 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Video Meetings Change Your Expression
Jun 03, 2024



Do our facial expressions change when we speak over video calls? Given two unpaired sets of videos of people, we seek to automatically find spatio-temporal patterns that are distinctive of each set. Existing methods use discriminative approaches and perform post-hoc explainability analysis. Such methods are insufficient as they are unable to provide insights beyond obvious dataset biases, and the explanations are useful only if humans themselves are good at the task. Instead, we tackle the problem through the lens of generative domain translation: our method generates a detailed report of learned, input-dependent spatio-temporal features and the extent to which they vary between the domains. We demonstrate that our method can discover behavioral differences between conversing face-to-face (F2F) and on video-calls (VCs). We also show the applicability of our method on discovering differences in presidential communication styles. Additionally, we are able to predict temporal change-points in videos that decouple expressions in an unsupervised way, and increase the interpretability and usefulness of our model. Finally, our method, being generative, can be used to transform a video call to appear as if it were recorded in a F2F setting. Experiments and visualizations show our approach is able to discover a range of behaviors, taking a step towards deeper understanding of human behaviors.
Affective Faces for Goal-Driven Dyadic Communication
Jan 26, 2023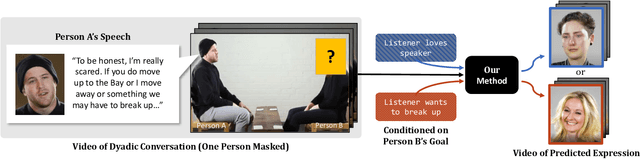
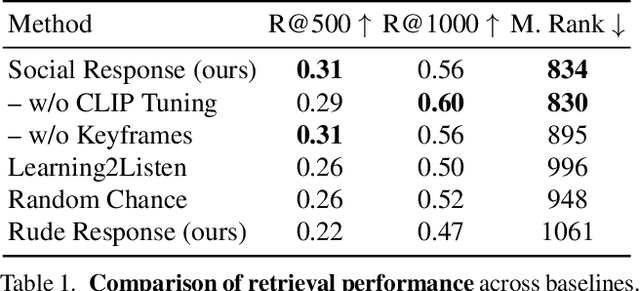
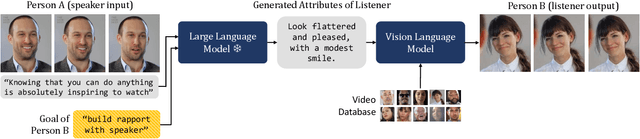

