 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBench: Visual Reasoning Requires Rethinking Vision-Language Beyond Scaling
Aug 09, 2024



Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks, researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress. To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a comprehensive range of carefully categorized capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples. We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today's best VLMs struggle on simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve. Where scale falls short, we find that more precise interventions, such as data quality or tailored-learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base with the full set of 50+ benchmarks and comparisons across 59 models as well as a distilled, representative set of benchmarks that runs in 5 minutes on a single GPU.
The Bias of Harmful Label Associations in Vision-Language Models
Feb 11, 2024Despite the remarkable performance of foundation vision-language models, the shared representation space for text and vision can also encode harmful label associations detrimental to fairness. While prior work has uncovered bias in vision-language models' (VLMs) classification performance across geography, work has been limited along the important axis of harmful label associations due to a lack of rich, labeled data. In this work, we investigate harmful label associations in the recently released Casual Conversations datasets containing more than 70,000 videos. We study bias in the frequency of harmful label associations across self-provided labels for age, gender, apparent skin tone, and physical adornments across several leading VLMs. We find that VLMs are $4-13$x more likely to harmfully classify individuals with darker skin tones. We also find scaling transformer encoder model size leads to higher confidence in harmful predictions. Finally, we find improvements on standard vision tasks across VLMs does not address disparities in harmful label associations.
VPA: Fully Test-Time Visual Prompt Adaptation
Sep 26, 2023



Textual prompt tuning has demonstrated significant performance improvements in adapting natural language processing models to a variety of downstream tasks by treating hand-engineered prompts as trainable parameters. Inspired by the success of textual prompting, several studies have investigated the efficacy of visual prompt tuning. In this work, we present Visual Prompt Adaptation (VPA), the first framework that generalizes visual prompting with test-time adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information. We examine our VPA design under diverse adaptation settings, encompassing single-image, batched-image, and pseudo-label adaptation. We evaluate VPA on multiple tasks, including out-of-distribution (OOD) generalization, corruption robustness, and domain adaptation. Experimental results reveal that VPA effectively enhances OOD generalization by 3.3% across various models, surpassing previous test-time approaches. Furthermore, we show that VPA improves corruption robustness by 6.5% compared to strong baselines. Finally, we demonstrate that VPA also boosts domain adaptation performance by relatively 5.2%. Our VPA also exhibits marked effectiveness in improving the robustness of zero-shot recognition for vision-language models.
Data-Driven but Privacy-Conscious: Pedestrian Dataset De-identification via Full-Body Person Synthesis
Jun 22, 2023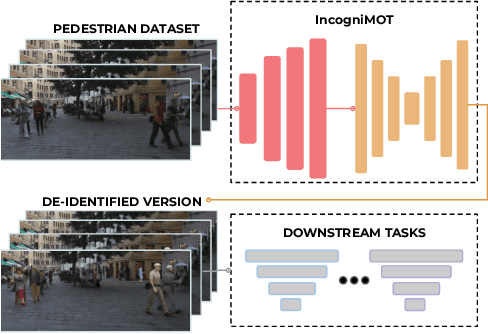

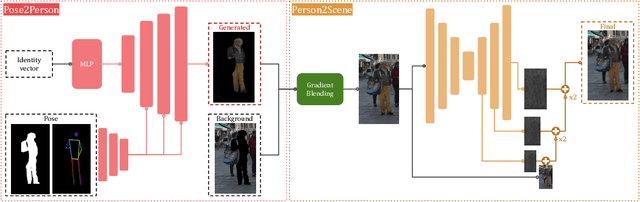

The advent of data-driven technology solutions is accompanied by an increasing concern with data privacy. This is of particular importance for human-centered image recognition tasks, such as pedestrian detection, re-identification, and tracking. To highlight the importance of privacy issues and motivate future research, we motivate and introduce the Pedestrian Dataset De-Identification (PDI) task. PDI evaluates the degree of de-identification and downstream task training performance for a given de-identification method. As a first baseline, we propose IncogniMOT, a two-stage full-body de-identification pipeline based on image synthesis via generative adversarial networks. The first stage replaces target pedestrians with synthetic identities. To improve downstream task performance, we then apply stage two, which blends and adapts the synthetic image parts into the data. To demonstrate the effectiveness of IncogniMOT, we generate a fully de-identified version of the MOT17 pedestrian tracking dataset and analyze its application as training data for pedestrian re-identification, detection, and tracking models. Furthermore, we show how our data is able to narrow the synthetic-to-real performance gap in a privacy-conscious manner.
Pinpointing Why Object Recognition Performance Degrades Across Income Levels and Geographies
Apr 11, 2023



Despite impressive advances in object-recognition, deep learning systems' performance degrades significantly across geographies and lower income levels raising pressing concerns of inequity. Addressing such performance gaps remains a challenge, as little is understood about why performance degrades across incomes or geographies. We take a step in this direction by annotating images from Dollar Street, a popular benchmark of geographically and economically diverse images, labeling each image with factors such as color, shape, and background. These annotations unlock a new granular view into how objects differ across incomes and regions. We then use these object differences to pinpoint model vulnerabilities across incomes and regions. We study a range of modern vision models, finding that performance disparities are most associated with differences in texture, occlusion, and images with darker lighting. We illustrate how insights from our factor labels can surface mitigations to improve models' performance disparities. As an example, we show that mitigating a model's vulnerability to texture can improve performance on the lower income level. We release all the factor annotations along with an interactive dashboard to facilitate research into more equitable vision systems.
The Casual Conversations v2 Dataset
Mar 08, 2023



