 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
Neural Modular Physics for Elastic Simulation
Dec 17, 2025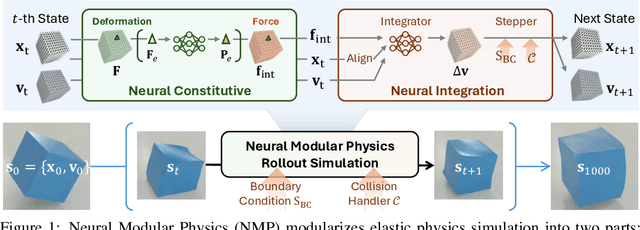
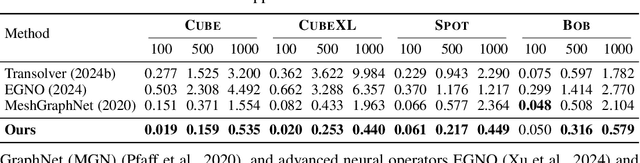
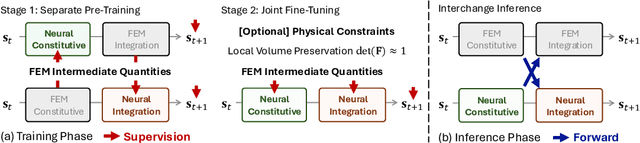
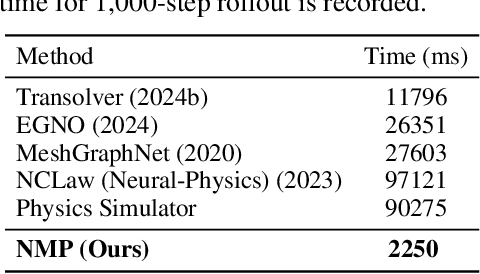
Learning-based methods have made significant progress in physics simulation, typically approximating dynamics with a monolithic end-to-end optimized neural network. Although these models offer an effective way to simulation, they may lose essential features compared to traditional numerical simulators, such as physical interpretability and reliability. Drawing inspiration from classical simulators that operate in a modular fashion, this paper presents Neural Modular Physics (NMP) for elastic simulation, which combines the approximation capacity of neural networks with the physical reliability of traditional simulators. Beyond the previous monolithic learning paradigm, NMP enables direct supervision of intermediate quantities and physical constraints by decomposing elastic dynamics into physically meaningful neural modules connected through intermediate physical quantities. With a specialized architecture and training strategy, our method transforms the numerical computation flow into a modular neural simulator, achieving improved physical consistency and generalizability. Experimentally, NMP demonstrates superior generalization to unseen initial conditions and resolutions, stable long-horizon simulation, better preservation of physical properties compared to other neural simulators, and greater feasibility in scenarios with unknown underlying dynamics than traditional simulators.
