 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Faces in Things: A Model and Dataset for Pareidolia
Sep 24, 2024



The human visual system is well-tuned to detect faces of all shapes and sizes. While this brings obvious survival advantages, such as a better chance of spotting unknown predators in the bush, it also leads to spurious face detections. ``Face pareidolia'' describes the perception of face-like structure among otherwise random stimuli: seeing faces in coffee stains or clouds in the sky. In this paper, we study face pareidolia from a computer vision perspective. We present an image dataset of ``Faces in Things'', consisting of five thousand web images with human-annotated pareidolic faces. Using this dataset, we examine the extent to which a state-of-the-art human face detector exhibits pareidolia, and find a significant behavioral gap between humans and machines. We find that the evolutionary need for humans to detect animal faces, as well as human faces, may explain some of this gap. Finally, we propose a simple statistical model of pareidolia in images. Through studies on human subjects and our pareidolic face detectors we confirm a key prediction of our model regarding what image conditions are most likely to induce pareidolia. Dataset and Website: https://aka.ms/faces-in-things
Tracking through Containers and Occluders in the Wild
May 04, 2023Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce $\textbf{TCOW}$, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
CW-ERM: Improving Autonomous Driving Planning with Closed-loop Weighted Empirical Risk Minimization
Oct 11, 2022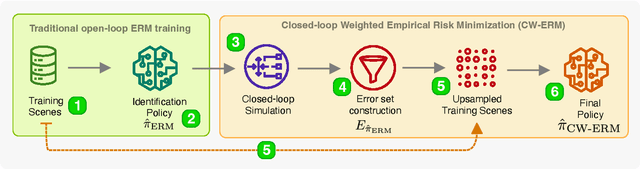
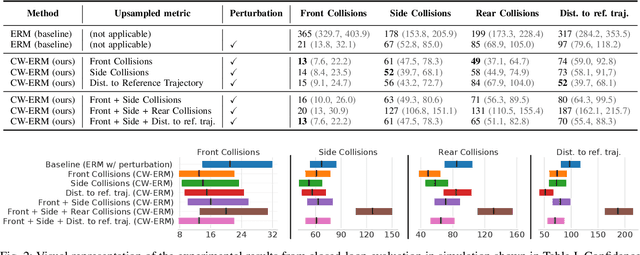
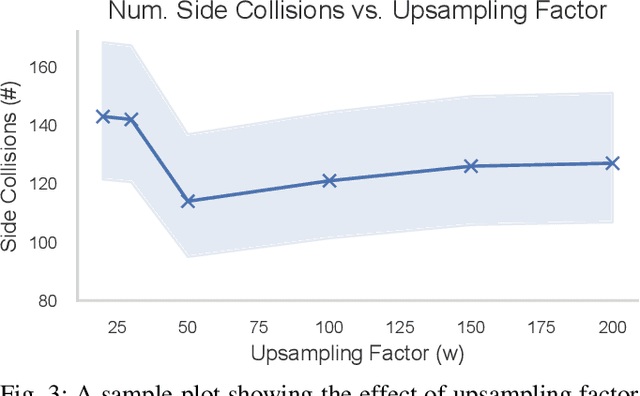
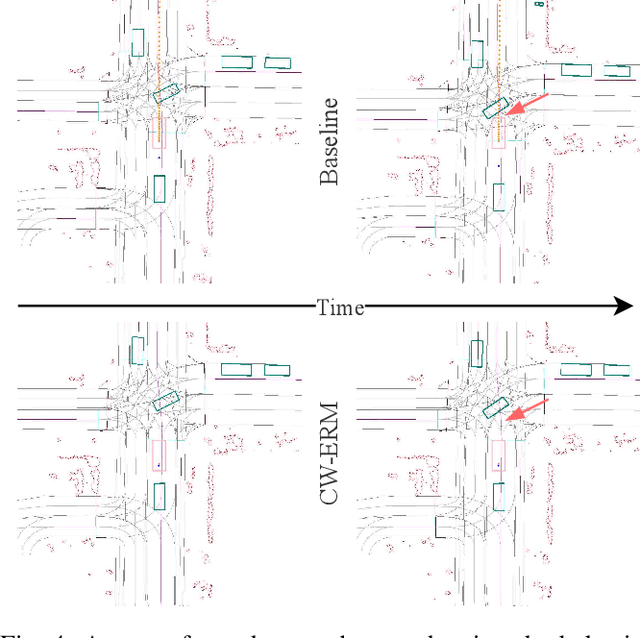
The imitation learning of self-driving vehicle policies through behavioral cloning is often carried out in an open-loop fashion, ignoring the effect of actions to future states. Training such policies purely with Empirical Risk Minimization (ERM) can be detrimental to real-world performance, as it biases policy networks towards matching only open-loop behavior, showing poor results when evaluated in closed-loop. In this work, we develop an efficient and simple-to-implement principle called Closed-loop Weighted Empirical Risk Minimization (CW-ERM), in which a closed-loop evaluation procedure is first used to identify training data samples that are important for practical driving performance and then we these samples to help debias the policy network. We evaluate CW-ERM in a challenging urban driving dataset and show that this procedure yields a significant reduction in collisions as well as other non-differentiable closed-loop metrics.
