 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfQA: Answer Only If You Are Confident
Jun 08, 2025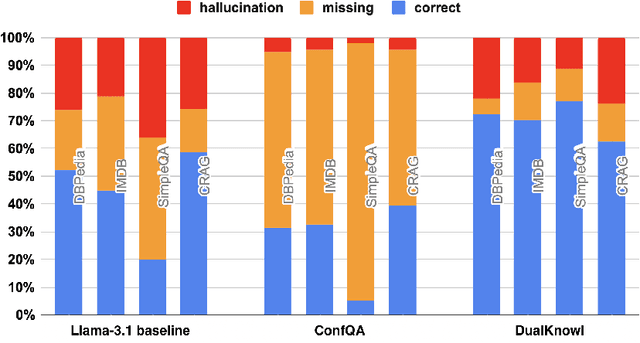
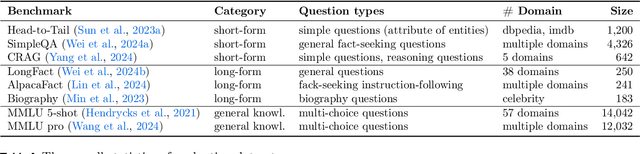
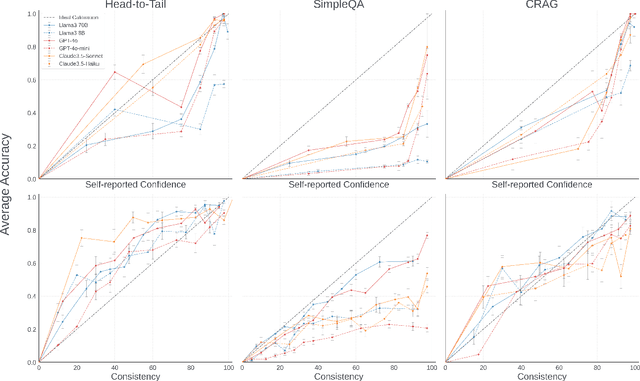
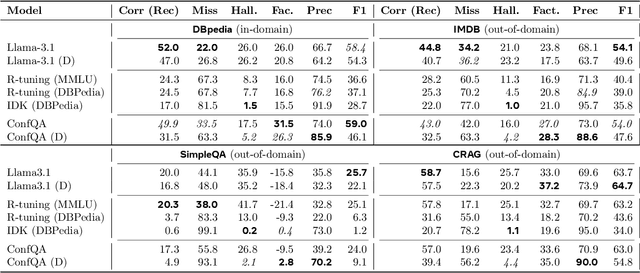
Can we teach Large Language Models (LLMs) to refrain from hallucinating factual statements? In this paper we present a fine-tuning strategy that we call ConfQA, which can reduce hallucination rate from 20-40% to under 5% across multiple factuality benchmarks. The core idea is simple: when the LLM answers a question correctly, it is trained to continue with the answer; otherwise, it is trained to admit "I am unsure". But there are two key factors that make the training highly effective. First, we introduce a dampening prompt "answer only if you are confident" to explicitly guide the behavior, without which hallucination remains high as 15%-25%. Second, we leverage simple factual statements, specifically attribute values from knowledge graphs, to help LLMs calibrate the confidence, resulting in robust generalization across domains and question types. Building on this insight, we propose the Dual Neural Knowledge framework, which seamlessly select between internally parameterized neural knowledge and externally recorded symbolic knowledge based on ConfQA's confidence. The framework enables potential accuracy gains to beyond 95%, while reducing unnecessary external retrievals by over 30%.
Improving Factuality with Explicit Working Memory
Dec 24, 2024



Large language models can generate factually inaccurate content, a problem known as hallucination. Recent works have built upon retrieved-augmented generation to improve factuality through iterative prompting but these methods are limited by the traditional RAG design. To address these challenges, we introduce EWE (Explicit Working Memory), a novel approach that enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources. The memory is refreshed based on online fact-checking and retrieval feedback, allowing EWE to rectify false claims during the generation process and ensure more accurate and reliable outputs. Our experiments demonstrate that Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 10 points absolute without sacrificing the helpfulness of the responses. Further analysis reveals that the design of rules for memory updates, configurations of memory units, and the quality of the retrieval datastore are crucial factors for influencing model performance.
Chained Tuning Leads to Biased Forgetting
Dec 21, 2024



