 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionDreamer: Zero-Shot 3D Mesh Animation from Video Diffusion Models
May 30, 2024



Animation techniques bring digital 3D worlds and characters to life. However, manual animation is tedious and automated techniques are often specialized to narrow shape classes. In our work, we propose a technique for automatic re-animation of arbitrary 3D shapes based on a motion prior extracted from a video diffusion model. Unlike existing 4D generation methods, we focus solely on the motion, and we leverage an explicit mesh-based representation compatible with existing computer-graphics pipelines. Furthermore, our utilization of diffusion features enhances accuracy of our motion fitting. We analyze efficacy of these features for animation fitting and we experimentally validate our approach for two different diffusion models and four animation models. Finally, we demonstrate that our time-efficient zero-shot method achieves a superior performance re-animating a diverse set of 3D shapes when compared to existing techniques in a user study. The project website is located at https://lukas.uzolas.com/MotionDreamer.
Template-free Articulated Neural Point Clouds for Reposable View Synthesis
May 30, 2023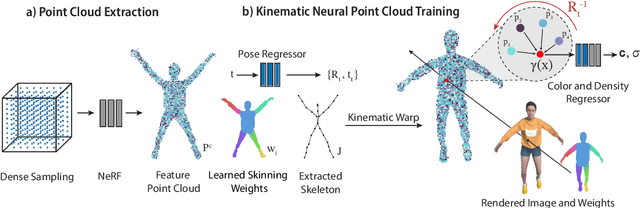


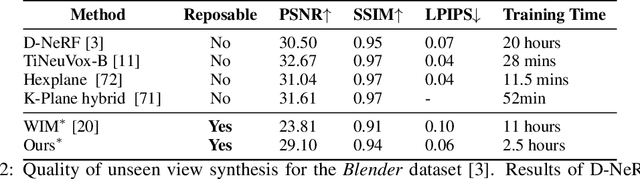
Dynamic Neural Radiance Fields (NeRFs) achieve remarkable visual quality when synthesizing novel views of time-evolving 3D scenes. However, the common reliance on backward deformation fields makes reanimation of the captured object poses challenging. Moreover, the state of the art dynamic models are often limited by low visual fidelity, long reconstruction time or specificity to narrow application domains. In this paper, we present a novel method utilizing a point-based representation and Linear Blend Skinning (LBS) to jointly learn a Dynamic NeRF and an associated skeletal model from even sparse multi-view video. Our forward-warping approach achieves state-of-the-art visual fidelity when synthesizing novel views and poses while significantly reducing the necessary learning time when compared to existing work. We demonstrate the versatility of our representation on a variety of articulated objects from common datasets and obtain reposable 3D reconstructions without the need of object-specific skeletal templates. Code will be made available at https://github.com/lukasuz/Articulated-Point-NeRF.
Towards Attention-aware Rendering for Virtual and Augmented Reality
Feb 02, 2023


