 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Structure Tokenization via Geometric Byte Pair Encoding
Nov 13, 2025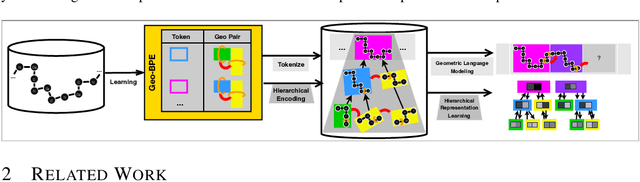
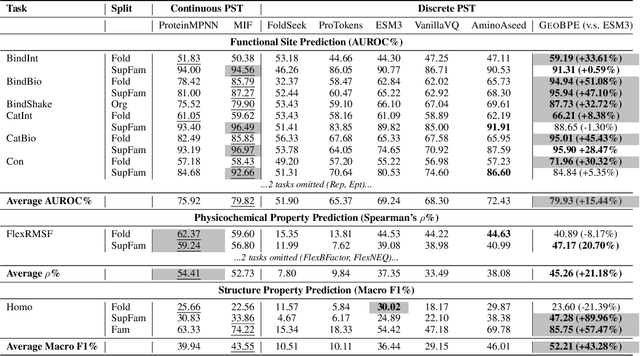
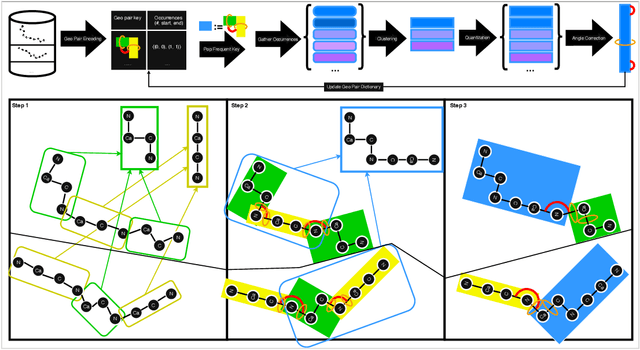

Protein structure is central to biological function, and enabling multimodal protein models requires joint reasoning over sequence, structure, and function. A key barrier is the lack of principled protein structure tokenizers (PSTs): existing approaches fix token size or rely on continuous vector codebooks, limiting interpretability, multi-scale control, and transfer across architectures. We introduce GeoBPE, a geometry-grounded PST that transforms continuous, noisy, multi-scale backbone conformations into discrete ``sentences'' of geometry while enforcing global constraints. Analogous to byte-pair encoding, GeoBPE generates a hierarchical vocabulary of geometric primitives by iteratively (i) clustering Geo-Pair occurrences with k-medoids to yield a resolution-controllable vocabulary; (ii) quantizing each Geo-Pair to its closest medoid prototype; and (iii) reducing drift through differentiable inverse kinematics that optimizes boundary glue angles under an $\mathrm{SE}(3)$ end-frame loss. GeoBPE offers compression ($>$10x reduction in bits-per-residue at similar distortion rate), data efficiency ($>$10x less training data), and generalization (maintains test/train distortion ratio of $1.0-1.1$). It is architecture-agnostic: (a) its hierarchical vocabulary provides a strong inductive bias for coarsening residue-level embeddings from large PLMs into motif- and protein-level representations, consistently outperforming leading PSTs across $12$ tasks and $24$ test splits; (b) paired with a transformer, GeoBPE supports unconditional backbone generation via language modeling; and (c) tokens align with CATH functional families and support expert-interpretable case studies, offering functional meaning absent in prior PSTs. Code is available at https://github.com/shiningsunnyday/PT-BPE/.