This paper introduces a new large consent-driven dataset aimed at assisting in the evaluation of algorithmic bias and robustness of computer vision and audio speech models in regards to 11 attributes that are self-provided or labeled by trained annotators. The dataset includes 26,467 videos of 5,567 unique paid participants, with an average of almost 5 videos per person, recorded in Brazil, India, Indonesia, Mexico, Vietnam, Philippines, and the USA, representing diverse demographic characteristics. The participants agreed for their data to be used in assessing fairness of AI models and provided self-reported age, gender, language/dialect, disability status, physical adornments, physical attributes and geo-location information, while trained annotators labeled apparent skin tone using the Fitzpatrick Skin Type and Monk Skin Tone scales, and voice timbre. Annotators also labeled for different recording setups and per-second activity annotations.
A Whac-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
Dec 09, 2022



Machine learning models have been found to learn shortcuts -- unintended decision rules that are unable to generalize -- undermining models' reliability. Previous works address this problem under the tenuous assumption that only a single shortcut exists in the training data. Real-world images are rife with multiple visual cues from background to texture. Key to advancing the reliability of vision systems is understanding whether existing methods can overcome multiple shortcuts or struggle in a Whac-A-Mole game, i.e., where mitigating one shortcut amplifies reliance on others. To address this shortcoming, we propose two benchmarks: 1) UrbanCars, a dataset with precisely controlled spurious cues, and 2) ImageNet-W, an evaluation set based on ImageNet for watermark, a shortcut we discovered affects nearly every modern vision model. Along with texture and background, ImageNet-W allows us to study multiple shortcuts emerging from training on natural images. We find computer vision models, including large foundation models -- regardless of training set, architecture, and supervision -- struggle when multiple shortcuts are present. Even methods explicitly designed to combat shortcuts struggle in a Whac-A-Mole dilemma. To tackle this challenge, we propose Last Layer Ensemble, a simple-yet-effective method to mitigate multiple shortcuts without Whac-A-Mole behavior. Our results surface multi-shortcut mitigation as an overlooked challenge critical to advancing the reliability of vision systems. The datasets and code are released: https://github.com/facebookresearch/Whac-A-Mole.git.
Casual Conversations v2: Designing a large consent-driven dataset to measure algorithmic bias and robustness
Nov 10, 2022



Developing robust and fair AI systems require datasets with comprehensive set of labels that can help ensure the validity and legitimacy of relevant measurements. Recent efforts, therefore, focus on collecting person-related datasets that have carefully selected labels, including sensitive characteristics, and consent forms in place to use those attributes for model testing and development. Responsible data collection involves several stages, including but not limited to determining use-case scenarios, selecting categories (annotations) such that the data are fit for the purpose of measuring algorithmic bias for subgroups and most importantly ensure that the selected categories/subcategories are robust to regional diversities and inclusive of as many subgroups as possible. Meta, in a continuation of our efforts to measure AI algorithmic bias and robustness (https://ai.facebook.com/blog/shedding-light-on-fairness-in-ai-with-a-new-data-set), is working on collecting a large consent-driven dataset with a comprehensive list of categories. This paper describes our proposed design of such categories and subcategories for Casual Conversations v2.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Generating High Fidelity Data from Low-density Regions using Diffusion Models
Mar 31, 2022
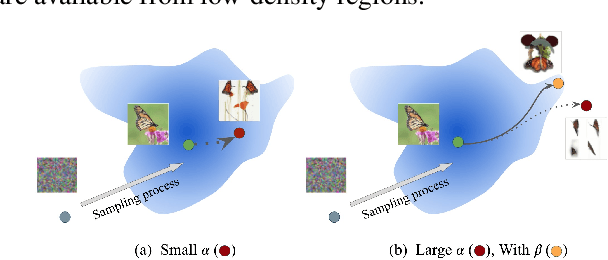

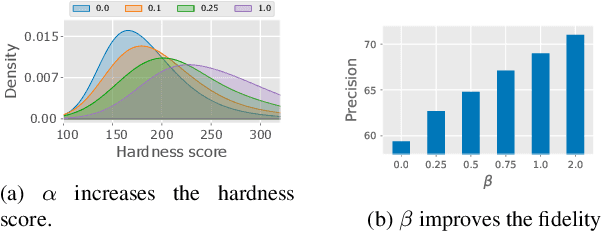
Our work focuses on addressing sample deficiency from low-density regions of data manifold in common image datasets. We leverage diffusion process based generative models to synthesize novel images from low-density regions. We observe that uniform sampling from diffusion models predominantly samples from high-density regions of the data manifold. Therefore, we modify the sampling process to guide it towards low-density regions while simultaneously maintaining the fidelity of synthetic data. We rigorously demonstrate that our process successfully generates novel high fidelity samples from low-density regions. We further examine generated samples and show that the model does not memorize low-density data and indeed learns to generate novel samples from low-density regions.