Foveated graphics is a promising approach to solving the bandwidth challenges of immersive virtual and augmented reality displays by exploiting the falloff in spatial acuity in the periphery of the visual field. However, the perceptual models used in these applications neglect the effects of higher-level cognitive processing, namely the allocation of visual attention, and are thus overestimating sensitivity in the periphery in many scenarios. Here, we introduce the first attention-aware model of contrast sensitivity. We conduct user studies to measure contrast sensitivity under different attention distributions and show that sensitivity in the periphery drops significantly when the user is required to allocate attention to the fovea. We motivate the development of future foveation models with another user study and demonstrate that tolerance for foveation in the periphery is significantly higher when the user is concentrating on a task in the fovea. Analysis of our model predicts potential bandwidth savings over 9 times higher than those afforded by current models. As such, our work forms the foundation for attention-aware foveated graphics techniques.
Generative Neural Articulated Radiance Fields
Jun 28, 2022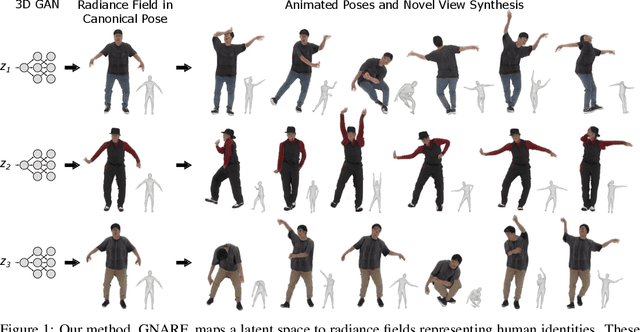
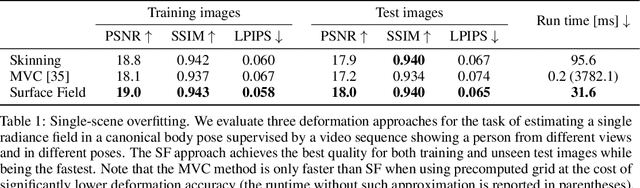
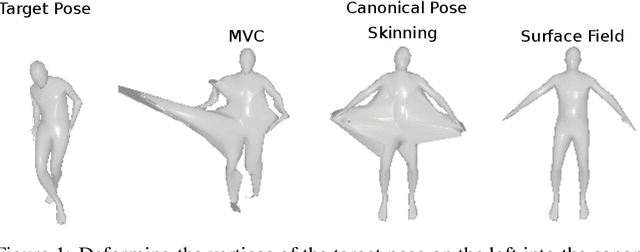
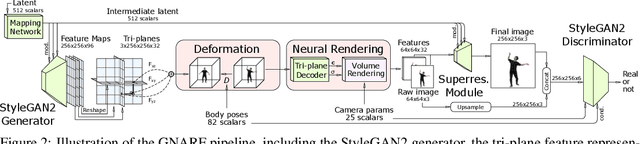
Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations.
Fast Training of Neural Lumigraph Representations using Meta Learning
Jun 28, 2021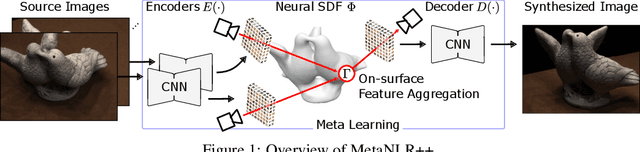


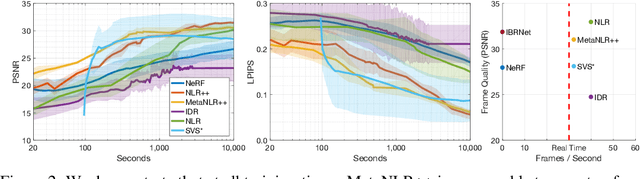
Novel view synthesis is a long-standing problem in machine learning and computer vision. Significant progress has recently been made in developing neural scene representations and rendering techniques that synthesize photorealistic images from arbitrary views. These representations, however, are extremely slow to train and often also slow to render. Inspired by neural variants of image-based rendering, we develop a new neural rendering approach with the goal of quickly learning a high-quality representation which can also be rendered in real-time. Our approach, MetaNLR++, accomplishes this by using a unique combination of a neural shape representation and 2D CNN-based image feature extraction, aggregation, and re-projection. To push representation convergence times down to minutes, we leverage meta learning to learn neural shape and image feature priors which accelerate training. The optimized shape and image features can then be extracted using traditional graphics techniques and rendered in real time. We show that MetaNLR++ achieves similar or better novel view synthesis results in a fraction of the time that competing methods require.
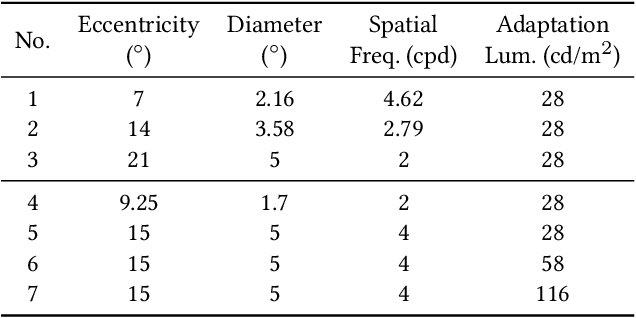
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 26, 2021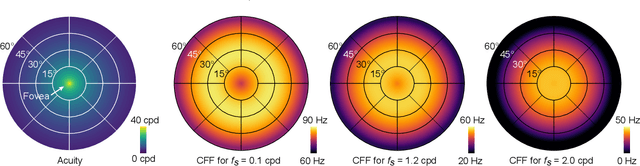
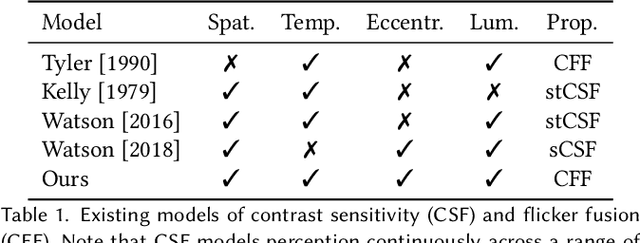

