 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Pretraining for Molecular Property Prediction in the Wild
Paper and Code
Nov 05, 2024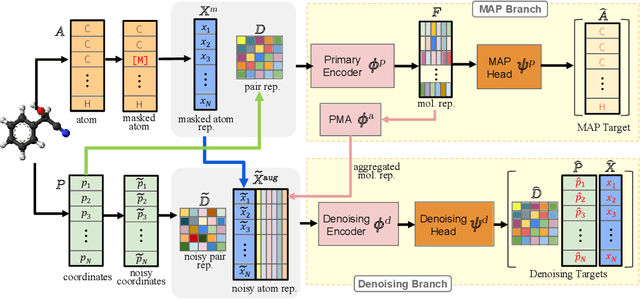

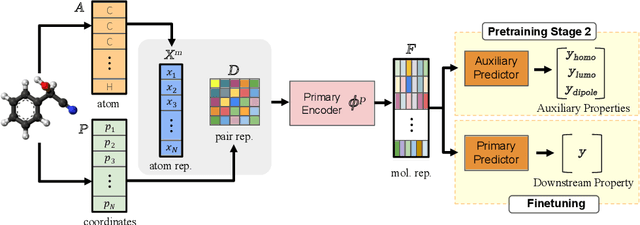
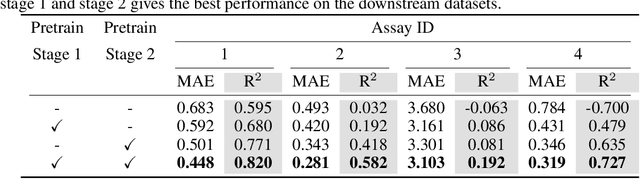
Accurate property prediction is crucial for accelerating the discovery of new molecules. Although deep learning models have achieved remarkable success, their performance often relies on large amounts of labeled data that are expensive and time-consuming to obtain. Thus, there is a growing need for models that can perform well with limited experimentally-validated data. In this work, we introduce MoleVers, a versatile pretrained model designed for various types of molecular property prediction in the wild, i.e., where experimentally-validated molecular property labels are scarce. MoleVers adopts a two-stage pretraining strategy. In the first stage, the model learns molecular representations from large unlabeled datasets via masked atom prediction and dynamic denoising, a novel task enabled by a new branching encoder architecture. In the second stage, MoleVers is further pretrained using auxiliary labels obtained with inexpensive computational methods, enabling supervised learning without the need for costly experimental data. This two-stage framework allows MoleVers to learn representations that generalize effectively across various downstream datasets. We evaluate MoleVers on a new benchmark comprising 22 molecular datasets with diverse types of properties, the majority of which contain 50 or fewer training labels reflecting real-world conditions. MoleVers achieves state-of-the-art results on 20 out of the 22 datasets, and ranks second among the remaining two, highlighting its ability to bridge the gap between data-hungry models and real-world conditions where practically-useful labels are scarce.