 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasual Conversations v2: Designing a large consent-driven dataset to measure algorithmic bias and robustness
Nov 10, 2022



Developing robust and fair AI systems require datasets with comprehensive set of labels that can help ensure the validity and legitimacy of relevant measurements. Recent efforts, therefore, focus on collecting person-related datasets that have carefully selected labels, including sensitive characteristics, and consent forms in place to use those attributes for model testing and development. Responsible data collection involves several stages, including but not limited to determining use-case scenarios, selecting categories (annotations) such that the data are fit for the purpose of measuring algorithmic bias for subgroups and most importantly ensure that the selected categories/subcategories are robust to regional diversities and inclusive of as many subgroups as possible. Meta, in a continuation of our efforts to measure AI algorithmic bias and robustness (https://ai.facebook.com/blog/shedding-light-on-fairness-in-ai-with-a-new-data-set), is working on collecting a large consent-driven dataset with a comprehensive list of categories. This paper describes our proposed design of such categories and subcategories for Casual Conversations v2.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022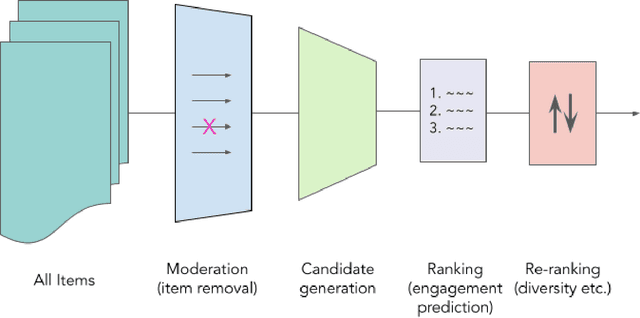
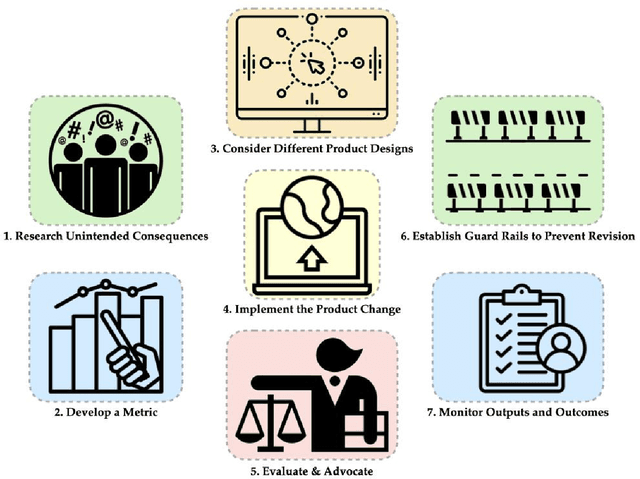
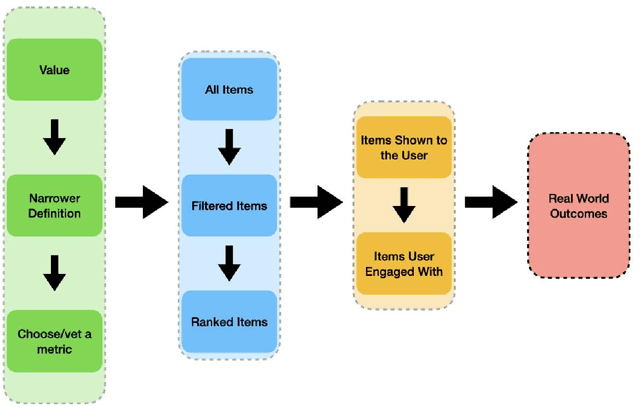

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.