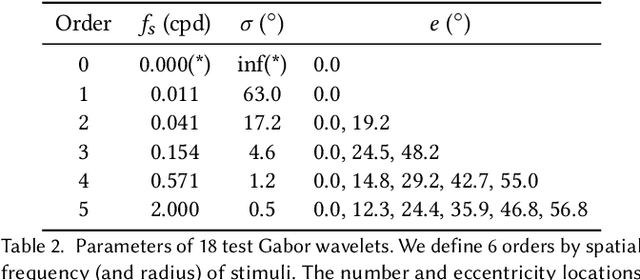
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Neural Lumigraph Rendering
Mar 22, 2021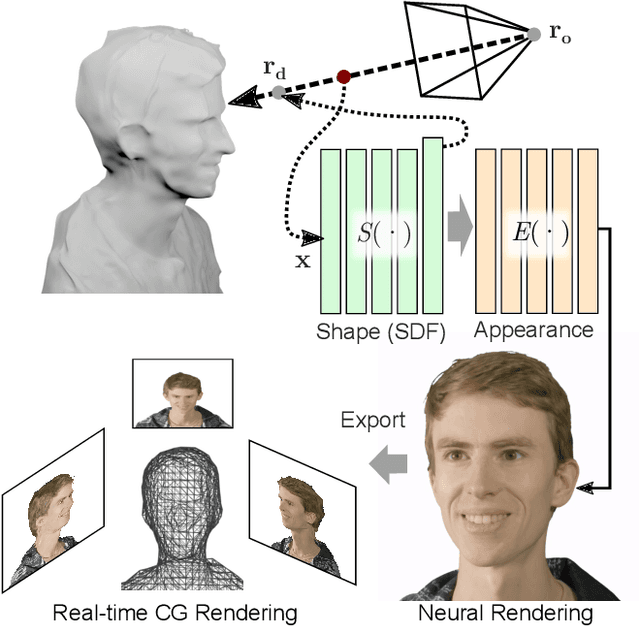


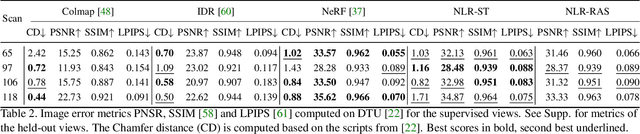
Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
Dec 02, 2020

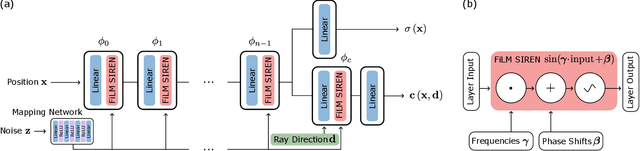

We have witnessed rapid progress on 3D-aware image synthesis, leveraging recent advances in generative visual models and neural rendering. Existing approaches however fall short in two ways: first, they may lack an underlying 3D representation or rely on view-inconsistent rendering, hence synthesizing images that are not multi-view consistent; second, they often depend upon representation network architectures that are not expressive enough, and their results thus lack in image quality. We propose a novel generative model, named Periodic Implicit Generative Adversarial Networks ($\pi$-GAN or pi-GAN), for high-quality 3D-aware image synthesis. $\pi$-GAN leverages neural representations with periodic activation functions and volumetric rendering to represent scenes as view-consistent 3D representations with fine detail. The proposed approach obtains state-of-the-art results for 3D-aware image synthesis with multiple real and synthetic datasets.
Gaze360: Physically Unconstrained Gaze Estimation in the Wild
Oct 22, 2019
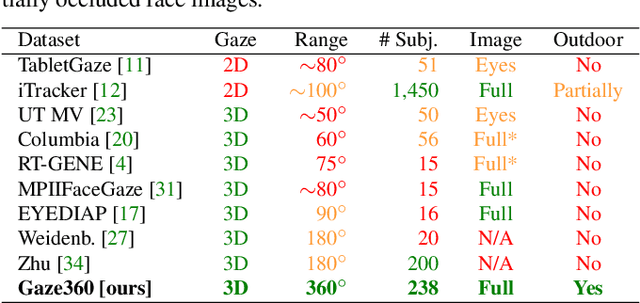