Fine-Grained Egocentric Hand-Object Segmentation: Dataset, Model, and Applications
Aug 07, 2022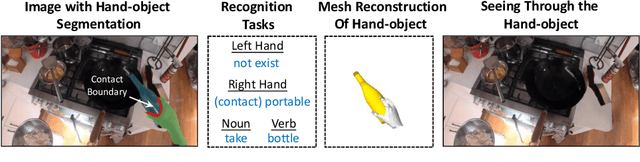
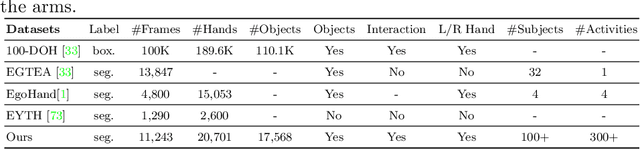
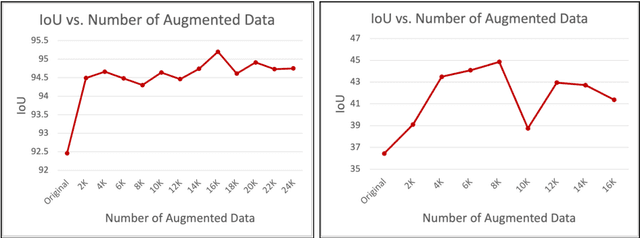

Egocentric videos offer fine-grained information for high-fidelity modeling of human behaviors. Hands and interacting objects are one crucial aspect of understanding a viewer's behaviors and intentions. We provide a labeled dataset consisting of 11,243 egocentric images with per-pixel segmentation labels of hands and objects being interacted with during a diverse array of daily activities. Our dataset is the first to label detailed hand-object contact boundaries. We introduce a context-aware compositional data augmentation technique to adapt to out-of-distribution YouTube egocentric video. We show that our robust hand-object segmentation model and dataset can serve as a foundational tool to boost or enable several downstream vision applications, including hand state classification, video activity recognition, 3D mesh reconstruction of hand-object interactions, and video inpainting of hand-object foregrounds in egocentric videos. Dataset and code are available at: https://github.com/owenzlz/EgoHOS
Shadows Shed Light on 3D Objects
Jun 17, 2022
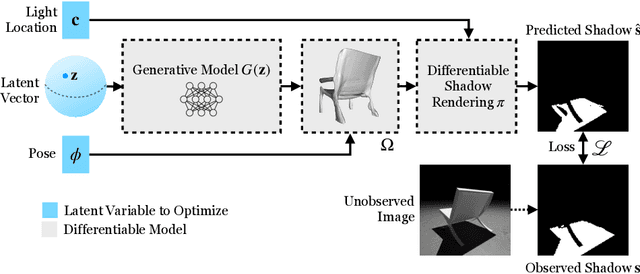
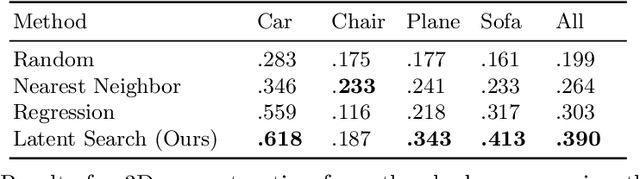
3D reconstruction is a fundamental problem in computer vision, and the task is especially challenging when the object to reconstruct is partially or fully occluded. We introduce a method that uses the shadows cast by an unobserved object in order to infer the possible 3D volumes behind the occlusion. We create a differentiable image formation model that allows us to jointly infer the 3D shape of an object, its pose, and the position of a light source. Since the approach is end-to-end differentiable, we are able to integrate learned priors of object geometry in order to generate realistic 3D shapes of different object categories. Experiments and visualizations show that the method is able to generate multiple possible solutions that are consistent with the observation of the shadow. Our approach works even when the position of the light source and object pose are both unknown. Our approach is also robust to real-world images where ground-truth shadow mask is unknown.
