 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIMCIM: A Quantitative Evaluation Framework for Default-mode Diversity and Generalization in Text-to-Image Generative Models
Jun 05, 2025Recent advances in text-to-image (T2I) models have achieved impressive quality and consistency. However, this has come at the cost of representation diversity. While automatic evaluation methods exist for benchmarking model diversity, they either require reference image datasets or lack specificity about the kind of diversity measured, limiting their adaptability and interpretability. To address this gap, we introduce the Does-it/Can-it framework, DIM-CIM, a reference-free measurement of default-mode diversity ("Does" the model generate images with expected attributes?) and generalization capacity ("Can" the model generate diverse attributes for a particular concept?). We construct the COCO-DIMCIM benchmark, which is seeded with COCO concepts and captions and augmented by a large language model. With COCO-DIMCIM, we find that widely-used models improve in generalization at the cost of default-mode diversity when scaling from 1.5B to 8.1B parameters. DIMCIM also identifies fine-grained failure cases, such as attributes that are generated with generic prompts but are rarely generated when explicitly requested. Finally, we use DIMCIM to evaluate the training data of a T2I model and observe a correlation of 0.85 between diversity in training images and default-mode diversity. Our work provides a flexible and interpretable framework for assessing T2I model diversity and generalization, enabling a more comprehensive understanding of model performance.
Fine-Tuning In-House Large Language Models to Infer Differential Diagnosis from Radiology Reports
Oct 11, 2024



Radiology reports summarize key findings and differential diagnoses derived from medical imaging examinations. The extraction of differential diagnoses is crucial for downstream tasks, including patient management and treatment planning. However, the unstructured nature of these reports, characterized by diverse linguistic styles and inconsistent formatting, presents significant challenges. Although proprietary large language models (LLMs) such as GPT-4 can effectively retrieve clinical information, their use is limited in practice by high costs and concerns over the privacy of protected health information (PHI). This study introduces a pipeline for developing in-house LLMs tailored to identify differential diagnoses from radiology reports. We first utilize GPT-4 to create 31,056 labeled reports, then fine-tune open source LLM using this dataset. Evaluated on a set of 1,067 reports annotated by clinicians, the proposed model achieves an average F1 score of 92.1\%, which is on par with GPT-4 (90.8\%). Through this study, we provide a methodology for constructing in-house LLMs that: match the performance of GPT, reduce dependence on expensive proprietary models, and enhance the privacy and security of PHI.
Affective Faces for Goal-Driven Dyadic Communication
Jan 26, 2023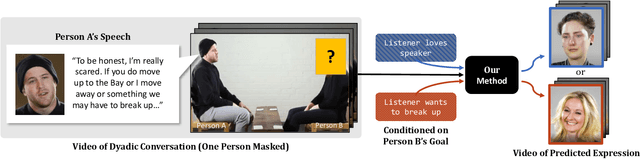
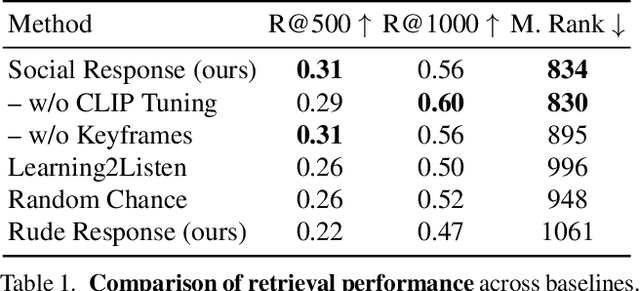
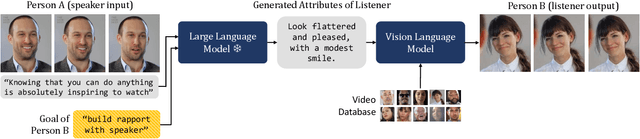