Protein Structure Tokenization via Geometric Byte Pair Encoding
Nov 13, 2025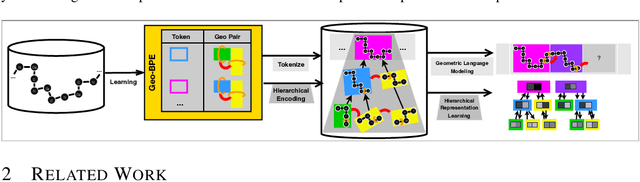
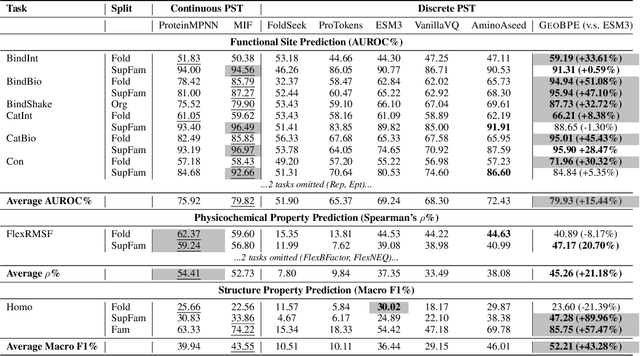
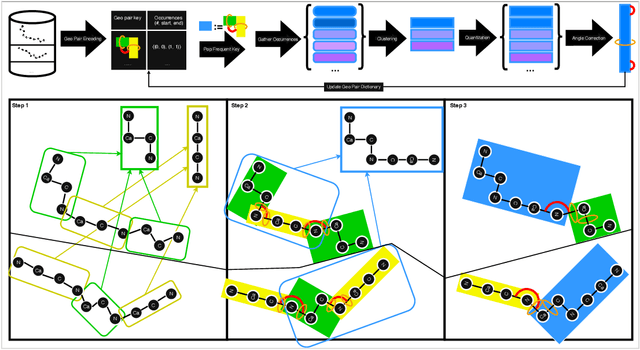

Protein structure is central to biological function, and enabling multimodal protein models requires joint reasoning over sequence, structure, and function. A key barrier is the lack of principled protein structure tokenizers (PSTs): existing approaches fix token size or rely on continuous vector codebooks, limiting interpretability, multi-scale control, and transfer across architectures. We introduce GeoBPE, a geometry-grounded PST that transforms continuous, noisy, multi-scale backbone conformations into discrete ``sentences'' of geometry while enforcing global constraints. Analogous to byte-pair encoding, GeoBPE generates a hierarchical vocabulary of geometric primitives by iteratively (i) clustering Geo-Pair occurrences with k-medoids to yield a resolution-controllable vocabulary; (ii) quantizing each Geo-Pair to its closest medoid prototype; and (iii) reducing drift through differentiable inverse kinematics that optimizes boundary glue angles under an $\mathrm{SE}(3)$ end-frame loss. GeoBPE offers compression ($>$10x reduction in bits-per-residue at similar distortion rate), data efficiency ($>$10x less training data), and generalization (maintains test/train distortion ratio of $1.0-1.1$). It is architecture-agnostic: (a) its hierarchical vocabulary provides a strong inductive bias for coarsening residue-level embeddings from large PLMs into motif- and protein-level representations, consistently outperforming leading PSTs across $12$ tasks and $24$ test splits; (b) paired with a transformer, GeoBPE supports unconditional backbone generation via language modeling; and (c) tokens align with CATH functional families and support expert-interpretable case studies, offering functional meaning absent in prior PSTs. Code is available at https://github.com/shiningsunnyday/PT-BPE/.
MetaGen: A DSL, Database, and Benchmark for VLM-Assisted Metamaterial Generation
Aug 25, 2025Metamaterials are micro-architected structures whose geometry imparts highly tunable-often counter-intuitive-bulk properties. Yet their design is difficult because of geometric complexity and a non-trivial mapping from architecture to behaviour. We address these challenges with three complementary contributions. (i) MetaDSL: a compact, semantically rich domain-specific language that captures diverse metamaterial designs in a form that is both human-readable and machine-parsable. (ii) MetaDB: a curated repository of more than 150,000 parameterized MetaDSL programs together with their derivatives-three-dimensional geometry, multi-view renderings, and simulated elastic properties. (iii) MetaBench: benchmark suites that test three core capabilities of vision-language metamaterial assistants-structure reconstruction, property-driven inverse design, and performance prediction. We establish baselines by fine-tuning state-of-the-art vision-language models and deploy an omni-model within an interactive, CAD-like interface. Case studies show that our framework provides a strong first step toward integrated design and understanding of structure-representation-property relationships.