DischargeSim: A Simulation Benchmark for Educational Doctor-Patient Communication at Discharge
Sep 10, 2025Discharge communication is a critical yet underexplored component of patient care, where the goal shifts from diagnosis to education. While recent large language model (LLM) benchmarks emphasize in-visit diagnostic reasoning, they fail to evaluate models' ability to support patients after the visit. We introduce DischargeSim, a novel benchmark that evaluates LLMs on their ability to act as personalized discharge educators. DischargeSim simulates post-visit, multi-turn conversations between LLM-driven DoctorAgents and PatientAgents with diverse psychosocial profiles (e.g., health literacy, education, emotion). Interactions are structured across six clinically grounded discharge topics and assessed along three axes: (1) dialogue quality via automatic and LLM-as-judge evaluation, (2) personalized document generation including free-text summaries and structured AHRQ checklists, and (3) patient comprehension through a downstream multiple-choice exam. Experiments across 18 LLMs reveal significant gaps in discharge education capability, with performance varying widely across patient profiles. Notably, model size does not always yield better education outcomes, highlighting trade-offs in strategy use and content prioritization. DischargeSim offers a first step toward benchmarking LLMs in post-visit clinical education and promoting equitable, personalized patient support.
Foundation Molecular Grammar: Multi-Modal Foundation Models Induce Interpretable Molecular Graph Languages
May 29, 2025Recent data-efficient molecular generation approaches exploit graph grammars to introduce interpretability into the generative models. However, grammar learning therein relies on expert annotation or unreliable heuristics for algorithmic inference. We propose Foundation Molecular Grammar (FMG), which leverages multi-modal foundation models (MMFMs) to induce an interpretable molecular language. By exploiting the chemical knowledge of an MMFM, FMG renders molecules as images, describes them as text, and aligns information across modalities using prompt learning. FMG can be used as a drop-in replacement for the prior grammar learning approaches in molecular generation and property prediction. We show that FMG not only excels in synthesizability, diversity, and data efficiency but also offers built-in chemical interpretability for automated molecular discovery workflows. Code is available at https://github.com/shiningsunnyday/induction.
Directed Graph Grammars for Sequence-based Learning
May 29, 2025Directed acyclic graphs (DAGs) are a class of graphs commonly used in practice, with examples that include electronic circuits, Bayesian networks, and neural architectures. While many effective encoders exist for DAGs, it remains challenging to decode them in a principled manner, because the nodes of a DAG can have many different topological orders. In this work, we propose a grammar-based approach to constructing a principled, compact and equivalent sequential representation of a DAG. Specifically, we view a graph as derivations over an unambiguous grammar, where the DAG corresponds to a unique sequence of production rules. Equivalently, the procedure to construct such a description can be viewed as a lossless compression of the data. Such a representation has many uses, including building a generative model for graph generation, learning a latent space for property prediction, and leveraging the sequence representational continuity for Bayesian Optimization over structured data. Code is available at https://github.com/shiningsunnyday/induction.