Revealing Occlusions with 4D Neural Fields
Apr 22, 2022

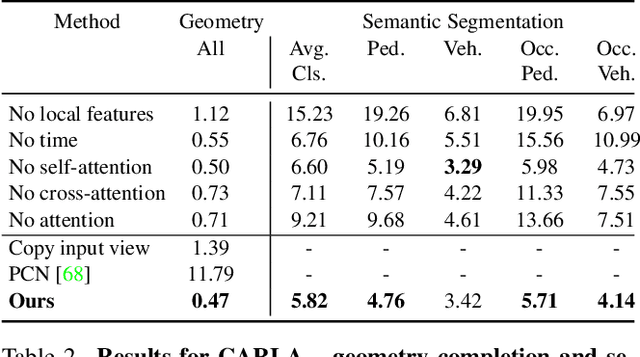
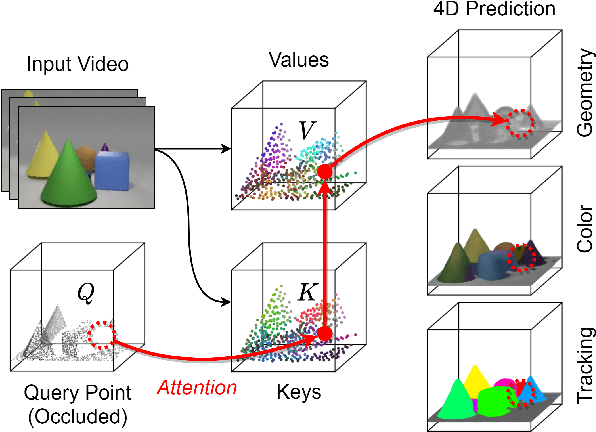
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks. Data, code, and models are available at https://occlusions.cs.columbia.edu/.
The Way to my Heart is through Contrastive Learning: Remote Photoplethysmography from Unlabelled Video
Nov 18, 2021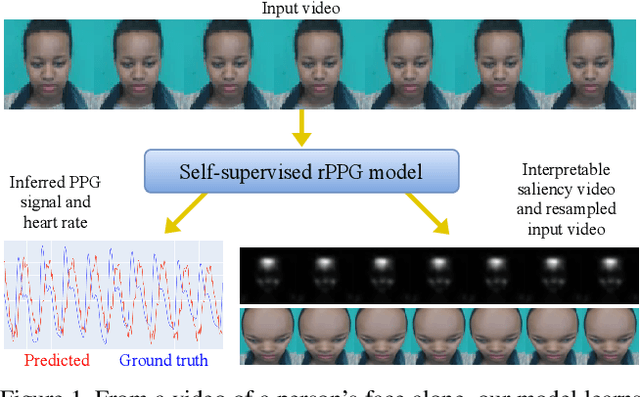

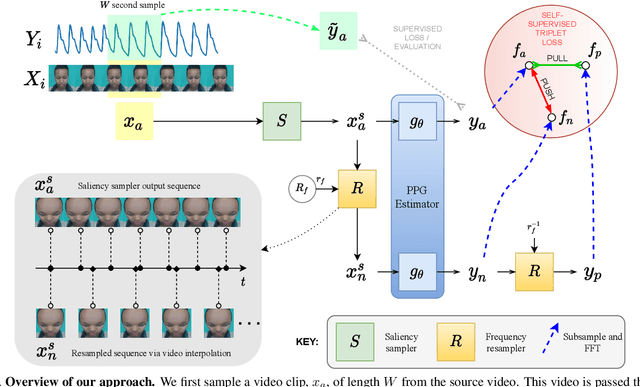
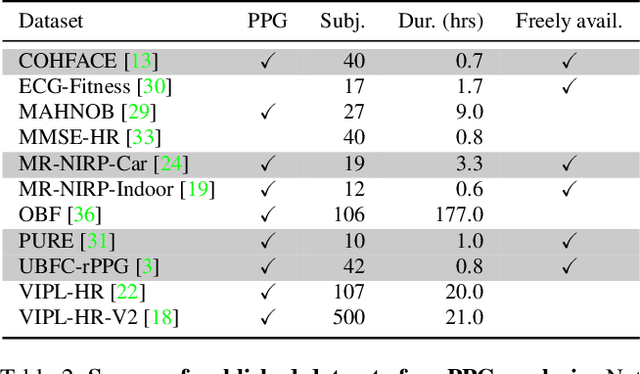
The ability to reliably estimate physiological signals from video is a powerful tool in low-cost, pre-clinical health monitoring. In this work we propose a new approach to remote photoplethysmography (rPPG) - the measurement of blood volume changes from observations of a person's face or skin. Similar to current state-of-the-art methods for rPPG, we apply neural networks to learn deep representations with invariance to nuisance image variation. In contrast to such methods, we employ a fully self-supervised training approach, which has no reliance on expensive ground truth physiological training data. Our proposed method uses contrastive learning with a weak prior over the frequency and temporal smoothness of the target signal of interest. We evaluate our approach on four rPPG datasets, showing that comparable or better results can be achieved compared to recent supervised deep learning methods but without using any annotation. In addition, we incorporate a learned saliency resampling module into both our unsupervised approach and supervised baseline. We show that by allowing the model to learn where to sample the input image, we can reduce the need for hand-engineered features while providing some interpretability into the model's behavior and possible failure modes. We release code for our complete training and evaluation pipeline to encourage reproducible progress in this exciting new direction.