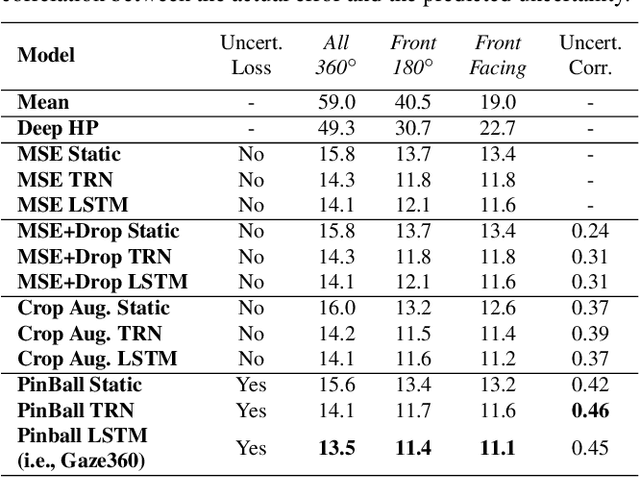
Understanding where people are looking is an informative social cue. In this work, we present Gaze360, a large-scale gaze-tracking dataset and method for robust 3D gaze estimation in unconstrained images. Our dataset consists of 238 subjects in indoor and outdoor environments with labelled 3D gaze across a wide range of head poses and distances. It is the largest publicly available dataset of its kind by both subject and variety, made possible by a simple and efficient collection method. Our proposed 3D gaze model extends existing models to include temporal information and to directly output an estimate of gaze uncertainty. We demonstrate the benefits of our model via an ablation study, and show its generalization performance via a cross-dataset evaluation against other recent gaze benchmark datasets. We furthermore propose a simple self-supervised approach to improve cross-dataset domain adaptation. Finally, we demonstrate an application of our model for estimating customer attention in a supermarket setting. Our dataset and models are available at http://gaze360.csail.mit.edu .
Neural Inverse Knitting: From Images to Manufacturing Instructions
Feb 07, 2019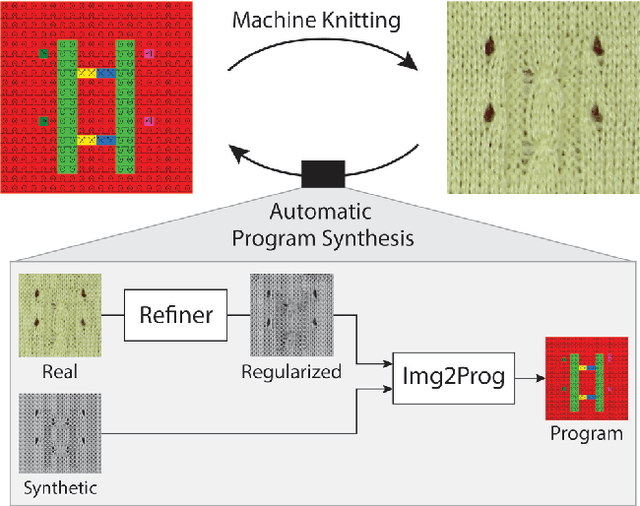
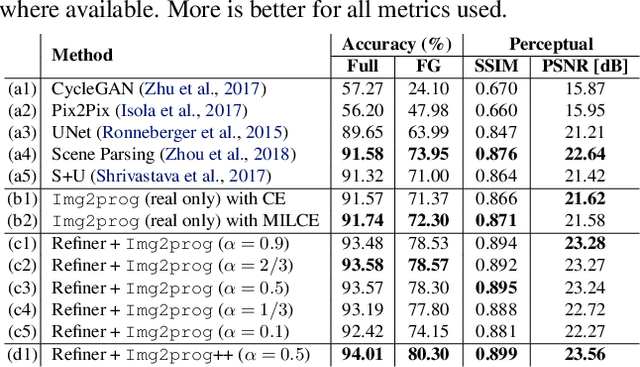
Motivated by the recent potential of mass customization brought by whole-garment knitting machines, we introduce the new problem of automatic machine instruction generation using a single image of the desired physical product, which we apply to machine knitting. We propose to tackle this problem by directly learning to synthesize regular machine instructions from real images. We create a cured dataset of real samples with their instruction counterpart and propose to use synthetic images to augment it in a novel way. We theoretically motivate our data mixing framework and show empirical results suggesting that making real images look more synthetic is beneficial in our problem setup.