Fabrica: Dual-Arm Assembly of General Multi-Part Objects via Integrated Planning and Learning
Jun 05, 2025Multi-part assembly poses significant challenges for robots to execute long-horizon, contact-rich manipulation with generalization across complex geometries. We present Fabrica, a dual-arm robotic system capable of end-to-end planning and control for autonomous assembly of general multi-part objects. For planning over long horizons, we develop hierarchies of precedence, sequence, grasp, and motion planning with automated fixture generation, enabling general multi-step assembly on any dual-arm robots. The planner is made efficient through a parallelizable design and is optimized for downstream control stability. For contact-rich assembly steps, we propose a lightweight reinforcement learning framework that trains generalist policies across object geometries, assembly directions, and grasp poses, guided by equivariance and residual actions obtained from the plan. These policies transfer zero-shot to the real world and achieve 80% successful steps. For systematic evaluation, we propose a benchmark suite of multi-part assemblies resembling industrial and daily objects across diverse categories and geometries. By integrating efficient global planning and robust local control, we showcase the first system to achieve complete and generalizable real-world multi-part assembly without domain knowledge or human demonstrations. Project website: http://fabrica.csail.mit.edu/
Directed Graph Grammars for Sequence-based Learning
May 29, 2025Directed acyclic graphs (DAGs) are a class of graphs commonly used in practice, with examples that include electronic circuits, Bayesian networks, and neural architectures. While many effective encoders exist for DAGs, it remains challenging to decode them in a principled manner, because the nodes of a DAG can have many different topological orders. In this work, we propose a grammar-based approach to constructing a principled, compact and equivalent sequential representation of a DAG. Specifically, we view a graph as derivations over an unambiguous grammar, where the DAG corresponds to a unique sequence of production rules. Equivalently, the procedure to construct such a description can be viewed as a lossless compression of the data. Such a representation has many uses, including building a generative model for graph generation, learning a latent space for property prediction, and leveraging the sequence representational continuity for Bayesian Optimization over structured data. Code is available at https://github.com/shiningsunnyday/induction.
Foundation Molecular Grammar: Multi-Modal Foundation Models Induce Interpretable Molecular Graph Languages
May 29, 2025Recent data-efficient molecular generation approaches exploit graph grammars to introduce interpretability into the generative models. However, grammar learning therein relies on expert annotation or unreliable heuristics for algorithmic inference. We propose Foundation Molecular Grammar (FMG), which leverages multi-modal foundation models (MMFMs) to induce an interpretable molecular language. By exploiting the chemical knowledge of an MMFM, FMG renders molecules as images, describes them as text, and aligns information across modalities using prompt learning. FMG can be used as a drop-in replacement for the prior grammar learning approaches in molecular generation and property prediction. We show that FMG not only excels in synthesizability, diversity, and data efficiency but also offers built-in chemical interpretability for automated molecular discovery workflows. Code is available at https://github.com/shiningsunnyday/induction.
FlashBias: Fast Computation of Attention with Bias
May 17, 2025Attention mechanism has emerged as a foundation module of modern deep learning models and has also empowered many milestones in various domains. Moreover, FlashAttention with IO-aware speedup resolves the efficiency issue of standard attention, further promoting its practicality. Beyond canonical attention, attention with bias also widely exists, such as relative position bias in vision and language models and pair representation bias in AlphaFold. In these works, prior knowledge is introduced as an additive bias term of attention weights to guide the learning process, which has been proven essential for model performance. Surprisingly, despite the common usage of attention with bias, its targeted efficiency optimization is still absent, which seriously hinders its wide applications in complex tasks. Diving into the computation of FlashAttention, we prove that its optimal efficiency is determined by the rank of the attention weight matrix. Inspired by this theoretical result, this paper presents FlashBias based on the low-rank compressed sensing theory, which can provide fast-exact computation for many widely used attention biases and a fast-accurate approximation for biases in general formalization. FlashBias can fully take advantage of the extremely optimized matrix multiplication operation in modern GPUs, achieving 1.5$\times$ speedup for AlphaFold, and over 2$\times$ speedup for attention with bias in vision and language models without loss of accuracy.