We introduce a video framework for modeling the association between verbal and non-verbal communication during dyadic conversation. Given the input speech of a speaker, our approach retrieves a video of a listener, who has facial expressions that would be socially appropriate given the context. Our approach further allows the listener to be conditioned on their own goals, personalities, or backgrounds. Our approach models conversations through a composition of large language models and vision-language models, creating internal representations that are interpretable and controllable. To study multimodal communication, we propose a new video dataset of unscripted conversations covering diverse topics and demographics. Experiments and visualizations show our approach is able to output listeners that are significantly more socially appropriate than baselines. However, many challenges remain, and we release our dataset publicly to spur further progress. See our website for video results, data, and code: https://realtalk.cs.columbia.edu.
FLEX: Full-Body Grasping Without Full-Body Grasps
Nov 21, 2022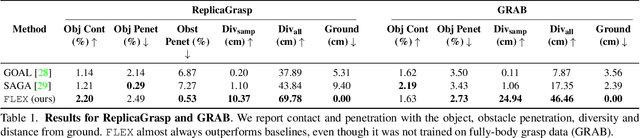
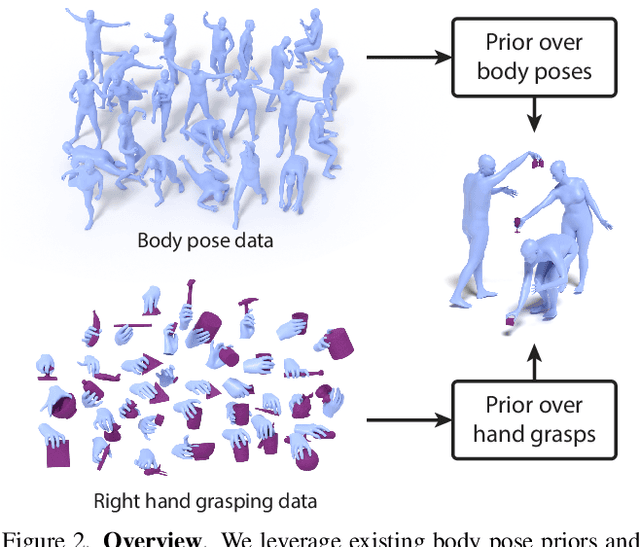
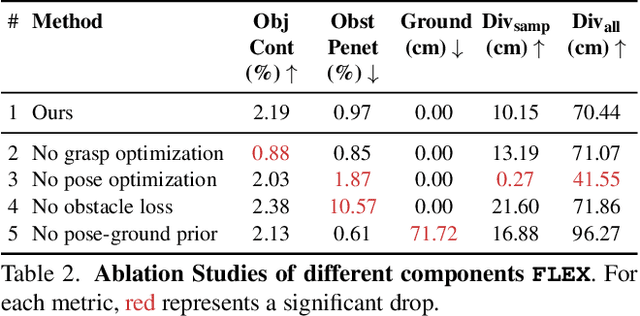
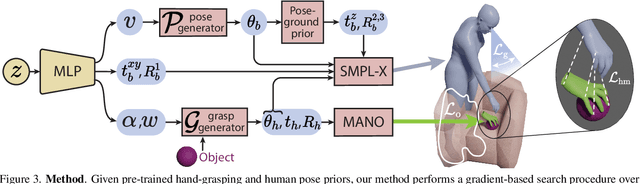
Synthesizing 3D human avatars interacting realistically with a scene is an important problem with applications in AR/VR, video games and robotics. Towards this goal, we address the task of generating a virtual human -- hands and full body -- grasping everyday objects. Existing methods approach this problem by collecting a 3D dataset of humans interacting with objects and training on this data. However, 1) these methods do not generalize to different object positions and orientations, or to the presence of furniture in the scene, and 2) the diversity of their generated full-body poses is very limited. In this work, we address all the above challenges to generate realistic, diverse full-body grasps in everyday scenes without requiring any 3D full-body grasping data. Our key insight is to leverage the existence of both full-body pose and hand grasping priors, composing them using 3D geometrical constraints to obtain full-body grasps. We empirically validate that these constraints can generate a variety of feasible human grasps that are superior to baselines both quantitatively and qualitatively. See our webpage for more details: https://flex.cs.columbia.edu/.
Landscape Learning for Neural Network Inversion
Jun 17, 2022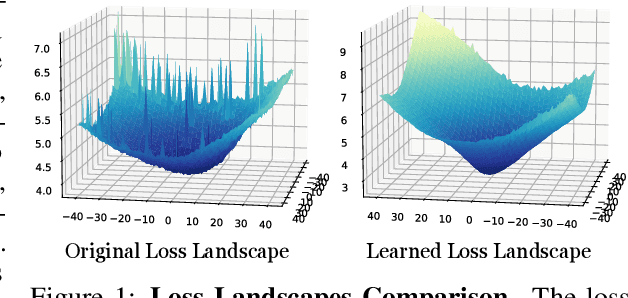
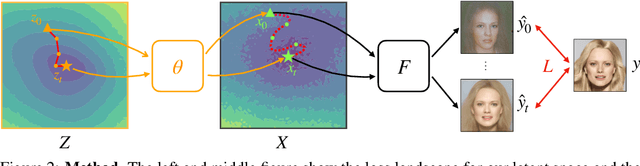

Many machine learning methods operate by inverting a neural network at inference time, which has become a popular technique for solving inverse problems in computer vision, robotics, and graphics. However, these methods often involve gradient descent through a highly non-convex loss landscape, causing the optimization process to be unstable and slow. We introduce a method that learns a loss landscape where gradient descent is efficient, bringing massive improvement and acceleration to the inversion process. We demonstrate this advantage on a number of methods for both generative and discriminative tasks, including GAN inversion, adversarial defense, and 3D human pose reconstruction.
Revealing Occlusions with 4D Neural Fields
Apr 22, 2022