* Code available at https://github.com/ToyotaResearchInstitute/RemotePPG
MAAD: A Model and Dataset for "Attended Awareness" in Driving
Oct 16, 2021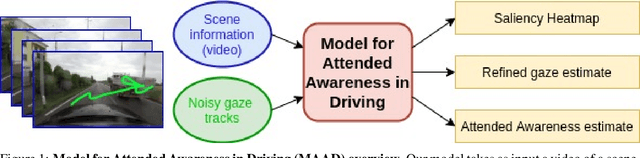
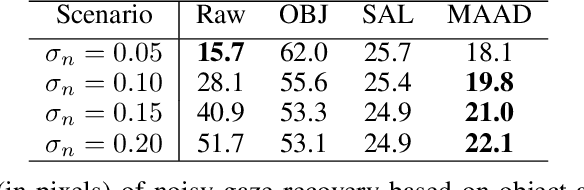
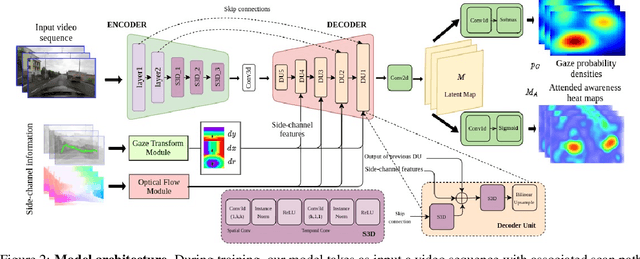

We propose a computational model to estimate a person's attended awareness of their environment. We define attended awareness to be those parts of a potentially dynamic scene which a person has attended to in recent history and which they are still likely to be physically aware of. Our model takes as input scene information in the form of a video and noisy gaze estimates, and outputs visual saliency, a refined gaze estimate, and an estimate of the person's attended awareness. In order to test our model, we capture a new dataset with a high-precision gaze tracker including 24.5 hours of gaze sequences from 23 subjects attending to videos of driving scenes. The dataset also contains third-party annotations of the subjects' attended awareness based on observations of their scan path. Our results show that our model is able to reasonably estimate attended awareness in a controlled setting, and in the future could potentially be extended to real egocentric driving data to help enable more effective ahead-of-time warnings in safety systems and thereby augment driver performance. We also demonstrate our model's effectiveness on the tasks of saliency, gaze calibration, and denoising, using both our dataset and an existing saliency dataset. We make our model and dataset available at https://github.com/ToyotaResearchInstitute/att-aware/.
