional sampling, demonstrating the value of strategic dataset design for building equitable models.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021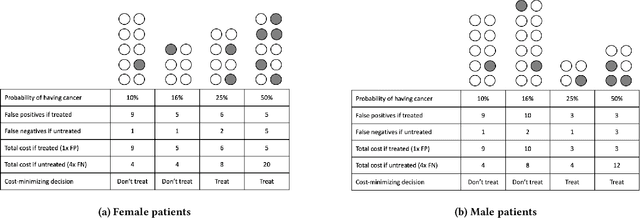
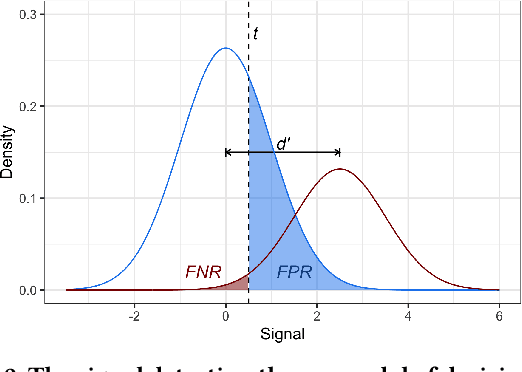
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.