We introduce a video framework for modeling the association between verbal and non-verbal communication during dyadic conversation. Given the input speech of a speaker, our approach retrieves a video of a listener, who has facial expressions that would be socially appropriate given the context. Our approach further allows the listener to be conditioned on their own goals, personalities, or backgrounds. Our approach models conversations through a composition of large language models and vision-language models, creating internal representations that are interpretable and controllable. To study multimodal communication, we propose a new video dataset of unscripted conversations covering diverse topics and demographics. Experiments and visualizations show our approach is able to output listeners that are significantly more socially appropriate than baselines. However, many challenges remain, and we release our dataset publicly to spur further progress. See our website for video results, data, and code: https://realtalk.cs.columbia.edu.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales
Dec 12, 2022Many visual recognition models are evaluated only on their classification accuracy, a metric for which they obtain strong performance. In this paper, we investigate whether computer vision models can also provide correct rationales for their predictions. We propose a ``doubly right'' object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales. We find that state-of-the-art visual models, such as CLIP, often provide incorrect rationales for their categorical predictions. However, by transferring the rationales from language models into visual representations through a tailored dataset, we show that we can learn a ``why prompt,'' which adapts large visual representations to produce correct rationales. Visualizations and empirical experiments show that our prompts significantly improve performance on doubly right object recognition, in addition to zero-shot transfer to unseen tasks and datasets.
COFAR: Commonsense and Factual Reasoning in Image Search
Oct 16, 2022

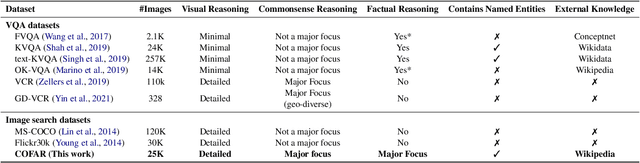
One characteristic that makes humans superior to modern artificially intelligent models is the ability to interpret images beyond what is visually apparent. Consider the following two natural language search queries - (i) "a queue of customers patiently waiting to buy ice cream" and (ii) "a queue of tourists going to see a famous Mughal architecture in India." Interpreting these queries requires one to reason with (i) Commonsense such as interpreting people as customers or tourists, actions as waiting to buy or going to see; and (ii) Fact or world knowledge associated with named visual entities, for example, whether the store in the image sells ice cream or whether the landmark in the image is a Mughal architecture located in India. Such reasoning goes beyond just visual recognition. To enable both commonsense and factual reasoning in the image search, we present a unified framework, namely Knowledge Retrieval-Augmented Multimodal Transformer (KRAMT), that treats the named visual entities in an image as a gateway to encyclopedic knowledge and leverages them along with natural language query to ground relevant knowledge. Further, KRAMT seamlessly integrates visual content and grounded knowledge to learn alignment between images and search queries. This unified framework is then used to perform image search requiring commonsense and factual reasoning. The retrieval performance of KRAMT is evaluated and compared with related approaches on a new dataset we introduce - namely COFAR. We make our code and dataset available at https://vl2g.github.io/projects/cofar
Few-shot Visual Relationship Co-localization
Aug 26, 2021



In this paper, given a small bag of images, each containing a common but latent predicate, we are interested in localizing visual subject-object pairs connected via the common predicate in each of the images. We refer to this novel problem as visual relationship co-localization or VRC as an abbreviation. VRC is a challenging task, even more so than the well-studied object co-localization task. This becomes further challenging when using just a few images, the model has to learn to co-localize visual subject-object pairs connected via unseen predicates. To solve VRC, we propose an optimization framework to select a common visual relationship in each image of the bag. The goal of the optimization framework is to find the optimal solution by learning visual relationship similarity across images in a few-shot setting. To obtain robust visual relationship representation, we utilize a simple yet effective technique that learns relationship embedding as a translation vector from visual subject to visual object in a shared space. Further, to learn visual relationship similarity, we utilize a proven meta-learning technique commonly used for few-shot classification tasks. Finally, to tackle the combinatorial complexity challenge arising from an exponential number of feasible solutions, we use a greedy approximation inference algorithm that selects approximately the best solution. We extensively evaluate our proposed framework on variations of bag sizes obtained from two challenging public datasets, namely VrR-VG and VG-150, and achieve impressive visual co-localization performance.