Two-Stage Pretraining for Molecular Property Prediction in the Wild
Nov 05, 2024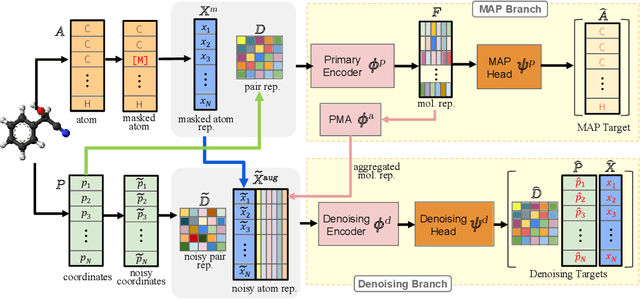

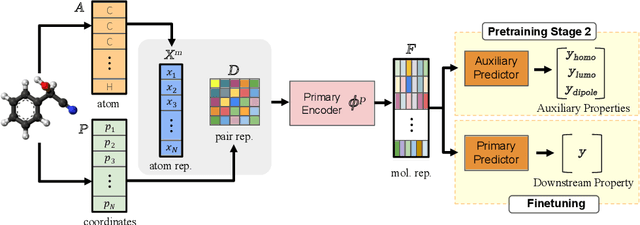
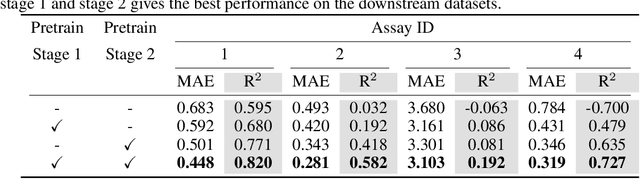
Accurate property prediction is crucial for accelerating the discovery of new molecules. Although deep learning models have achieved remarkable success, their performance often relies on large amounts of labeled data that are expensive and time-consuming to obtain. Thus, there is a growing need for models that can perform well with limited experimentally-validated data. In this work, we introduce MoleVers, a versatile pretrained model designed for various types of molecular property prediction in the wild, i.e., where experimentally-validated molecular property labels are scarce. MoleVers adopts a two-stage pretraining strategy. In the first stage, the model learns molecular representations from large unlabeled datasets via masked atom prediction and dynamic denoising, a novel task enabled by a new branching encoder architecture. In the second stage, MoleVers is further pretrained using auxiliary labels obtained with inexpensive computational methods, enabling supervised learning without the need for costly experimental data. This two-stage framework allows MoleVers to learn representations that generalize effectively across various downstream datasets. We evaluate MoleVers on a new benchmark comprising 22 molecular datasets with diverse types of properties, the majority of which contain 50 or fewer training labels reflecting real-world conditions. MoleVers achieves state-of-the-art results on 20 out of the 22 datasets, and ranks second among the remaining two, highlighting its ability to bridge the gap between data-hungry models and real-world conditions where practically-useful labels are scarce.
Multimodal Large Language Models for Inverse Molecular Design with Retrosynthetic Planning
Oct 05, 2024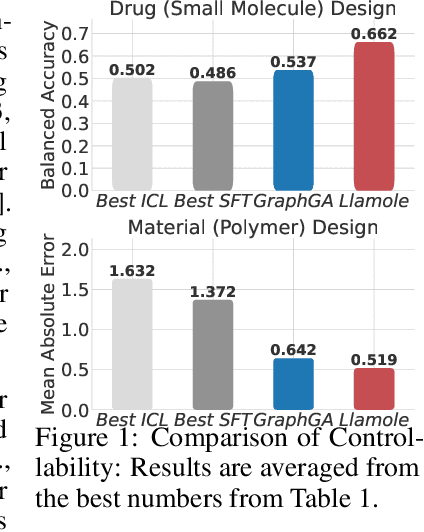
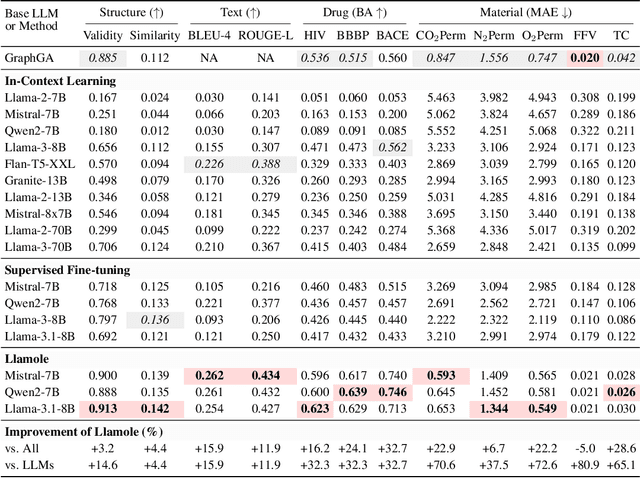
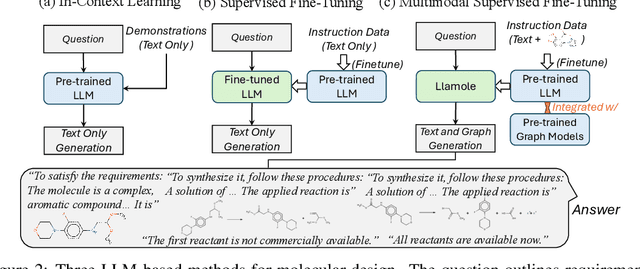
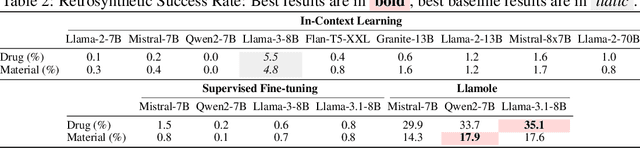
While large language models (LLMs) have integrated images, adapting them to graphs remains challenging, limiting their applications in materials and drug design. This difficulty stems from the need for coherent autoregressive generation across texts and graphs. To address this, we introduce Llamole, the first multimodal LLM capable of interleaved text and graph generation, enabling molecular inverse design with retrosynthetic planning. Llamole integrates a base LLM with the Graph Diffusion Transformer and Graph Neural Networks for multi-conditional molecular generation and reaction inference within texts, while the LLM, with enhanced molecular understanding, flexibly controls activation among the different graph modules. Additionally, Llamole integrates A* search with LLM-based cost functions for efficient retrosynthetic planning. We create benchmarking datasets and conduct extensive experiments to evaluate Llamole against in-context learning and supervised fine-tuning. Llamole significantly outperforms 14 adapted LLMs across 12 metrics for controllable molecular design and retrosynthetic planning.
