 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Inverse Knitting: From Images to Manufacturing Instructions
Feb 07, 2019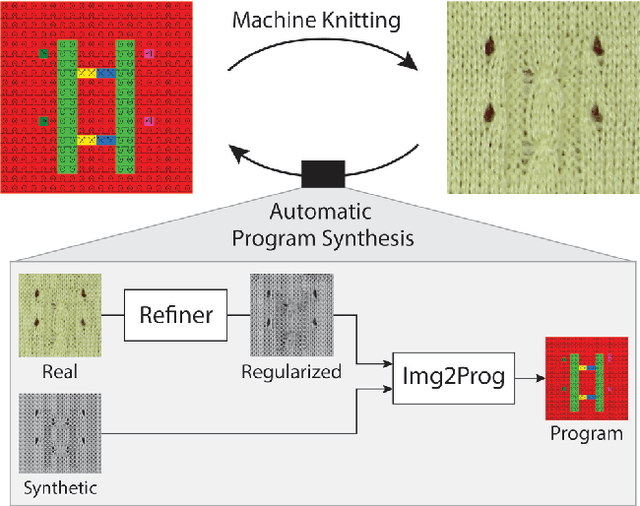
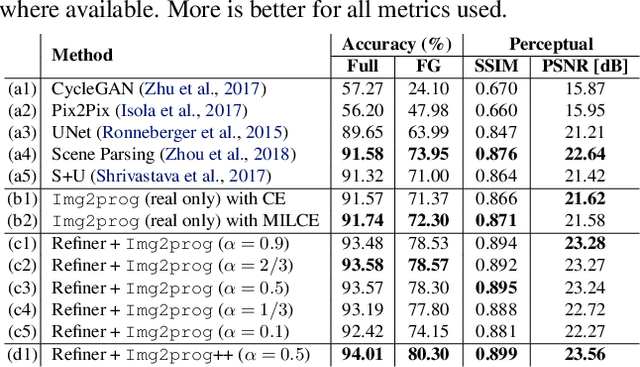
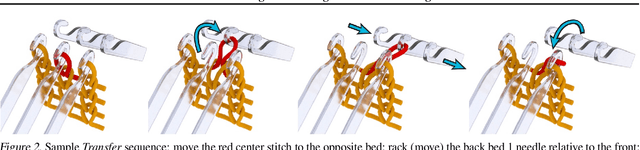
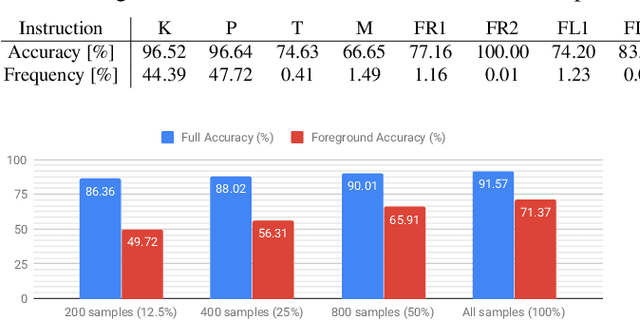
Motivated by the recent potential of mass customization brought by whole-garment knitting machines, we introduce the new problem of automatic machine instruction generation using a single image of the desired physical product, which we apply to machine knitting. We propose to tackle this problem by directly learning to synthesize regular machine instructions from real images. We create a cured dataset of real samples with their instruction counterpart and propose to use synthetic images to augment it in a novel way. We theoretically motivate our data mixing framework and show empirical results suggesting that making real images look more synthetic is beneficial in our problem setup.
On Learning Associations of Faces and Voices
Nov 02, 2018
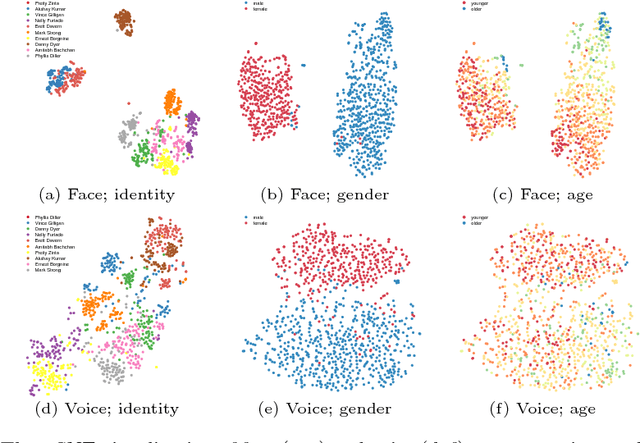


In this paper, we study the associations between human faces and voices. Audiovisual integration, specifically the integration of facial and vocal information is a well-researched area in neuroscience. It is shown that the overlapping information between the two modalities plays a significant role in perceptual tasks such as speaker identification. Through an online study on a new dataset we created, we confirm previous findings that people can associate unseen faces with corresponding voices and vice versa with greater than chance accuracy. We computationally model the overlapping information between faces and voices and show that the learned cross-modal representation contains enough information to identify matching faces and voices with performance similar to that of humans. Our representation exhibits correlations to certain demographic attributes and features obtained from either visual or aural modality alone. We release our dataset of audiovisual recordings and demographic annotations of people reading out short text used in our studies.