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
Aug 26, 2021
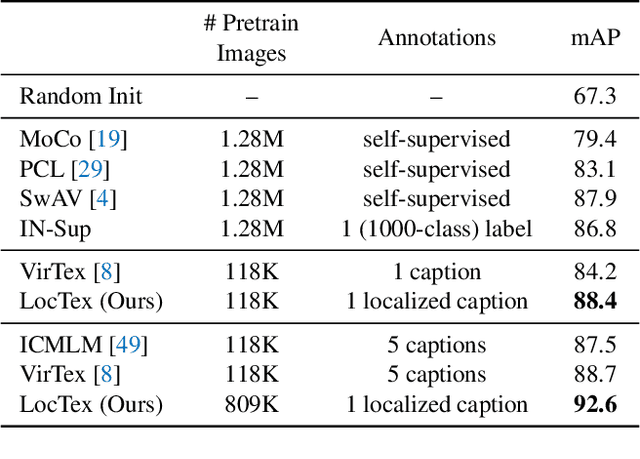
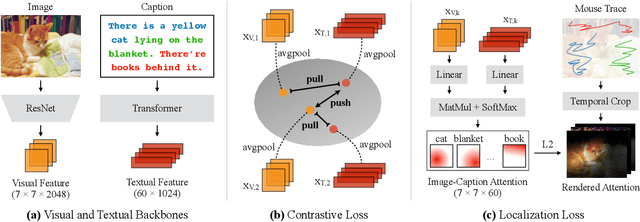
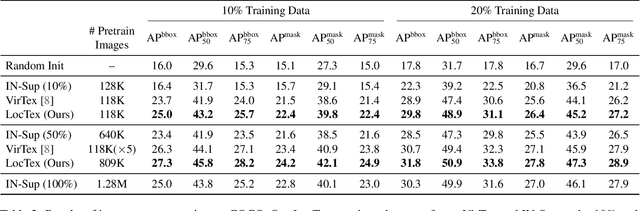
Computer vision tasks such as object detection and semantic/instance segmentation rely on the painstaking annotation of large training datasets. In this paper, we propose LocTex that takes advantage of the low-cost localized textual annotations (i.e., captions and synchronized mouse-over gestures) to reduce the annotation effort. We introduce a contrastive pre-training framework between images and captions and propose to supervise the cross-modal attention map with rendered mouse traces to provide coarse localization signals. Our learned visual features capture rich semantics (from free-form captions) and accurate localization (from mouse traces), which are very effective when transferred to various downstream vision tasks. Compared with ImageNet supervised pre-training, LocTex can reduce the size of the pre-training dataset by 10x or the target dataset by 2x while achieving comparable or even improved performance on COCO instance segmentation. When provided with the same amount of annotations, LocTex achieves around 4% higher accuracy than the previous state-of-the-art "vision+language" pre-training approach on the task of PASCAL VOC image classification.
Gaze360: Physically Unconstrained Gaze Estimation in the Wild
Oct 22, 2019
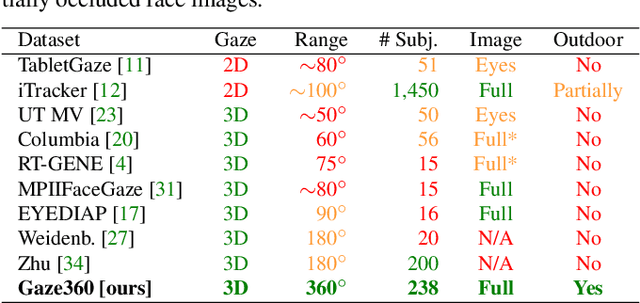

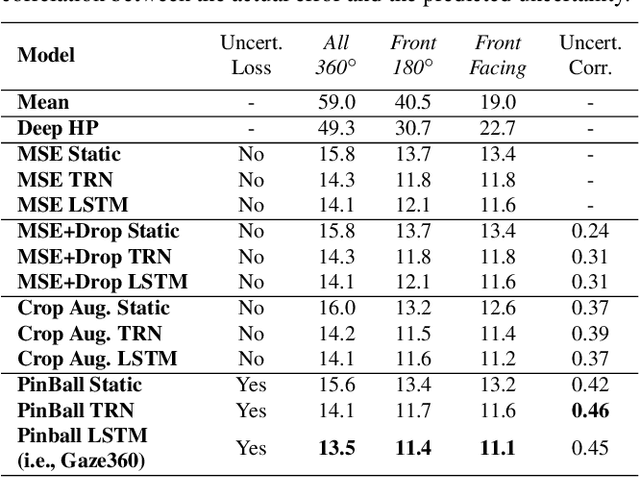
Understanding where people are looking is an informative social cue. In this work, we present Gaze360, a large-scale gaze-tracking dataset and method for robust 3D gaze estimation in unconstrained images. Our dataset consists of 238 subjects in indoor and outdoor environments with labelled 3D gaze across a wide range of head poses and distances. It is the largest publicly available dataset of its kind by both subject and variety, made possible by a simple and efficient collection method. Our proposed 3D gaze model extends existing models to include temporal information and to directly output an estimate of gaze uncertainty. We demonstrate the benefits of our model via an ablation study, and show its generalization performance via a cross-dataset evaluation against other recent gaze benchmark datasets. We furthermore propose a simple self-supervised approach to improve cross-dataset domain adaptation. Finally, we demonstrate an application of our model for estimating customer attention in a supermarket setting. Our dataset and models are available at http://gaze360.csail.mit.edu .