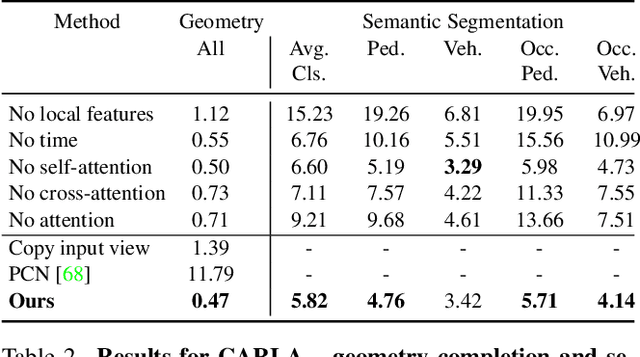
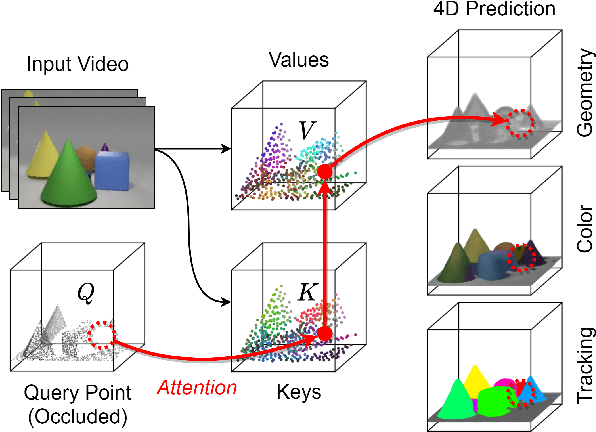
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks. Data, code, and models are available at https://occlusions.cs.columbia.edu/.
SOrT-ing VQA Models : Contrastive Gradient Learning for Improved Consistency
Oct 20, 2020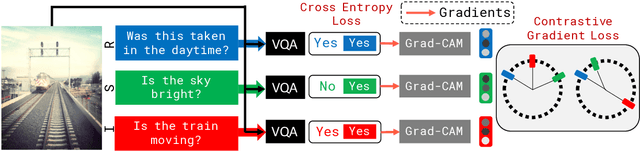



Recent research in Visual Question Answering (VQA) has revealed state-of-the-art models to be inconsistent in their understanding of the world -- they answer seemingly difficult questions requiring reasoning correctly but get simpler associated sub-questions wrong. These sub-questions pertain to lower level visual concepts in the image that models ideally should understand to be able to answer the higher level question correctly. To address this, we first present a gradient-based interpretability approach to determine the questions most strongly correlated with the reasoning question on an image, and use this to evaluate VQA models on their ability to identify the relevant sub-questions needed to answer a reasoning question. Next, we propose a contrastive gradient learning based approach called Sub-question Oriented Tuning (SOrT) which encourages models to rank relevant sub-questions higher than irrelevant questions for an <$image, reasoning-question$> pair. We show that SOrT improves model consistency by upto 6.5% points over existing baselines, while also improving visual grounding.
Feel The Music: Automatically Generating A Dance For An Input Song
Jun 23, 2020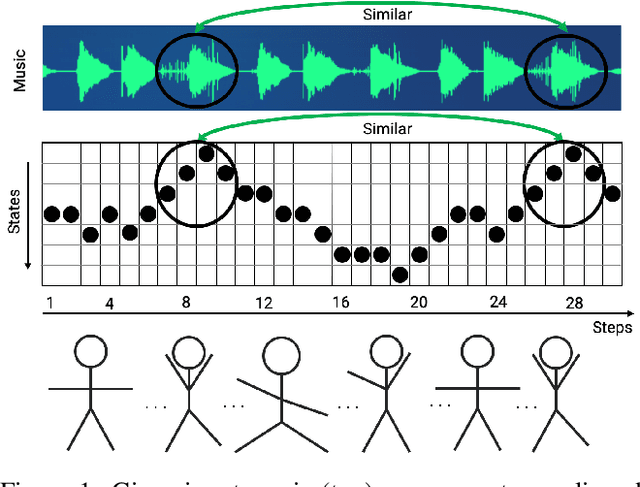
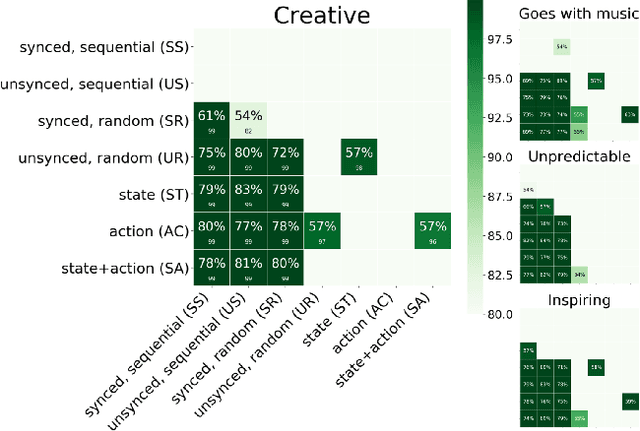
We present a general computational approach that enables a machine to generate a dance for any input music. We encode intuitive, flexible heuristics for what a 'good' dance is: the structure of the dance should align with the structure of the music. This flexibility allows the agent to discover creative dances. Human studies show that participants find our dances to be more creative and inspiring compared to meaningful baselines. We also evaluate how perception of creativity changes based on different presentations of the dance. Our code is available at https://github.com/purvaten/feel-the-music.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020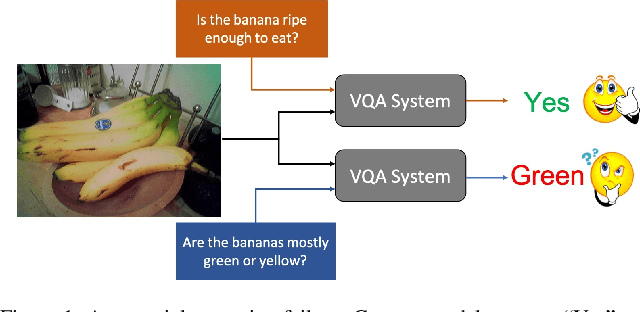

