 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRuB: Social Concept Reasoning under Rubric-Based Evaluation
May 07, 2026While many studies of Large Language Model (LLM) reasoning capabilities emphasize mathematical or technical tasks, few address reasoning about social concepts: the abstract ideas shaping social norms, culture, and institutions. This understudied capability is essential for modern models acting as social agents, yet no systematic evaluation methodology targets it. We introduce SCRuB (Social Concept Reasoning under Rubric-Based Evaluation), a framework designed for this setting of task indeterminacy. Our goal is to measure the degree to which a model reasons about social concepts with the depth and critical rigor of a human expert. SCRuB proceeds in three phases: prompt construction from established sources, response generation by experts and models, and comparative evaluation using a five-dimensional critical thinking rubric. To enable generalization of the pipeline, we introduce a Panel of Disciplinary Perspectives ensemble validated against independent expert judges. We release SCRuBEval (n=4,711 evaluation prompts) and SCRuBAnnotations (300 expert-authored responses and 150 expert comparative judgments from 45 PhD-level scholars). Our results show that frontier models consistently outperform human experts across all five rubric dimensions. Across 1,170 pairwise comparisons, expert judges ranked a model response first in 80.8% of judgments and preferred model responses overall 74.4% of the time. Ultimately, this study provides the first expert-grounded demonstration of evaluation saturation for social concept reasoning: the single-turn exam-style format has reached its ceiling for models and humans alike.
Beg to Differ: Understanding Reasoning-Answer Misalignment Across Languages
Dec 27, 2025Large language models demonstrate strong reasoning capabilities through chain-of-thought prompting, but whether this reasoning quality transfers across languages remains underexplored. We introduce a human-validated framework to evaluate whether model-generated reasoning traces logically support their conclusions across languages. Analyzing 65k reasoning traces from GlobalMMLU questions across 6 languages and 6 frontier models, we uncover a critical blind spot: while models achieve high task accuracy, their reasoning can fail to support their conclusions. Reasoning traces in non-Latin scripts show at least twice as much misalignment between their reasoning and conclusions than those in Latin scripts. We develop an error taxonomy through human annotation to characterize these failures, finding they stem primarily from evidential errors (unsupported claims, ambiguous facts) followed by illogical reasoning steps. Our findings demonstrate that current multilingual evaluation practices provide an incomplete picture of model reasoning capabilities and highlight the need for reasoning-aware evaluation frameworks.
What's in Common? Multimodal Models Hallucinate When Reasoning Across Scenes
Nov 05, 2025Multimodal language models possess a remarkable ability to handle an open-vocabulary's worth of objects. Yet the best models still suffer from hallucinations when reasoning about scenes in the real world, revealing a gap between their seemingly strong performance on existing perception benchmarks that are saturating and their reasoning in the real world. To address this gap, we build a novel benchmark of in-the-wild scenes that we call Common-O. With more than 10.5k examples using exclusively new images not found in web training data to avoid contamination, Common-O goes beyond just perception, inspired by cognitive tests for humans, to probe reasoning across scenes by asking "what's in common?". We evaluate leading multimodal language models, including models specifically trained to perform chain-of-thought reasoning. We find that perceiving objects in single images is tractable for most models, yet reasoning across scenes is very challenging even for the best models, including reasoning models. Despite saturating many leaderboards focusing on perception, the best performing model only achieves 35% on Common-O -- and on Common-O Complex, consisting of more complex scenes, the best model achieves only 1%. Curiously, we find models are more prone to hallucinate when similar objects are present in the scene, suggesting models may be relying on object co-occurrence seen during training. Among the models we evaluated, we found scale can provide modest improvements while models explicitly trained with multi-image inputs show bigger improvements, suggesting scaled multi-image training may offer promise. We make our benchmark publicly available to spur research into the challenge of hallucination when reasoning across scenes.
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Jun 11, 2025



Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair -- a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9\%, while the best open-source state-of-the-art video-language model achieves 40.2\% compared to random performance at 25\%.
DIMCIM: A Quantitative Evaluation Framework for Default-mode Diversity and Generalization in Text-to-Image Generative Models
Jun 05, 2025Recent advances in text-to-image (T2I) models have achieved impressive quality and consistency. However, this has come at the cost of representation diversity. While automatic evaluation methods exist for benchmarking model diversity, they either require reference image datasets or lack specificity about the kind of diversity measured, limiting their adaptability and interpretability. To address this gap, we introduce the Does-it/Can-it framework, DIM-CIM, a reference-free measurement of default-mode diversity ("Does" the model generate images with expected attributes?) and generalization capacity ("Can" the model generate diverse attributes for a particular concept?). We construct the COCO-DIMCIM benchmark, which is seeded with COCO concepts and captions and augmented by a large language model. With COCO-DIMCIM, we find that widely-used models improve in generalization at the cost of default-mode diversity when scaling from 1.5B to 8.1B parameters. DIMCIM also identifies fine-grained failure cases, such as attributes that are generated with generic prompts but are rarely generated when explicitly requested. Finally, we use DIMCIM to evaluate the training data of a T2I model and observe a correlation of 0.85 between diversity in training images and default-mode diversity. Our work provides a flexible and interpretable framework for assessing T2I model diversity and generalization, enabling a more comprehensive understanding of model performance.
Multi-Modal Language Models as Text-to-Image Model Evaluators
May 01, 2025The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
What makes a good metric? Evaluating automatic metrics for text-to-image consistency
Dec 18, 2024


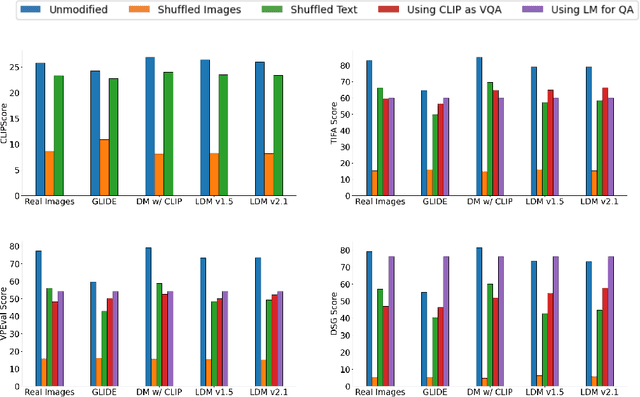
Language models are increasingly being incorporated as components in larger AI systems for various purposes, from prompt optimization to automatic evaluation. In this work, we analyze the construct validity of four recent, commonly used methods for measuring text-to-image consistency - CLIPScore, TIFA, VPEval, and DSG - which rely on language models and/or VQA models as components. We define construct validity for text-image consistency metrics as a set of desiderata that text-image consistency metrics should have, and find that no tested metric satisfies all of them. We find that metrics lack sufficient sensitivity to language and visual properties. Next, we find that TIFA, VPEval and DSG contribute novel information above and beyond CLIPScore, but also that they correlate highly with each other. We also ablate different aspects of the text-image consistency metrics and find that not all model components are strictly necessary, also a symptom of insufficient sensitivity to visual information. Finally, we show that all three VQA-based metrics likely rely on familiar text shortcuts (such as yes-bias in QA) that call their aptitude as quantitative evaluations of model performance into question.
Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Dec 06, 2024The BabyLM Challenge is a community effort to close the data-efficiency gap between human and computational language learners. Participants compete to optimize language model training on a fixed language data budget of 100 million words or less. This year, we released improved text corpora, as well as a vision-and-language corpus to facilitate research into cognitively plausible vision language models. Submissions were compared on evaluation tasks targeting grammatical ability, (visual) question answering, pragmatic abilities, and grounding, among other abilities. Participants could submit to a 10M-word text-only track, a 100M-word text-only track, and/or a 100M-word and image multimodal track. From 31 submissions employing diverse methods, a hybrid causal-masked language model architecture outperformed other approaches. No submissions outperformed the baselines in the multimodal track. In follow-up analyses, we found a strong relationship between training FLOPs and average performance across tasks, and that the best-performing submissions proposed changes to the training data, training objective, and model architecture. This year's BabyLM Challenge shows that there is still significant room for innovation in this setting, in particular for image-text modeling, but community-driven research can yield actionable insights about effective strategies for small-scale language modeling.
Improving Model Evaluation using SMART Filtering of Benchmark Datasets
Oct 26, 2024



One of the most challenging problems facing NLP today is evaluation. Some of the most pressing issues pertain to benchmark saturation, data contamination, and diversity in the quality of test examples. To address these concerns, we propose Selection Methodology for Accurate, Reduced, and Targeted (SMART) filtering, a novel approach to select a high-quality subset of examples from existing benchmark datasets by systematically removing less informative and less challenging examples. Our approach applies three filtering criteria, removing (i) easy examples, (ii) data-contaminated examples, and (iii) examples that are similar to each other based on distance in an embedding space. We demonstrate the effectiveness of SMART on three multiple choice QA datasets, where our methodology increases efficiency by reducing dataset size by 48\% on average, while increasing Pearson correlation with rankings from ChatBot Arena, a more open-ended human evaluation setting. Our method enables us to be more efficient, whether using SMART to make new benchmarks more challenging or to revitalize older datasets, while still preserving the relative model rankings.