 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
It's Time for Artistic Correspondence in Music and Video
Jun 14, 2022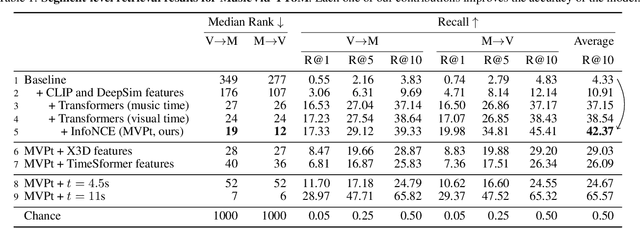
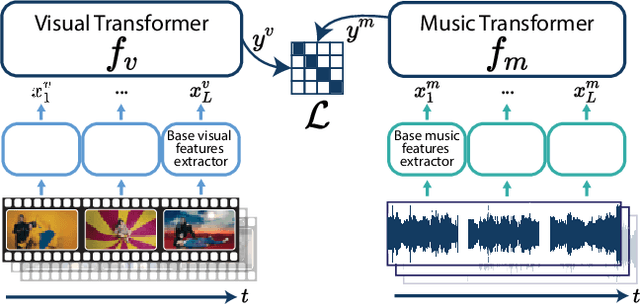
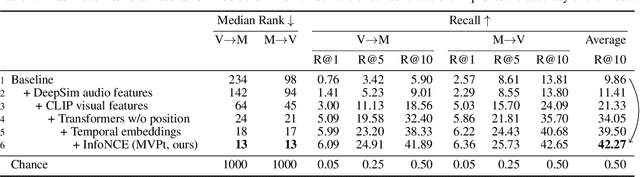
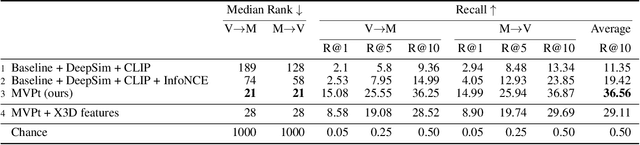
We present an approach for recommending a music track for a given video, and vice versa, based on both their temporal alignment and their correspondence at an artistic level. We propose a self-supervised approach that learns this correspondence directly from data, without any need of human annotations. In order to capture the high-level concepts that are required to solve the task, we propose modeling the long-term temporal context of both the video and the music signals, using Transformer networks for each modality. Experiments show that this approach strongly outperforms alternatives that do not exploit the temporal context. The combination of our contributions improve retrieval accuracy up to 10x over prior state of the art. This strong improvement allows us to introduce a wide range of analyses and applications. For instance, we can condition music retrieval based on visually defined attributes.
Revealing Occlusions with 4D Neural Fields
Apr 22, 2022

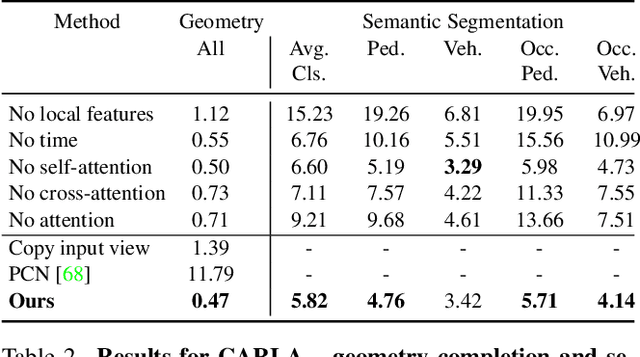
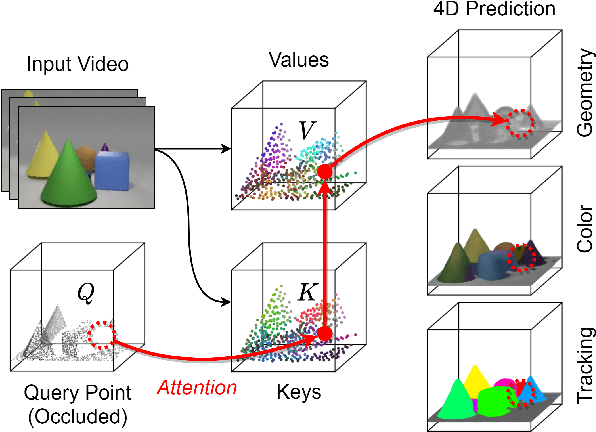
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks. Data, code, and models are available at https://occlusions.cs.columbia.edu/.