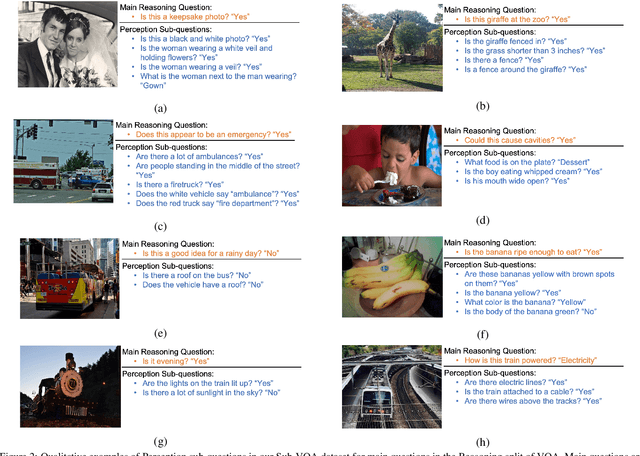
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.
Trick or TReAT: Thematic Reinforcement for Artistic Typography
Mar 19, 2019

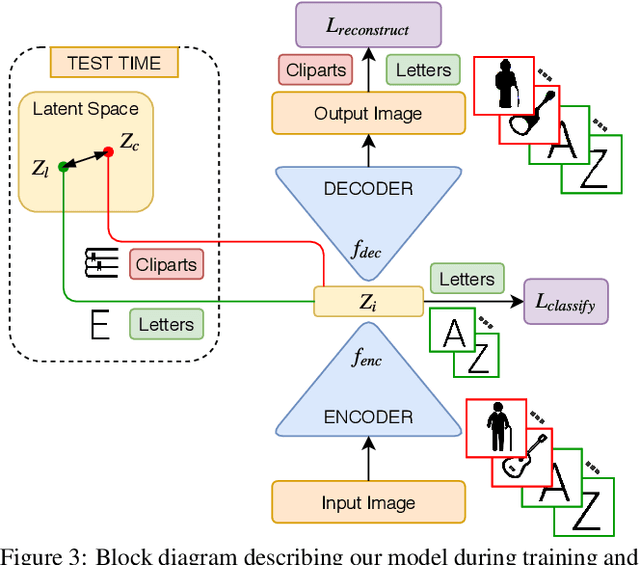

An approach to make text visually appealing and memorable is semantic reinforcement - the use of visual cues alluding to the context or theme in which the word is being used to reinforce the message (e.g., Google Doodles). We present a computational approach for semantic reinforcement called TReAT - Thematic Reinforcement for Artistic Typography. Given an input word (e.g. exam) and a theme (e.g. education), the individual letters of the input word are replaced by cliparts relevant to the theme which visually resemble the letters - adding creative context to the potentially boring input word. We use an unsupervised approach to learn a latent space to represent letters and cliparts and compute similarities between the two. Human studies show that participants can reliably recognize the word as well as the theme in our outputs (TReATs) and find them more creative compared to meaningful baselines.