Large language models (LLMs) are often fine-tuned for use on downstream tasks, though this can degrade capabilities learned during previous training. This phenomenon, often referred to as catastrophic forgetting, has important potential implications for the safety of deployed models. In this work, we first show that models trained on downstream tasks forget their safety tuning to a greater extent than models trained in the opposite order.Second, we show that forgetting disproportionately impacts safety information about certain groups. To quantify this phenomenon, we define a new metric we term biased forgetting. We conduct a systematic evaluation of the effects of task ordering on forgetting and apply mitigations that can help the model recover from the forgetting observed. We hope our findings can better inform methods for chaining the finetuning of LLMs in continual learning settings to enable training of safer and less toxic models.
Improving Geo-diversity of Generated Images with Contextualized Vendi Score Guidance
Jun 06, 2024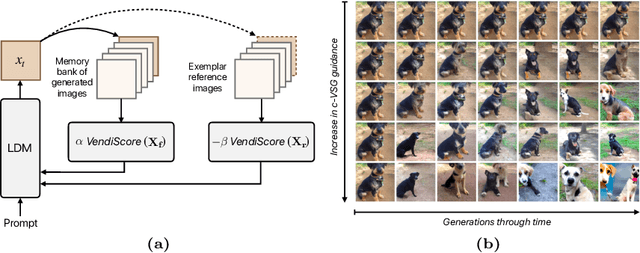

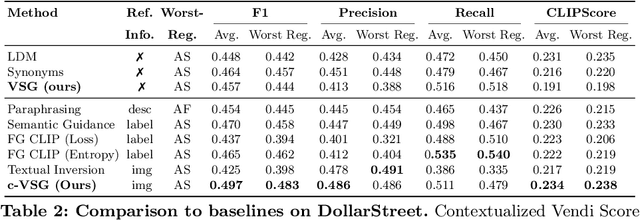

With the growing popularity of text-to-image generative models, there has been increasing focus on understanding their risks and biases. Recent work has found that state-of-the-art models struggle to depict everyday objects with the true diversity of the real world and have notable gaps between geographic regions. In this work, we aim to increase the diversity of generated images of common objects such that per-region variations are representative of the real world. We introduce an inference time intervention, contextualized Vendi Score Guidance (c-VSG), that guides the backwards steps of latent diffusion models to increase the diversity of a sample as compared to a "memory bank" of previously generated images while constraining the amount of variation within that of an exemplar set of real-world contextualizing images. We evaluate c-VSG with two geographically representative datasets and find that it substantially increases the diversity of generated images, both for the worst performing regions and on average, while simultaneously maintaining or improving image quality and consistency. Additionally, qualitative analyses reveal that diversity of generated images is significantly improved, including along the lines of reductive region portrayals present in the original model. We hope that this work is a step towards text-to-image generative models that reflect the true geographic diversity of the world.
The Bias of Harmful Label Associations in Vision-Language Models
Feb 11, 2024Despite the remarkable performance of foundation vision-language models, the shared representation space for text and vision can also encode harmful label associations detrimental to fairness. While prior work has uncovered bias in vision-language models' (VLMs) classification performance across geography, work has been limited along the important axis of harmful label associations due to a lack of rich, labeled data. In this work, we investigate harmful label associations in the recently released Casual Conversations datasets containing more than 70,000 videos. We study bias in the frequency of harmful label associations across self-provided labels for age, gender, apparent skin tone, and physical adornments across several leading VLMs. We find that VLMs are $4-13$x more likely to harmfully classify individuals with darker skin tones. We also find scaling transformer encoder model size leads to higher confidence in harmful predictions. Finally, we find improvements on standard vision tasks across VLMs does not address disparities in harmful label associations.