AI-Enhanced Automatic Design of Efficient Underwater Gliders
Apr 30, 2025The development of novel autonomous underwater gliders has been hindered by limited shape diversity, primarily due to the reliance on traditional design tools that depend heavily on manual trial and error. Building an automated design framework is challenging due to the complexities of representing glider shapes and the high computational costs associated with modeling complex solid-fluid interactions. In this work, we introduce an AI-enhanced automated computational framework designed to overcome these limitations by enabling the creation of underwater robots with non-trivial hull shapes. Our approach involves an algorithm that co-optimizes both shape and control signals, utilizing a reduced-order geometry representation and a differentiable neural-network-based fluid surrogate model. This end-to-end design workflow facilitates rapid iteration and evaluation of hydrodynamic performance, leading to the discovery of optimal and complex hull shapes across various control settings. We validate our method through wind tunnel experiments and swimming pool gliding tests, demonstrating that our computationally designed gliders surpass manually designed counterparts in terms of energy efficiency. By addressing challenges in efficient shape representation and neural fluid surrogate models, our work paves the way for the development of highly efficient underwater gliders, with implications for long-range ocean exploration and environmental monitoring.
Two-Stage Pretraining for Molecular Property Prediction in the Wild
Nov 05, 2024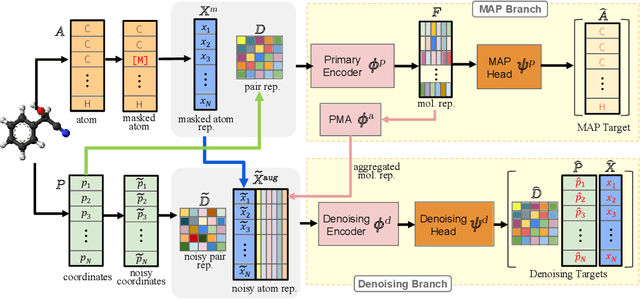

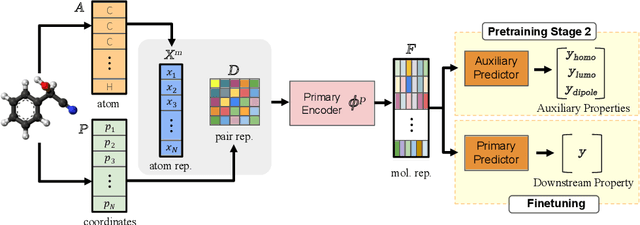
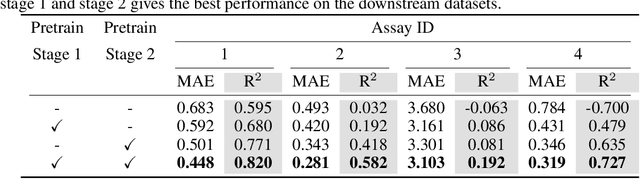
Accurate property prediction is crucial for accelerating the discovery of new molecules. Although deep learning models have achieved remarkable success, their performance often relies on large amounts of labeled data that are expensive and time-consuming to obtain. Thus, there is a growing need for models that can perform well with limited experimentally-validated data. In this work, we introduce MoleVers, a versatile pretrained model designed for various types of molecular property prediction in the wild, i.e., where experimentally-validated molecular property labels are scarce. MoleVers adopts a two-stage pretraining strategy. In the first stage, the model learns molecular representations from large unlabeled datasets via masked atom prediction and dynamic denoising, a novel task enabled by a new branching encoder architecture. In the second stage, MoleVers is further pretrained using auxiliary labels obtained with inexpensive computational methods, enabling supervised learning without the need for costly experimental data. This two-stage framework allows MoleVers to learn representations that generalize effectively across various downstream datasets. We evaluate MoleVers on a new benchmark comprising 22 molecular datasets with diverse types of properties, the majority of which contain 50 or fewer training labels reflecting real-world conditions. MoleVers achieves state-of-the-art results on 20 out of the 22 datasets, and ranks second among the remaining two, highlighting its ability to bridge the gap between data-hungry models and real-world conditions where practically-useful labels are scarce.