Representing Molecules as Random Walks Over Interpretable Grammars
Mar 13, 2024



Recent research in molecular discovery has primarily been devoted to small, drug-like molecules, leaving many similarly important applications in material design without adequate technology. These applications often rely on more complex molecular structures with fewer examples that are carefully designed using known substructures. We propose a data-efficient and interpretable model for representing and reasoning over such molecules in terms of graph grammars that explicitly describe the hierarchical design space featuring motifs to be the design basis. We present a novel representation in the form of random walks over the design space, which facilitates both molecule generation and property prediction. We demonstrate clear advantages over existing methods in terms of performance, efficiency, and synthesizability of predicted molecules, and we provide detailed insights into the method's chemical interpretability.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
Improving Representational Continuity via Continued Pretraining
Feb 26, 2023



We consider the continual representation learning setting: sequentially pretrain a model $M'$ on tasks $T_1, \ldots, T_T$, and then adapt $M'$ on a small amount of data from each task $T_i$ to check if it has forgotten information from old tasks. Under a kNN adaptation protocol, prior work shows that continual learning methods improve forgetting over naive training (SGD). In reality, practitioners do not use kNN classifiers -- they use the adaptation method that works best (e.g., fine-tuning) -- here, we find that strong continual learning baselines do worse than naive training. Interestingly, we find that a method from the transfer learning community (LP-FT) outperforms naive training and the other continual learning methods. Even with standard kNN evaluation protocols, LP-FT performs comparably with strong continual learning methods (while being simpler and requiring less memory) on three standard benchmarks: sequential CIFAR-10, CIFAR-100, and TinyImageNet. LP-FT also reduces forgetting in a real world satellite remote sensing dataset (FMoW), and a variant of LP-FT gets state-of-the-art accuracies on an NLP continual learning benchmark.
Do Neural Networks Generalize from Self-Averaging Sub-classifiers in the Same Way As Adaptive Boosting?
Feb 14, 2023In recent years, neural networks (NNs) have made giant leaps in a wide variety of domains. NNs are often referred to as black box algorithms due to how little we can explain their empirical success. Our foundational research seeks to explain why neural networks generalize. A recent advancement derived a mutual information measure for explaining the performance of deep NNs through a sequence of increasingly complex functions. We show deep NNs learn a series of boosted classifiers whose generalization is popularly attributed to self-averaging over an increasing number of interpolating sub-classifiers. To our knowledge, we are the first authors to establish the connection between generalization in boosted classifiers and generalization in deep NNs. Our experimental evidence and theoretical analysis suggest NNs trained with dropout exhibit similar self-averaging behavior over interpolating sub-classifiers as cited in popular explanations for the post-interpolation generalization phenomenon in boosting.